有些人担心DeepSeek的低成本训练可能
会损害GPU市场,但老实说,我认为这实
际上是一个好消息。
一个很大的误解是,如果复制 DeepSeek
方法,公司就不需要那么多GPU进行训
练。但问题是,DeepSeek-R1的低成本
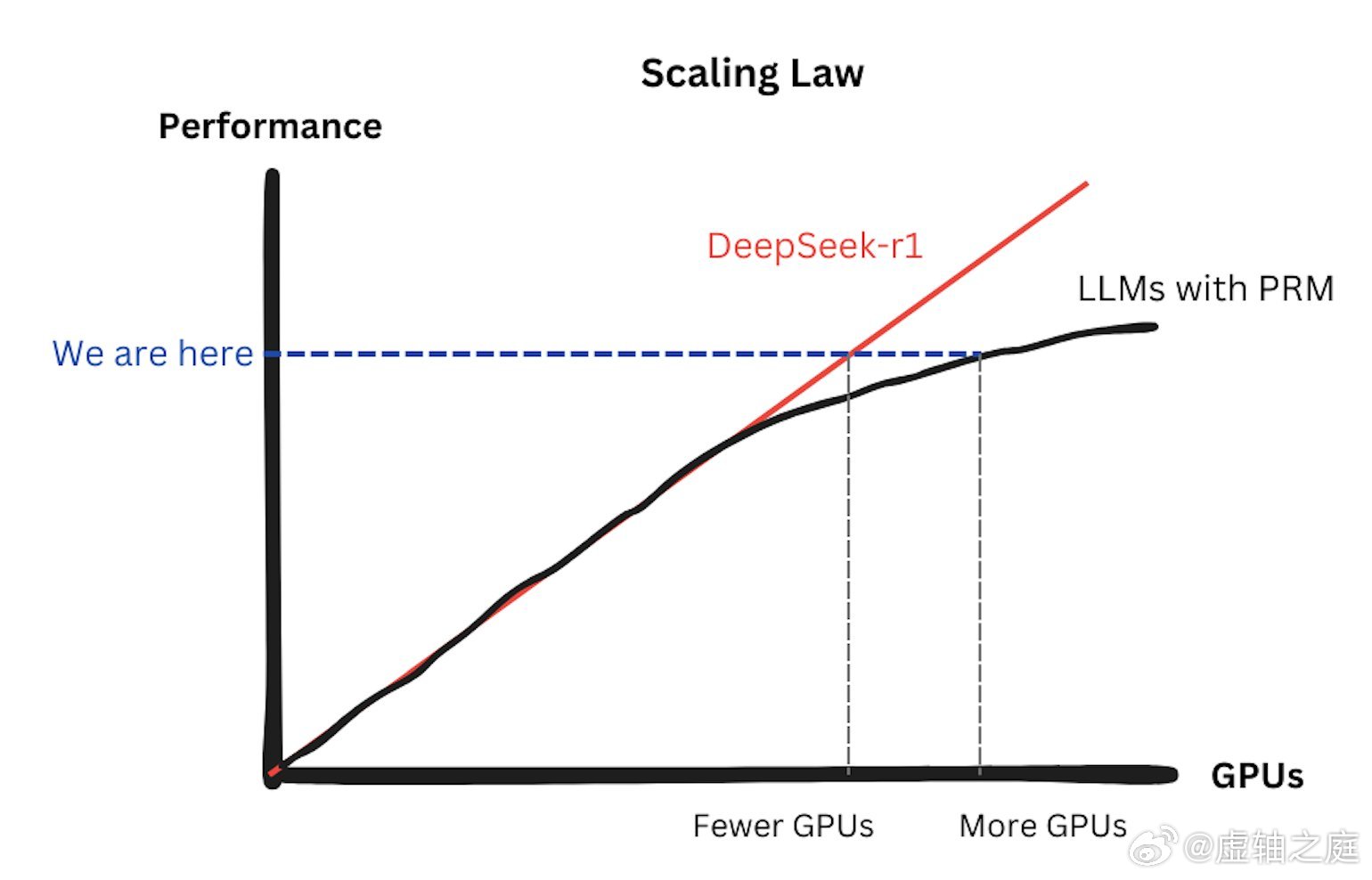
训练方法是可扩展的。基本上,在其上添
加更多GPU仍然可以提高性能。这是缩
放定律的改进。看看我下面画的速写:在
DeepSeek 之前,使用PRM(过程奖励
模型)的大型模型会遇到收益递减的问题
——缩放定律有点失效了,因为它们需要
额外的GPU来训练PRM进行推理监督。
但DeepSeek恢复了缩放定律:投入的
GPU越多,性能扩展性越好。这绝对是
GPU市场的胜利。
另一个误解是DeepSeek专注于推理,而
不是训练。实际上,DeepSeek-R1完全是
关于训练的——这是一种称为后训练的方
法,可以使模型更好地进行推理。就GPU
需求而言,这种训练与预训练没有太大区
别。至于纯推理时间扩展/搜索(模型尝试
不同的答案并选择最佳答案),目前并不
常见,因为它会给用户带来太多延迟。不
过我认为o1-pro可能会使用这种测试时间
搜索。有趣的是,DeepSeek发现PRM对
后训练推理没有太大帮助,但对测试时间
推理很有用,尽管它仍然不值得——它的
价格太昂贵了。
从长远来看,对GPU和Scaling Law来
说,真正不利的不是模型,而是数据。
LLM已经用尽了互联网上的大部分数据,
而且要获得更多数据将变得更加困难。我
们最终可能会拥有大量的GPU,但没有数
据来训练任何东西。