[LG]《RL Is Neither a Panacea Nor a Mirage: Understanding Supervised vs. Reinforcement Learning Fine-Tuning for LLMs》H Jin, S Lv, S Wu, M Hamdaqa [PolyTechnique Montreal & Mila] (2025)
强化学习(RL)并非万能灵药,也非虚幻迷雾——它在大语言模型(LLM)微调中的作用更接近于“恢复记忆”而非创造新能力。基于《RL Is Neither a Panacea Nor a Mirage: Understanding Supervised vs. Reinforcement Learning Fine-Tuning for LLMs》一文的深入分析,关键洞察如下:
• 两阶段微调范式:先进行监督微调(SFT),再用强化学习微调(RL-FT)提升复杂推理等任务表现,成为当前主流做法。
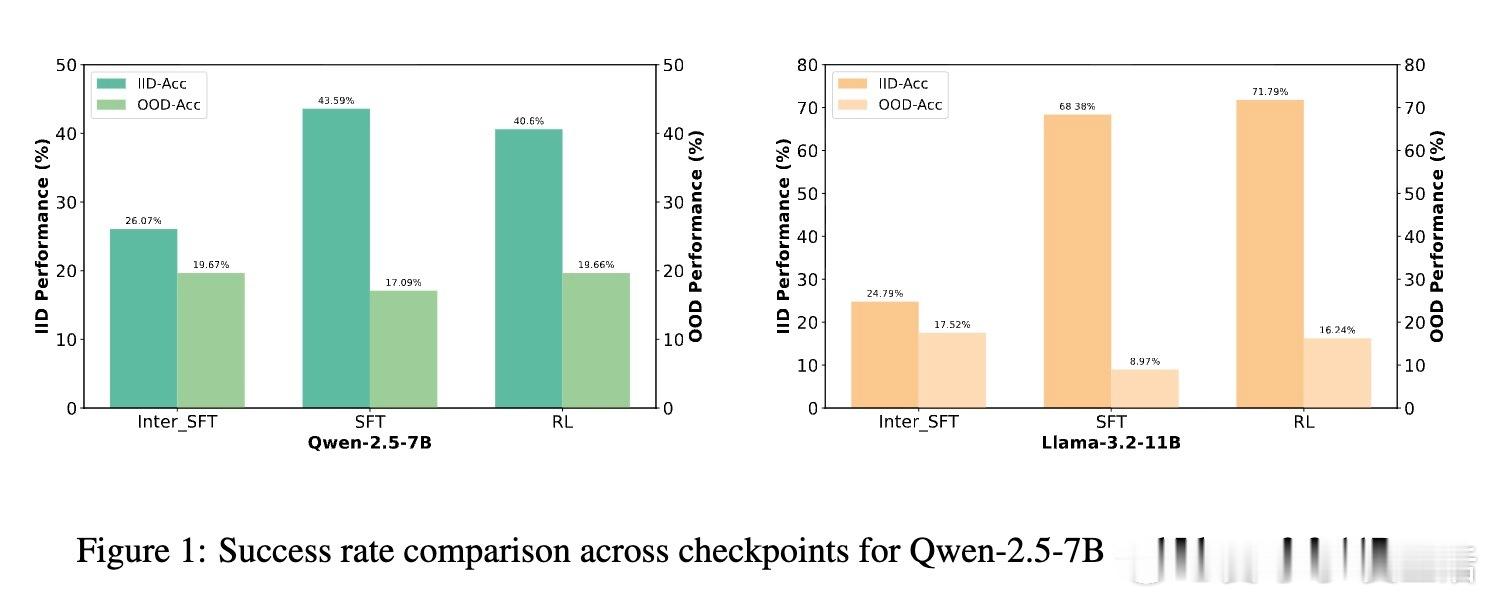
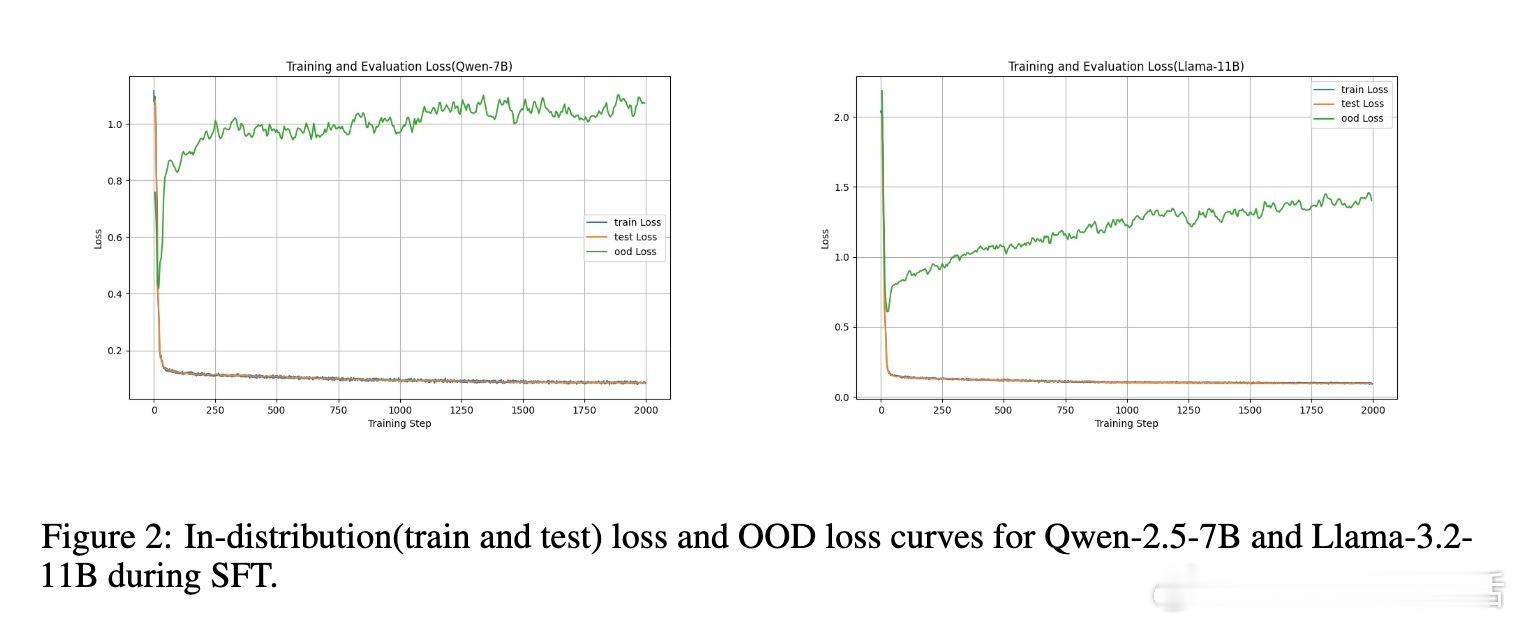
• SFT的双刃剑效应:SFT初期提升模型的OOD(分布外)泛化能力,但随着训练加深出现过拟合,导致泛化能力急剧下降,而ID(训练内分布)性能持续提升。
• RL微调的“恢复”作用:RL-FT能够显著挽回SFT导致的泛化能力损失(Qwen-7B恢复近99%,Llama-11B恢复约85%),但对严重过拟合的模型则无能为力。
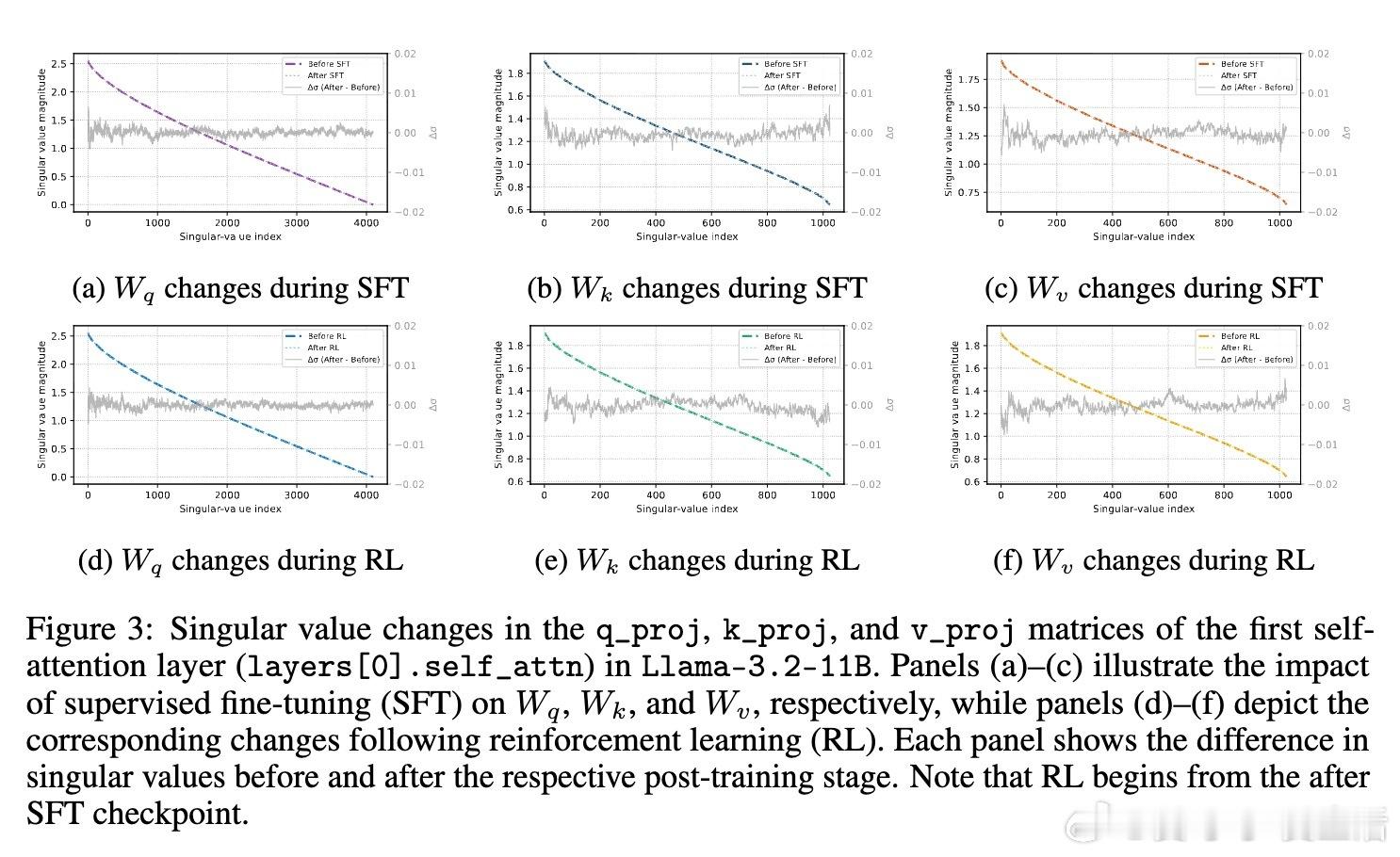
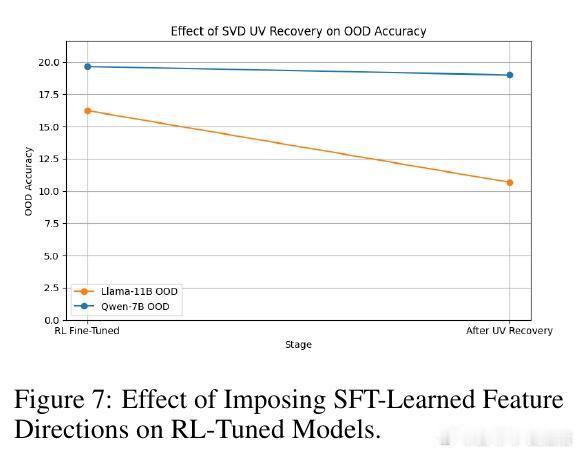
• 奇异值分解(SVD)视角:微调过程中参数矩阵的奇异值几乎不变,真正影响性能的是奇异向量方向的旋转,尤其是对应最大和最小奇异值的方向。
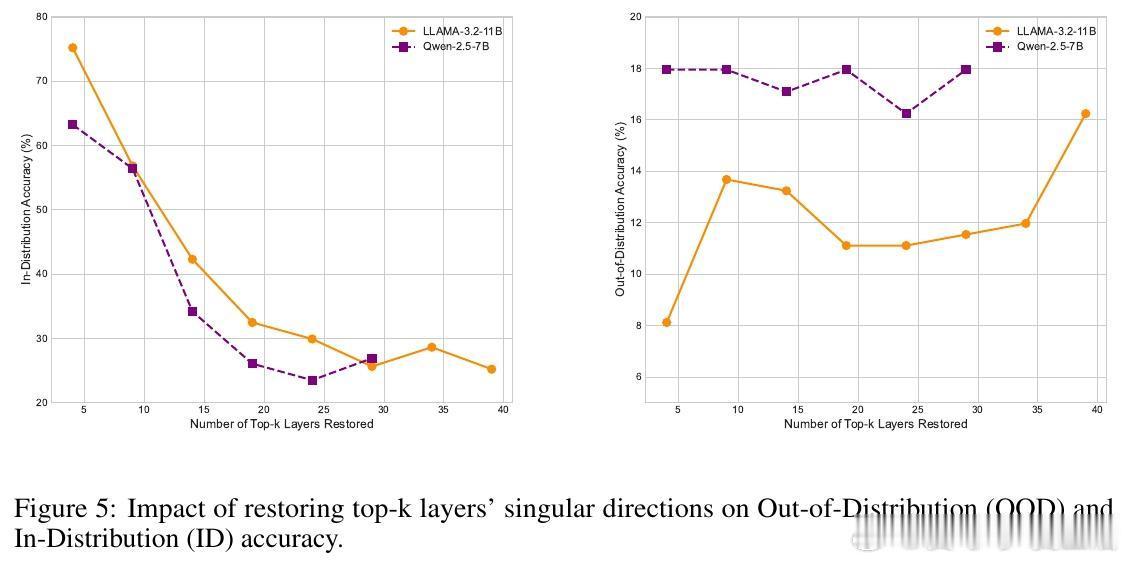
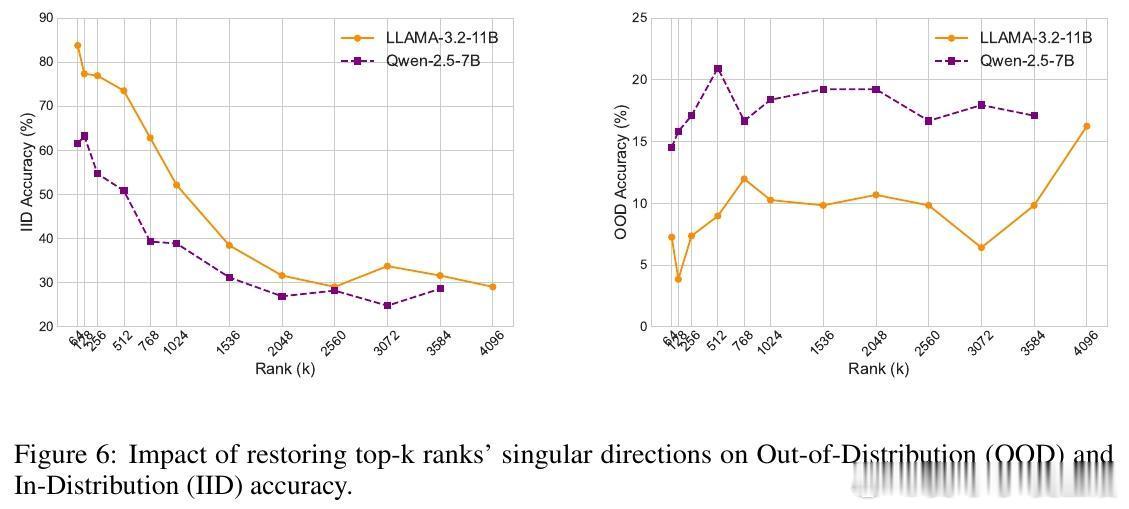
• 低秩和浅层恢复策略:仅恢复奇异向量中排名前20%的方向或前25%的层,便可恢复70%-80%的OOD性能,提示低成本的“旋转调整”即可有效缓解泛化退化。
• 方向性调整优于数值变化:优化器倾向通过旋转奇异向量实现模型调整,避免改变奇异值大小,因旋转成本更低且数值稳定。
• 层次分工明确:中间层主要承担任务专用知识,中浅层和深层则维持模型的泛化能力。恢复外层奇异向量方向更有效恢复泛化。
• RL与SFT的张力:SFT推动模型远离预训练初始状态,强化学习带有KL正则化约束,双方在优化方向上存在内在冲突。
综合来看,强化学习微调的核心价值在于对SFT引入的方向性漂移进行纠正,从而恢复模型的泛化能力,而非发掘全新功能。这种发现为业界提供了更高效的微调策略指引:在投入昂贵的RL微调前,尝试低秩UV矩阵合并及浅层权重重置,既节约计算资源,又能显著提升模型鲁棒性。
了解更多详情👉 arxiv.org/abs/2508.16546
大语言模型强化学习监督微调奇异值分解模型泛化深度学习优化