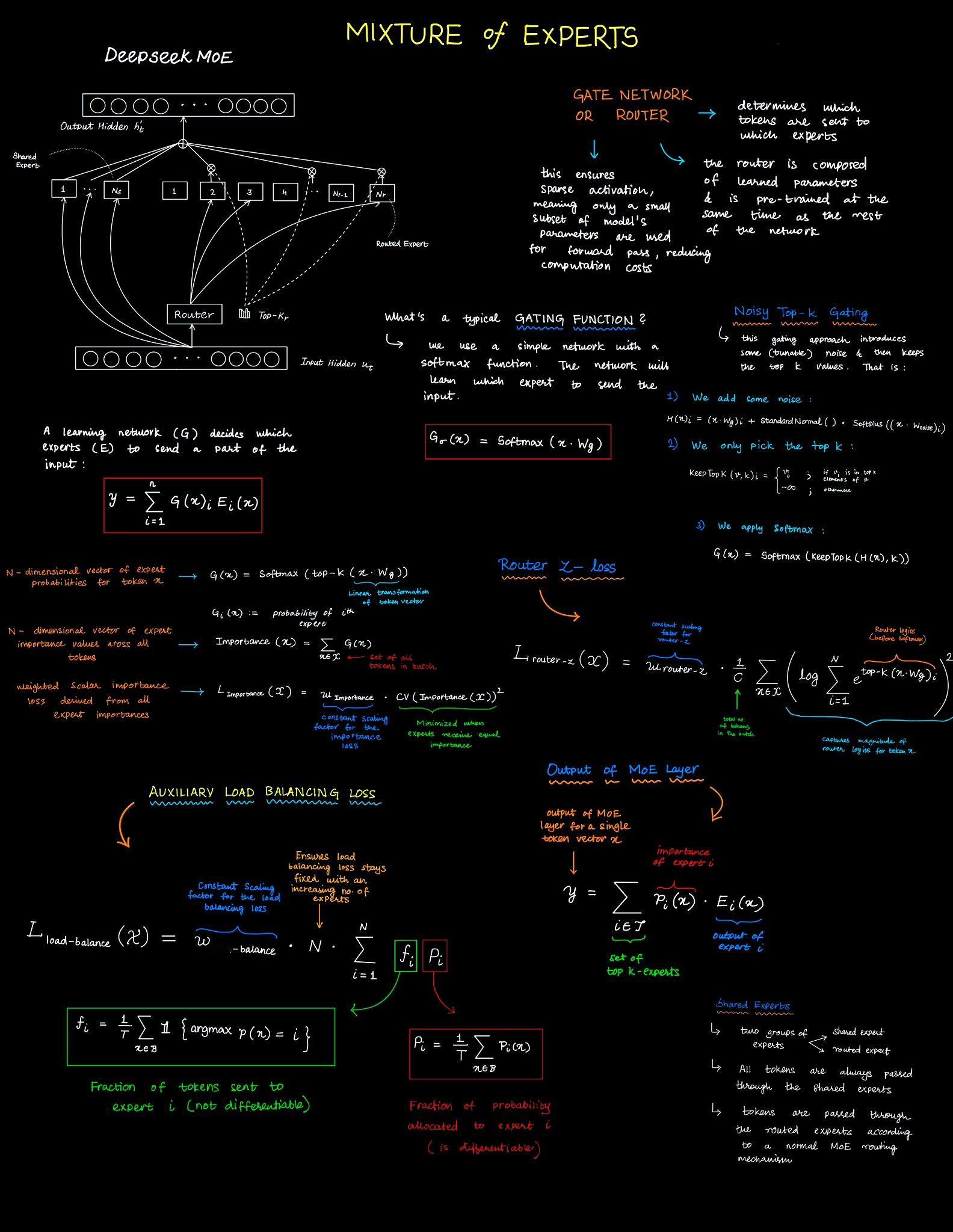
这张图和下面的内容是推友 novasarc01 绘制的MoE知识截图。
混合专家模型(Mixture of Experts, MoE) 是深度学习中一种强大的方法,它通过利用稀疏激活机制,使模型能够高效扩展。与为每个输入激活所有参数不同,MoE 使用一个路由器选择一部分专家进行处理,从而提高计算效率并增强泛化能力。MoE 已被广泛应用于大规模模型中,例如 Switch Transformer、DeepSeek 和 GShard。
🔹 什么是专家?
在 MoE 中,专家是独立的前馈神经网络(如多层感知机 MLP 或其他架构),它们专注于不同类型的数据。与使用单一整体模型处理所有输入不同,MoE 会根据每个 token 动态选择最相关的专家,从而实现专业化和更高的参数效率。
很多人常常误解专家是指特定领域(如生物学或化学)的专家。然而,在 MoE 的上下文中,专家专注于句子结构和语法的不同方面,例如复杂词汇、标点符号、视觉描述、动词等。
🔹 路由机制
MoE 的关键组件是路由器(router),它决定哪些专家处理给定的输入。路由器通常是一个学习得到的函数,常通过小型神经网络或简单的线性变换加 softmax 实现。路由过程包括以下步骤:
计算专家得分 :路由器网络为每个输入分配一个关于专家的概率分布。
Top-k 选择 :MoE 不会使用所有专家,而是为每个 token 选择得分最高的 k 个专家。
分发与处理 :被选中的专家处理 token,最终输出是专家输出的加权和。
🔹 MoE 中的负载均衡
MoE 面临的最大挑战之一是负载均衡——确保所有专家接收到的 token 数量大致相等。如果没有适当的均衡,某些专家可能会过载,而其他专家则可能未被充分利用,导致计算效率低下和性能下降。
为了解决这一问题,引入了多种辅助损失函数:
辅助负载均衡损失 :通过对不平衡的路由决策施加惩罚,促进 token 在专家间的均匀分布。
路由器 Z 损失 :通过防止对专家选择的过度自信,帮助稳定路由器的学习过程。
重要性因子 :衡量每个专家被选择的频率,并用于指导训练以平衡利用率。
🔹 DeepSeek-MoE 中的共享专家
DeepSeek-MoE 提出了一个有趣的变体,其中专家在多个层之间共享,而不是每层拥有自己独立的一组专家。这种方法减少了参数冗余,提高了效率,同时保留了 MoE 的优势。
AI生活指南AI创造营