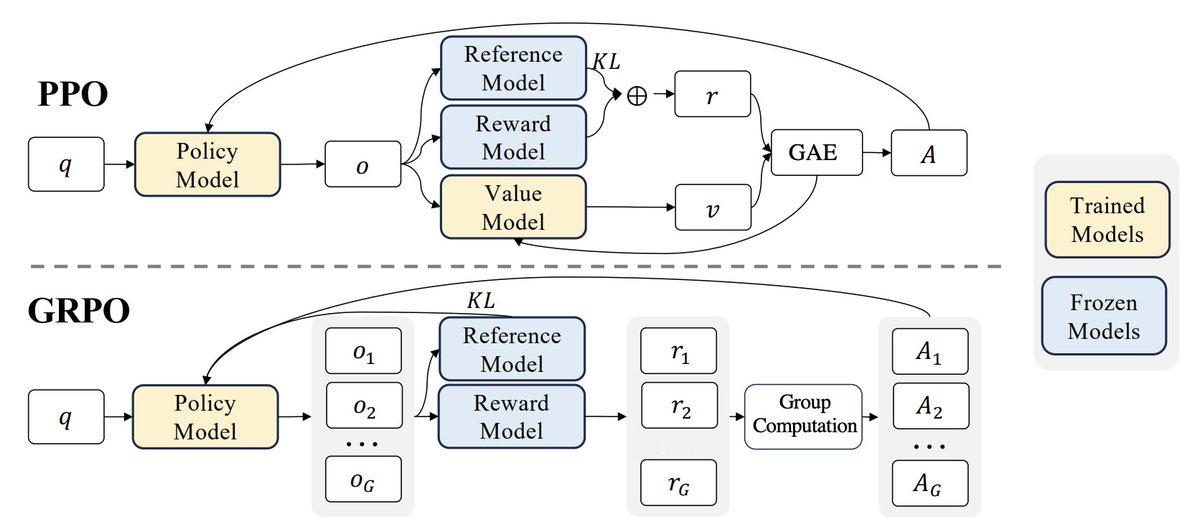
virat举了个例子来方便理解DeepSeek的GRPO: 组相对策略优化算法:
问题:“2 + 3等于多少?”
🌟步骤1:大语言模型生成三个答案。
1. “5”
2. “6”
3. “2 + 3 = 5”
🌟步骤2:为每个答案打分。
“5” → 1分(正确,但没有推理过程)
“6” → 0分(错误)
“2 + 3 = 5” → 2分(正确,并且有推理过程)
🌟步骤3:计算整个组的平均分数。
平均分数 = (1 + 0 + 2) / 3 = 1
🌟步骤4:将每个答案的分数与平均分数进行比较。
“5” → 0 (等于平均分)
“6” → -1 (低于平均分)
“2 + 3 = 5” → 1 (高于平均分)
🌟步骤5:强化大语言模型以偏好更高的分数。
偏好像 3这样的回答(积极)
保持像 1这样的回答(中性)
避免像 2这样的回答(消极)
这个过程会重复进行,使模型能够随着时间推移不断学习和改进。