[CL]《A Probabilistic Inference Scaling Theory for LLM Self-Correction》Z Yang, Y Zhang, Y Wang, Z Xu... [ Peking University & Alibaba Group] (2025)
大型语言模型(LLM)自我纠正能力的性能演变首次被系统性量化解析。我们提出一套概率推断理论,揭示多轮自我纠正中准确率的动态变化规律:
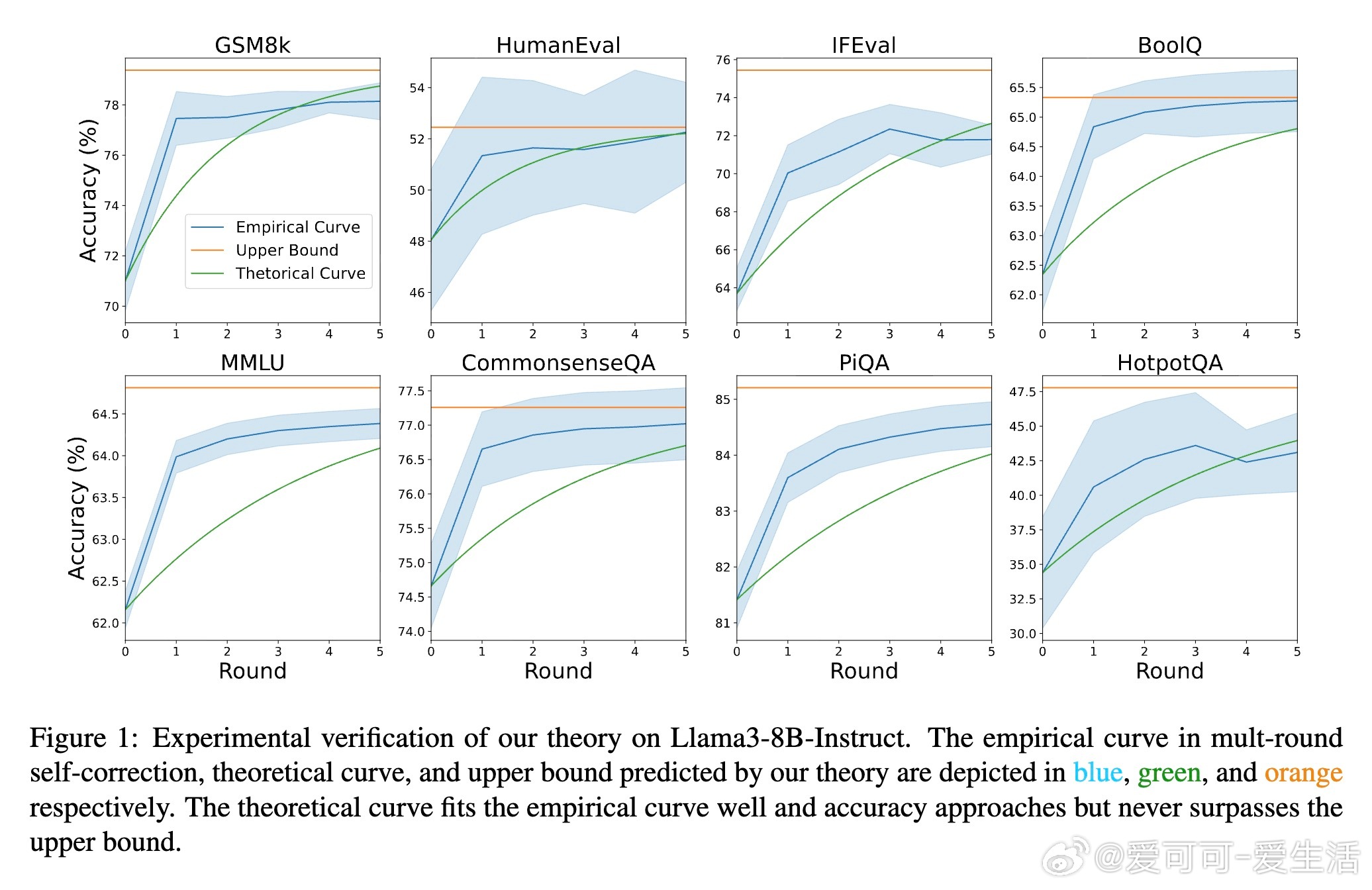
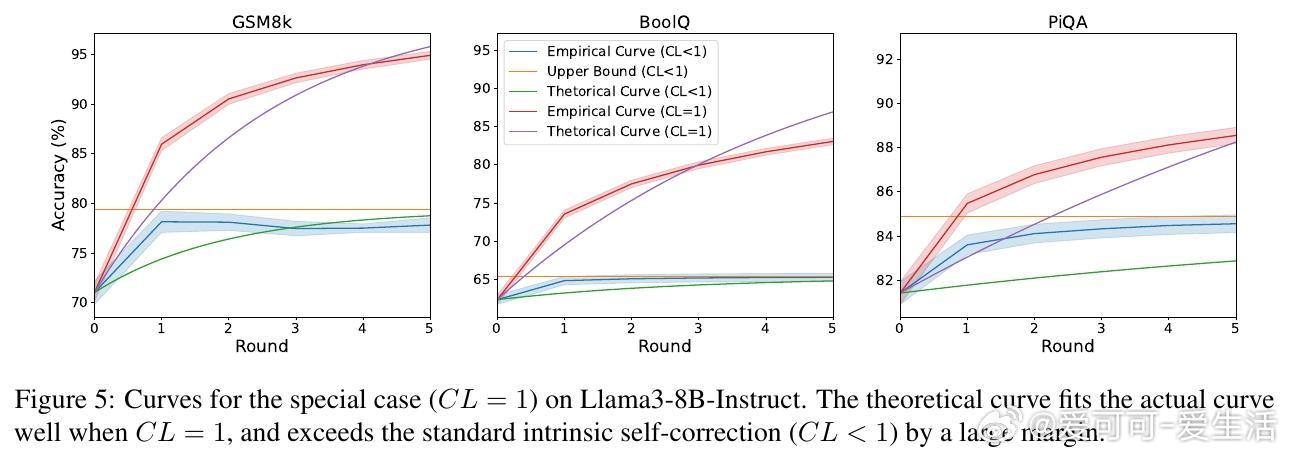
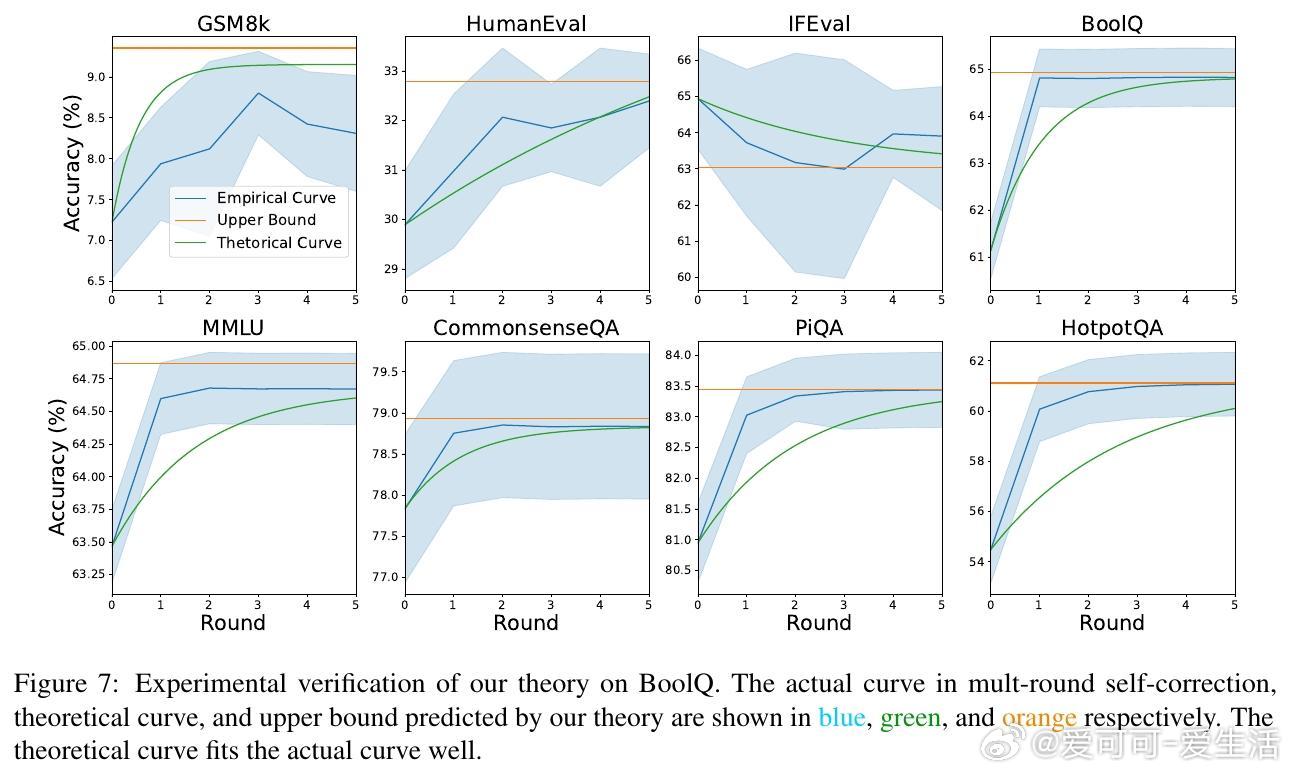
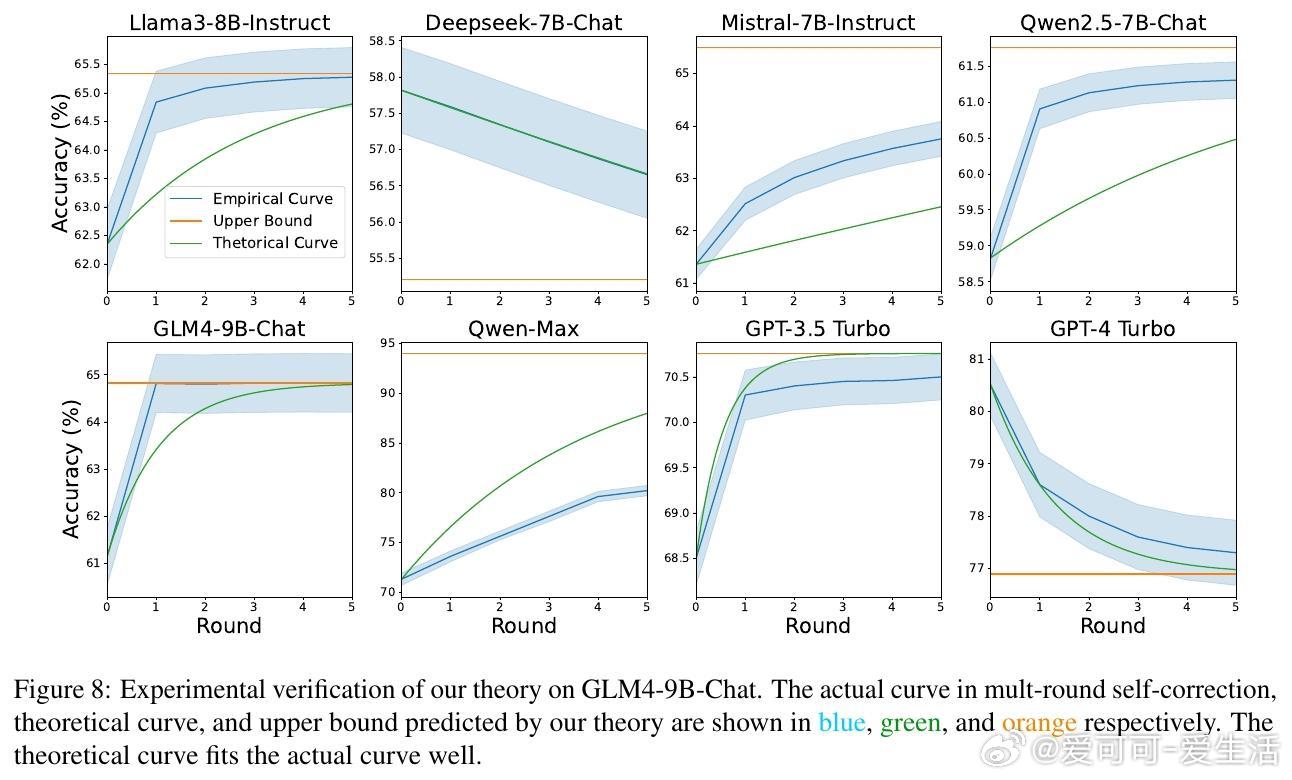
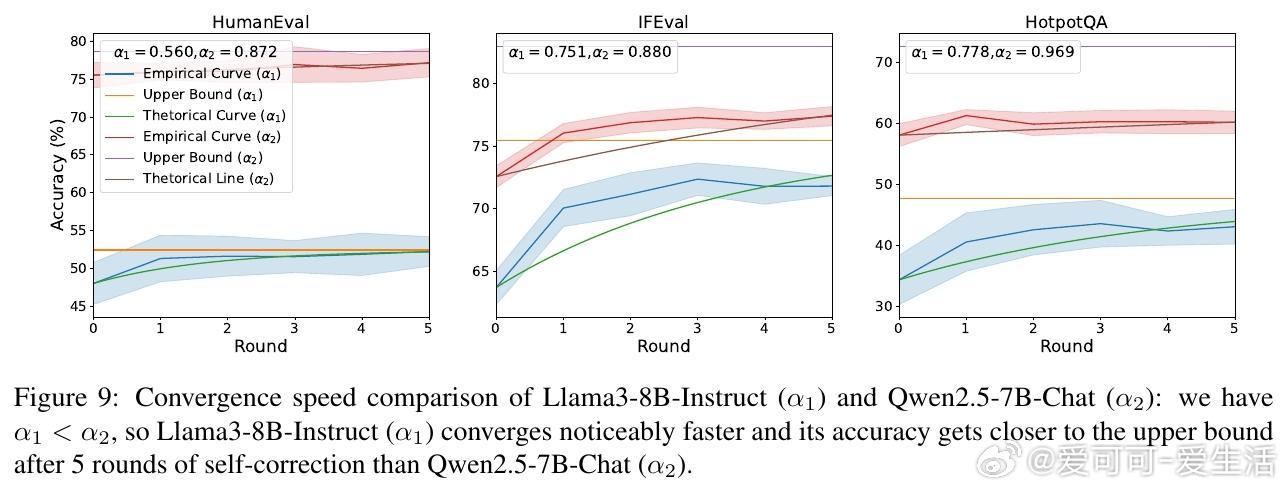
• 通过递归关系 Acct = Upp − α^t (Upp − Acc0) 精确描述第 t 轮自我纠正后的准确率演进,其中 Upp 为准确率收敛上限,α 控制收敛速率,Acc0 为初始准确率。
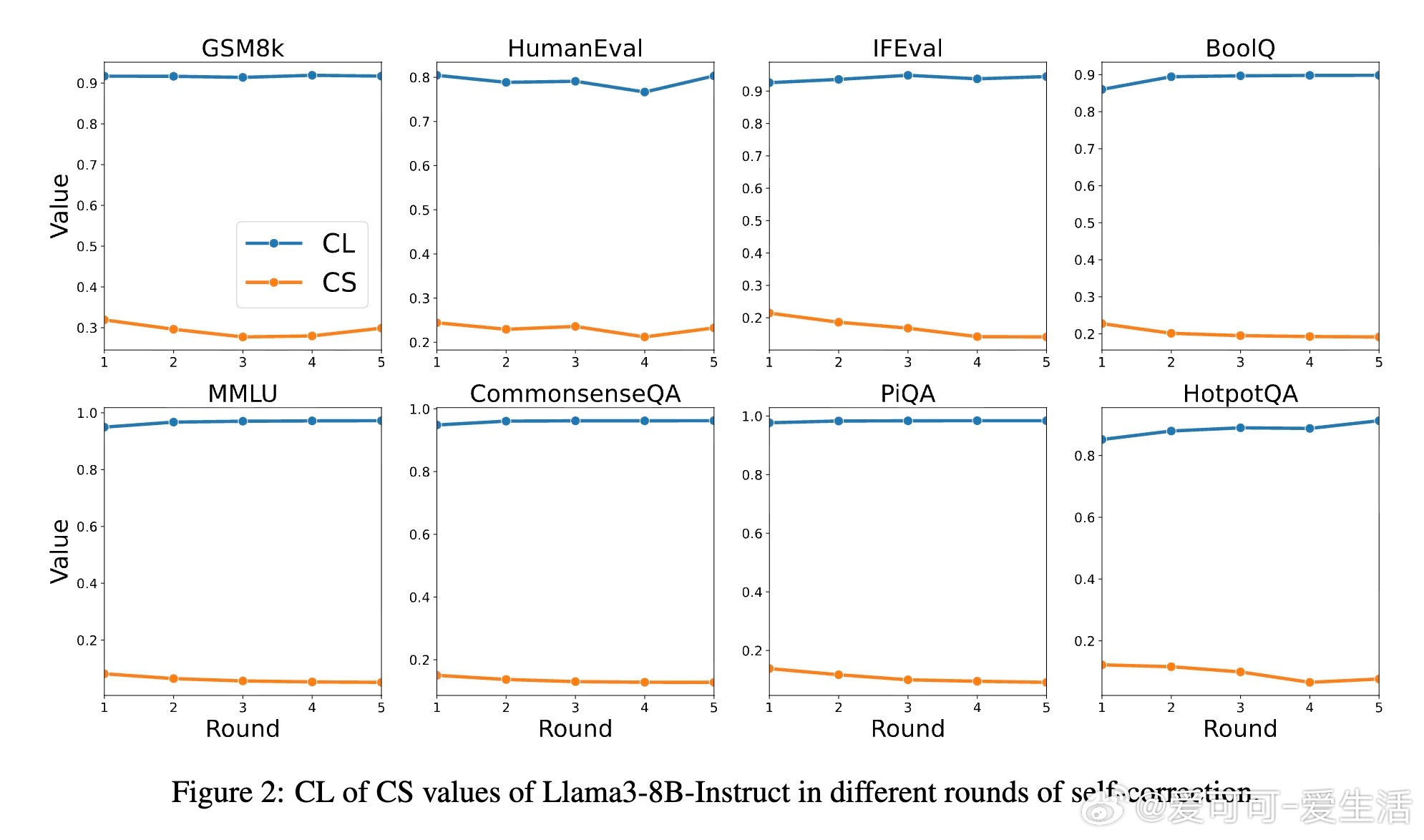
• 引入置信度(Confidence Level, CL)与批判能力(Critique Score, CS)两大核心指标,分别衡量模型保持正确答案的能力和纠正错误答案的能力,二者共同决定最终性能极限。
• 实验覆盖多款开源与闭源模型(如 Llama3、GPT-4 Turbo、Qwen-Max)及八大数据集,理论曲线与实测准确率高度吻合,验证理论有效性。
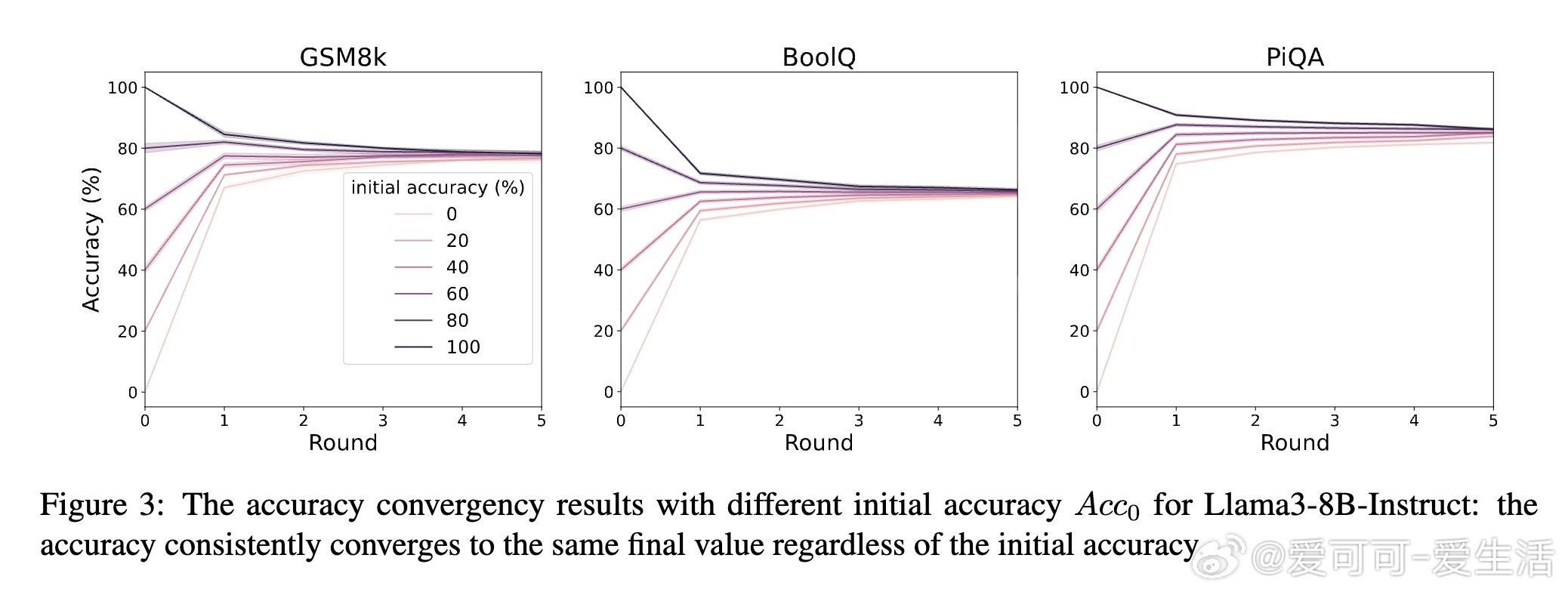
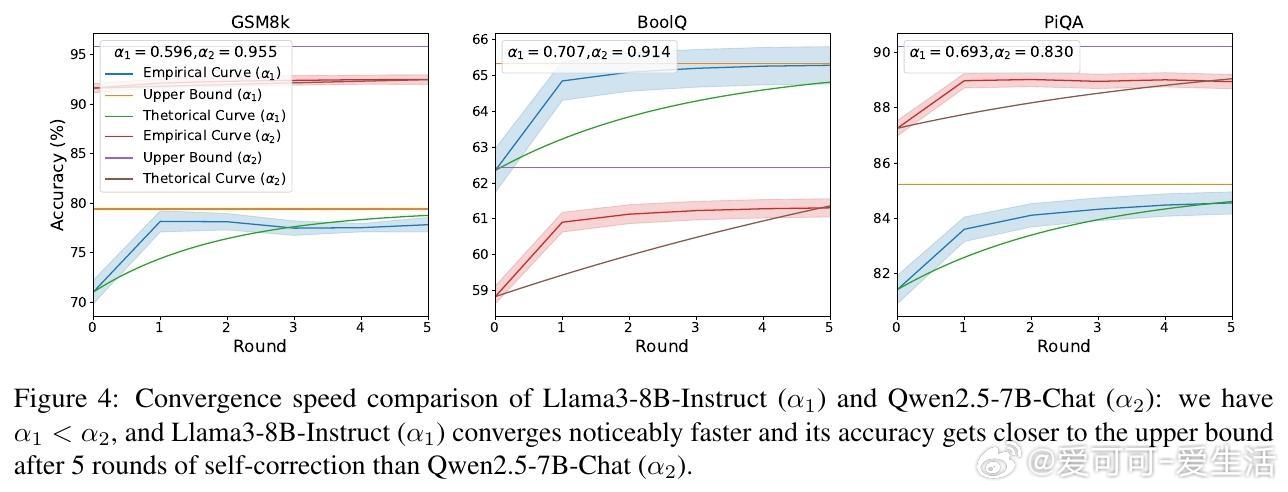
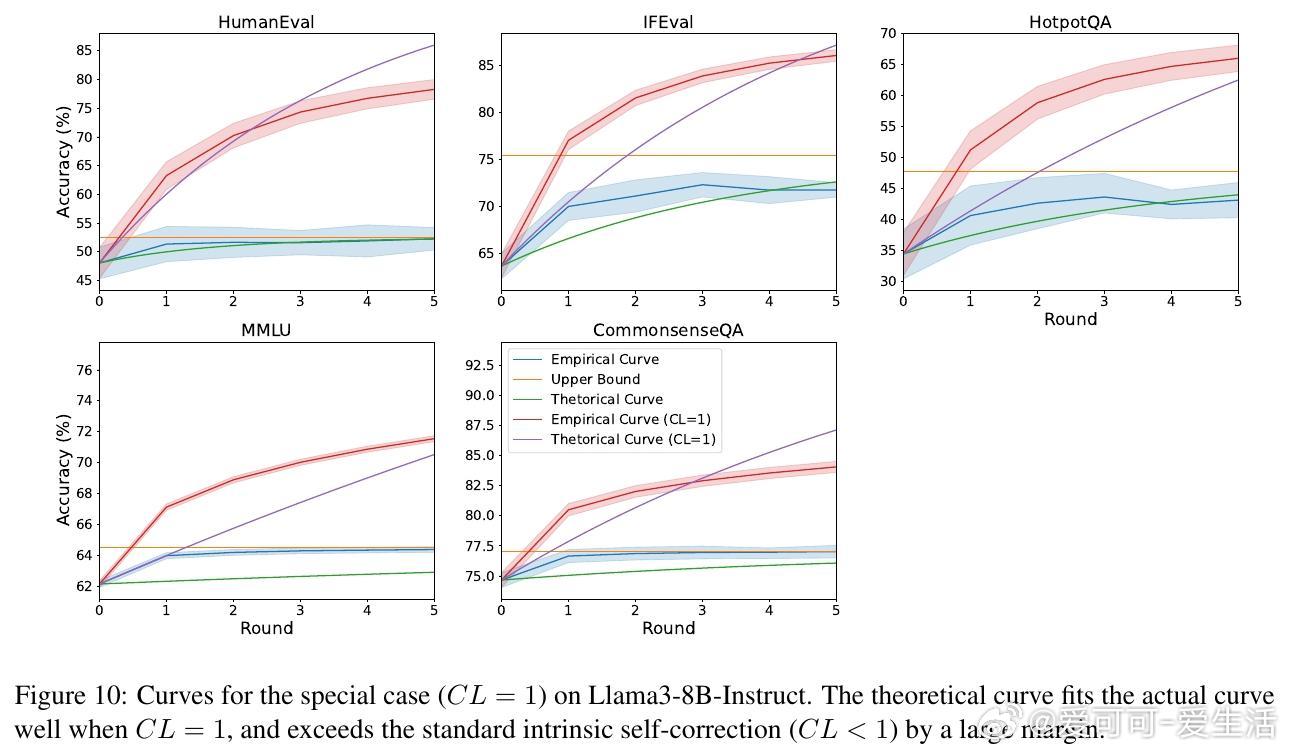
• 三大推论揭示:最终准确率与初始准确率无关,仅由 CL 与 CS 决定;收敛速度由 α = CL − CS 控制,α 越小收敛越快;理想情况下(CL=1),准确率可逼近100%。
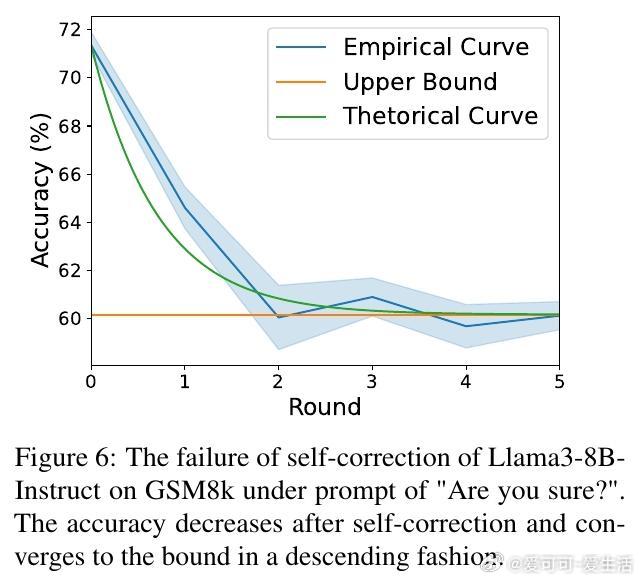
• 进一步分析表明,低质量提示词可能破坏 CL 和 CS 的平衡,导致自我纠正失效,准确率下降,提供优化提示词选择的新思路。
• 本理论为理解和优化 LLM 自我纠正机制奠定数学基础,推动推理能力提升和推理扩展的理论研究。
详见👉 arxiv.org/abs/2508.16456
大型语言模型自我纠正推理扩展概率推断人工智能