分布式训练核心术语全览,系统梳理多维度并行与优化方法,助力深入理解与高效实践:
• 并行策略
- 数据并行:模型复制,数据拆分,梯度同步,扩展批量大小,通信开销与模型规模相关。
- 模型并行:跨设备拆分模型层,顺序传递激活与梯度,适合超大模型,需精细划分与通信优化。
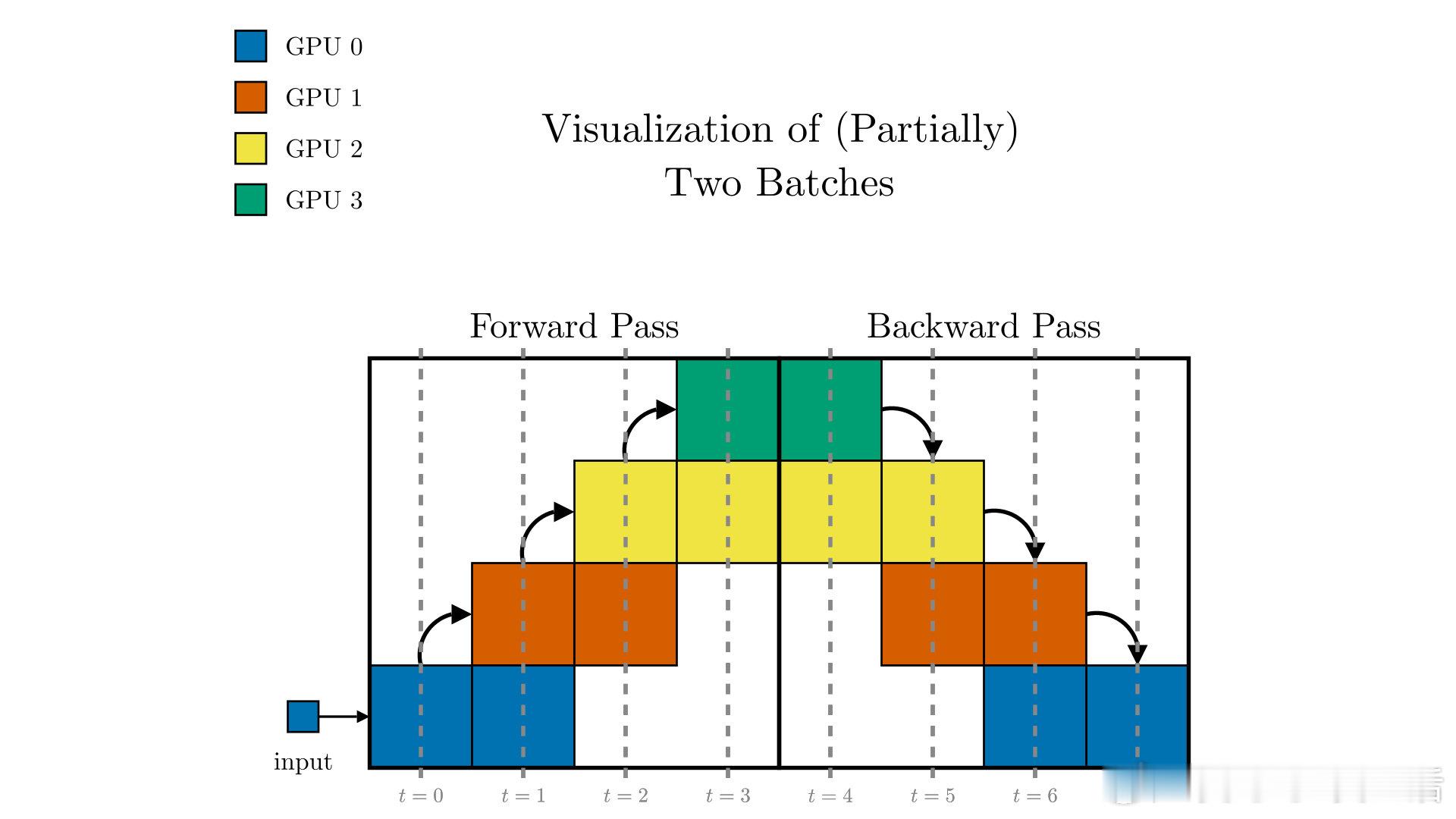
- 流水线并行:分层分设备处理微批次,重叠计算与通信,减少空闲等待。
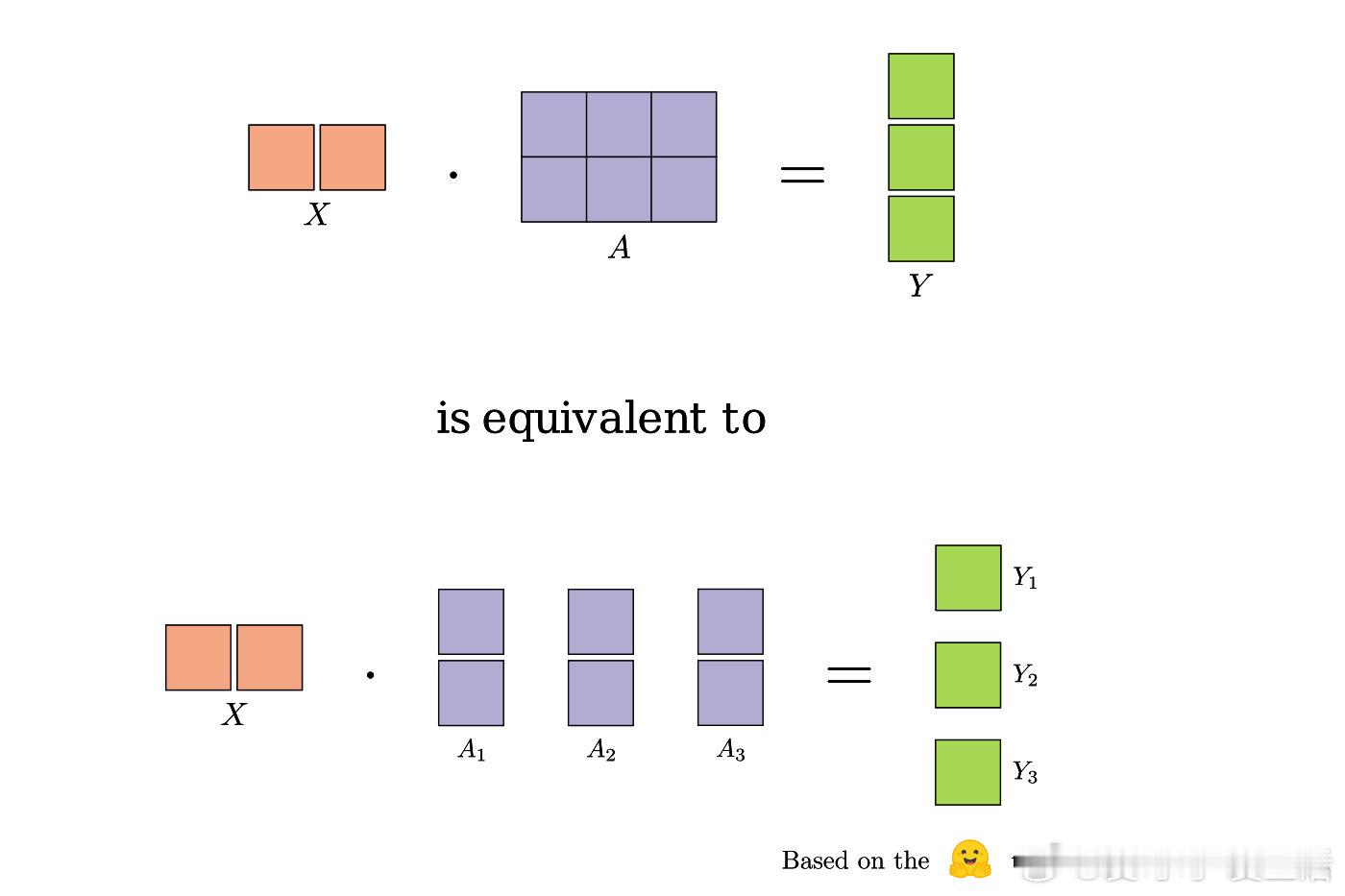
- 张量并行:拆分单层权重和激活,局部计算结合集体通信,实现参数极致分片。
- 混合并行:结合多种并行策略(2D、3D),打破单一限制,支持千亿级参数训练。
• 内存优化技术
- 参数分片(Sharding):切分权重、梯度、优化器状态,显著降低单卡内存占用。
- ZeRO系列(1到3阶段):分层切片优化器状态、梯度及参数,最大化显存利用。
- FSDP:PyTorch的全分片数据并行,自动分片和合并,配合CPU卸载扩展大模型训练。
- 激活检查点:选择性保存激活,牺牲额外计算换内存释放,支持更大批量和模型宽度。
- CPU与NVMe卸载:多层内存体系延展,突破GPU显存瓶颈,适配千亿参数规模。
• 通信模式与集体操作
- All-Reduce/All-Gather/Reduce-Scatter等确保跨节点梯度同步和参数重组。
- 广播与点对点通信支持模型初始化与细粒度数据交换。
- 拓扑感知调度优化通信路径,减少延迟和带宽瓶颈。
• 训练优化技巧
- 异步与弹性训练:动态增减节点,容错与资源弹性利用。
- 梯度累积、多精度训练提升训练效率与稳定性。
- 梯度压缩、稀疏优化与量化感知训练减少通信负担并提升推理效率。
- 计算与通信重叠,智能参数分片提升吞吐和扩展性。
• 规模与效率衡量
- 弱强扩展性权衡,关注时间-性能平衡。
- 网络拓扑与异构硬件支持实现近线性加速与资源最大化利用。
- 训练时间(TTT)与样本吞吐率为核心指标,指导系统调优。
• 基础概念
- 节点、工作进程、加速器定义,批量大小分层理解。
- 检查点与容错机制保障训练稳定性与恢复能力。
- 通信后端及多程序多数据(MPMD)支持复杂分布式场景。
深刻理解并行范式与资源管理本质,是突破模型规模与训练效率瓶颈的关键。分布式训练不仅是技术集成,更是一套系统级优化的方法论,指导设计高效、可靠、可扩展的深度学习训练体系。
详情🔗 distributedlexicon.com
分布式训练 深度学习 模型并行 内存优化 人工智能 高性能计算