[CL]《Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search》Y Gu, Q Hu, S Yang, H Xi... [NVIDIA] (2025)
Jet-Nemotron:融合PostNAS的高效混合架构语言模型,兼具顶尖全注意力模型的准确率与显著提升的生成吞吐量。核心亮点如下:
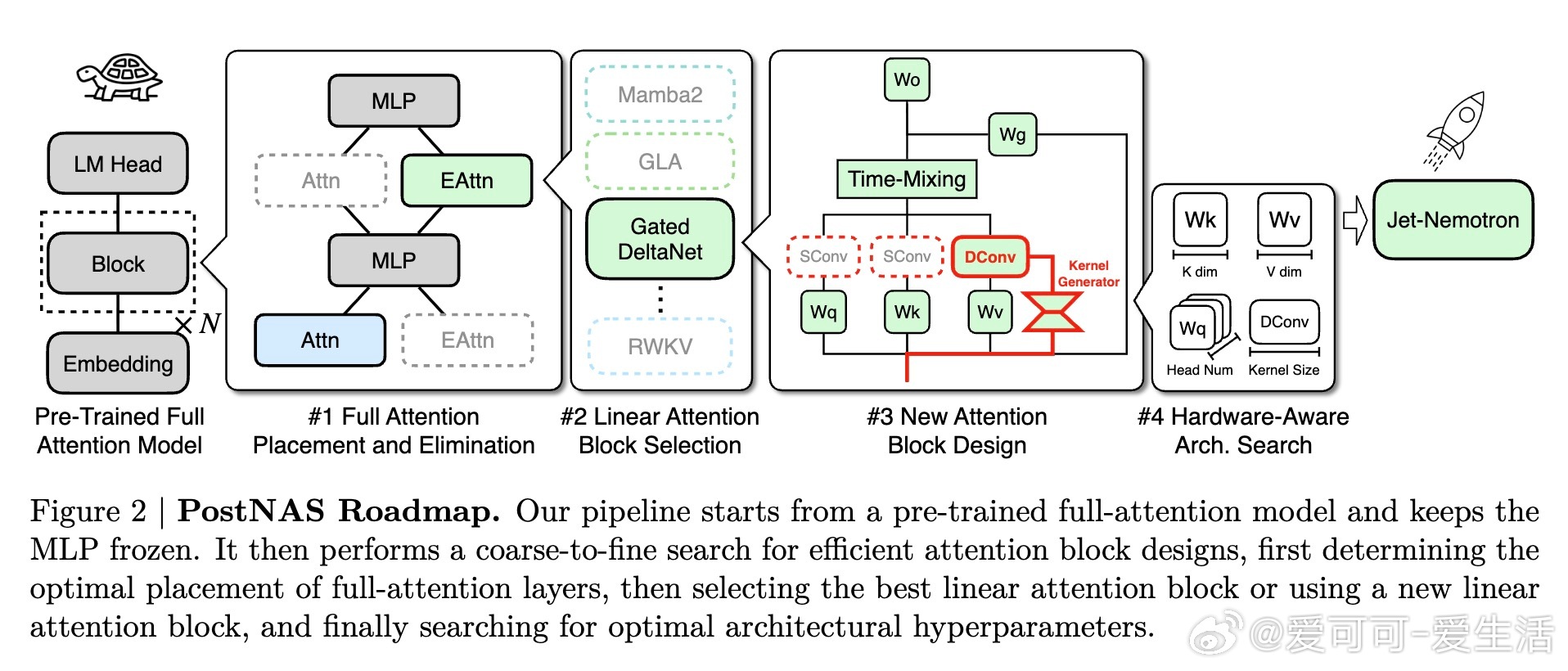
• 创新Post Neural Architecture Search(PostNAS)框架,基于预训练全注意力模型,冻结MLP权重,低成本高效探索注意力块设计,实现架构快速迭代。
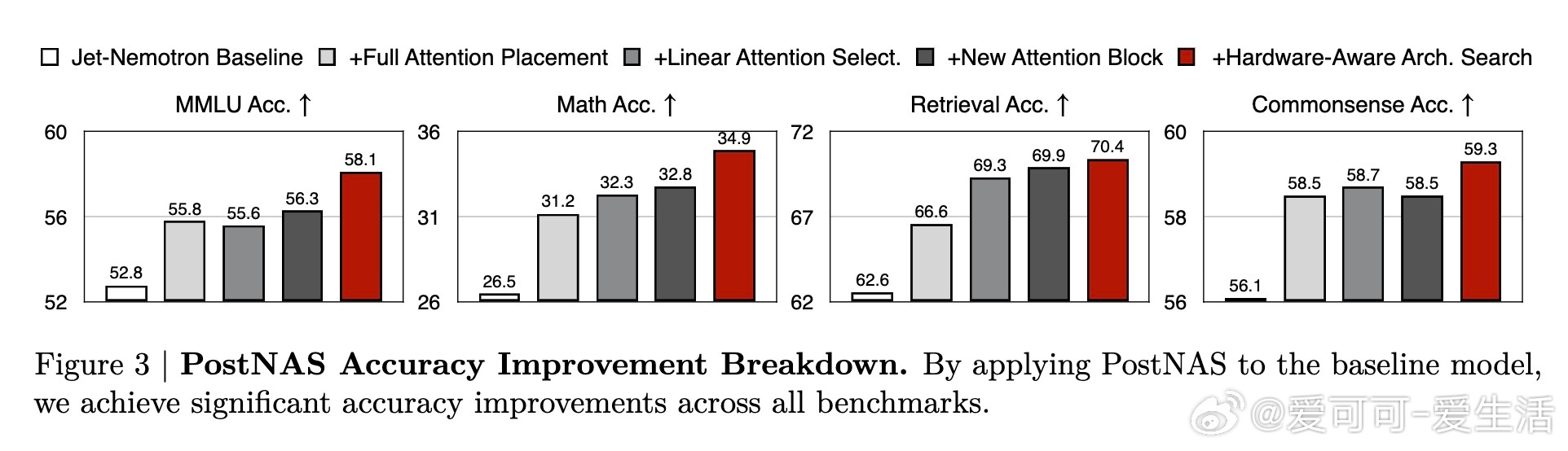
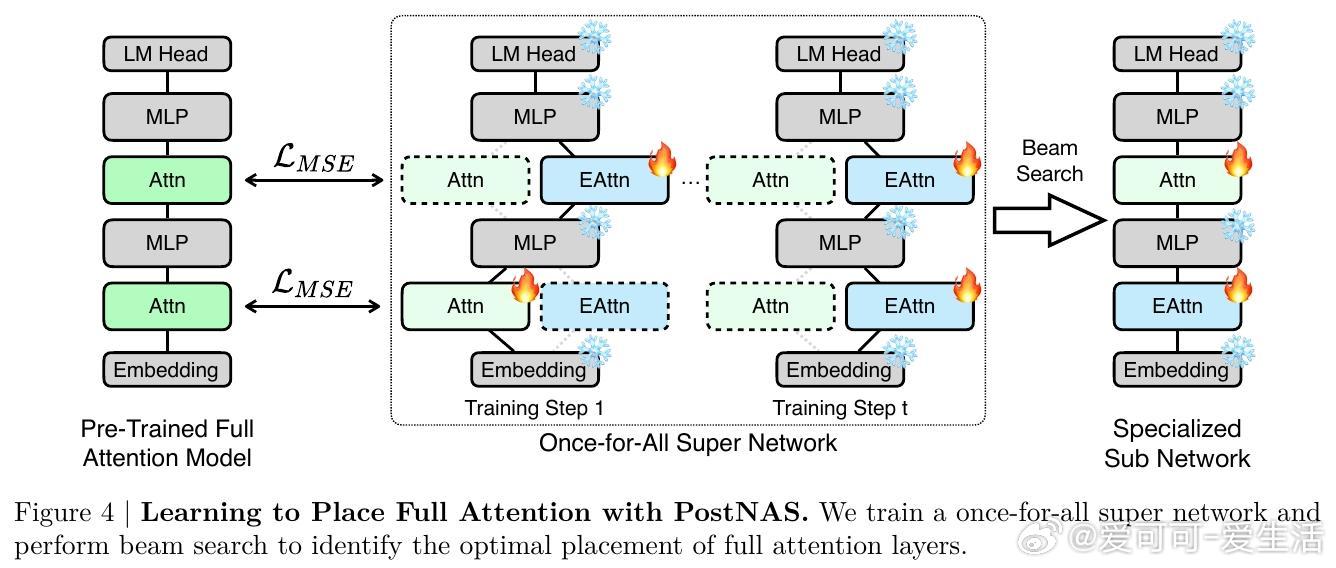
• 自动学习全注意力层的最优放置与筛选,解决传统均匀分布策略的不足,显著提升MMLU等复杂任务准确率。
• 系统选择并优化线性注意力块,评估多款SOTA设计,最终采用融合数据依赖门控和增量更新规则的Gated DeltaNet,兼顾训练效率与任务表现。
• 设计全新JetBlock线性注意力块,基于动态卷积核生成机制,提升表达能力同时减轻计算负担,准确率优于现有线性注意力方案。
• 硬件感知架构搜索,直接以生成吞吐量为优化目标,突破参数量对效率的传统限制,优化KV缓存大小成为关键因素。
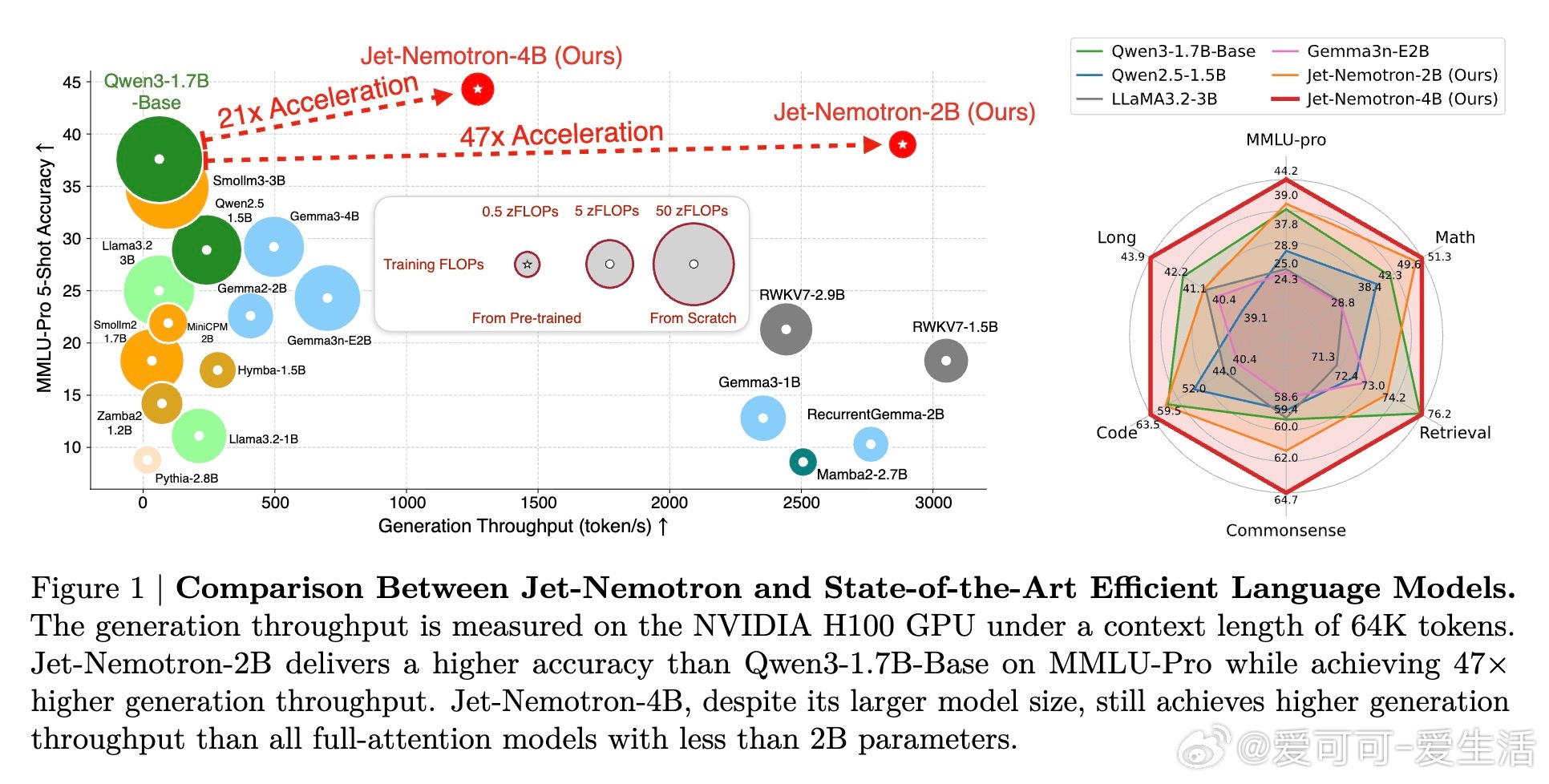
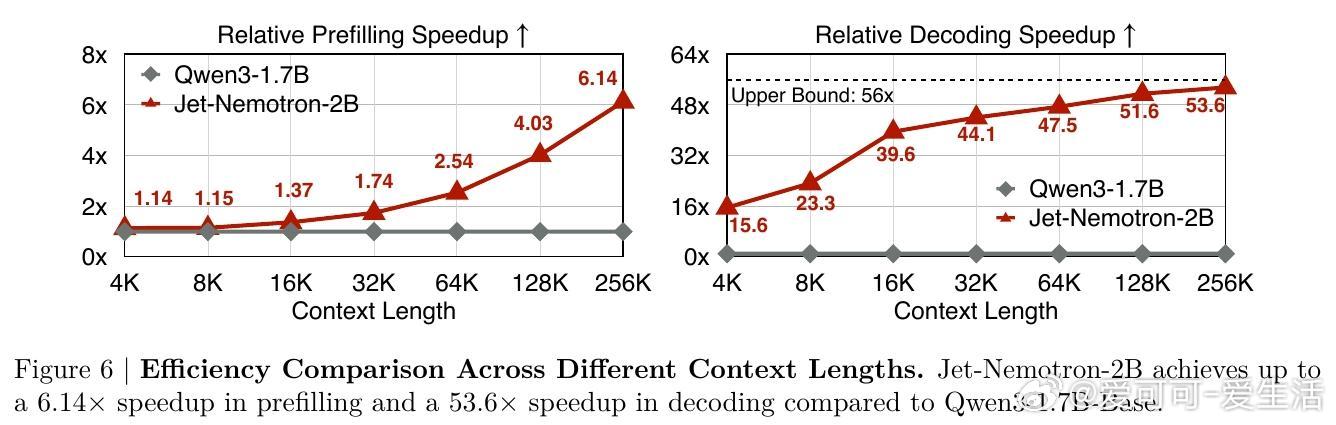
• Jet-Nemotron-2B模型在多项基准测试(MMLU-Pro、数学推理、检索、编码、常识推理、长上下文)中超越Qwen3、Gemma3及Llama3.2等全注意力模型,生成速度提升最高达53.6×,预填充速度提升6.1×。
• 架构设计与训练成本显著降低,为语言模型设计创新提供更低门槛与高回报的路径。
• 在NVIDIA H100 GPU及边缘设备(Jetson Orin、RTX 3090)上均展现优异吞吐性能,适应多场景应用需求。
Jet-Nemotron通过巧妙结合全注意力与高效线性注意力,重塑了大型语言模型的效率与性能平衡,推动长上下文及推理任务的实用化进程。
详细阅读👉 arxiv.org/abs/2508.15884
代码开源👉 github.com/NVlabs/Jet-Nemotron
语言模型神经架构搜索高效注意力深度学习人工智能NLP