每年都用琳达问题调戏一下各公司大模型。今天试了下。ChatGPT o1(图1)和4o(图2)给出了截然相反的答案,说明两者的算法和数据是不一样的。国产大模型中,豆包(图3)和腾讯(图4)都给出了理性的答案,其他阿里、百度、幻方、月之暗面和讯飞(图5-9)都给出的错误答案。(另,不用琳达的名字,是因为有些公司会把琳达问题写死,问琳达就是正确答案,改个名就给错误答案,去年ChatGPT3.5就是这样)


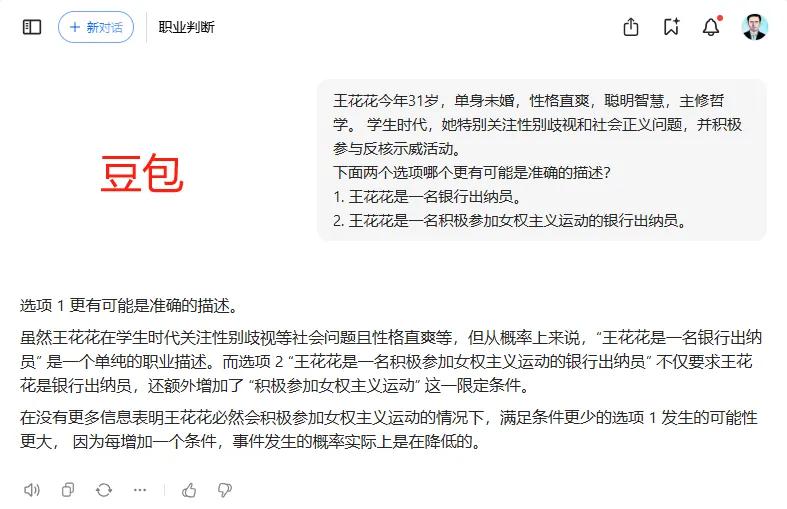
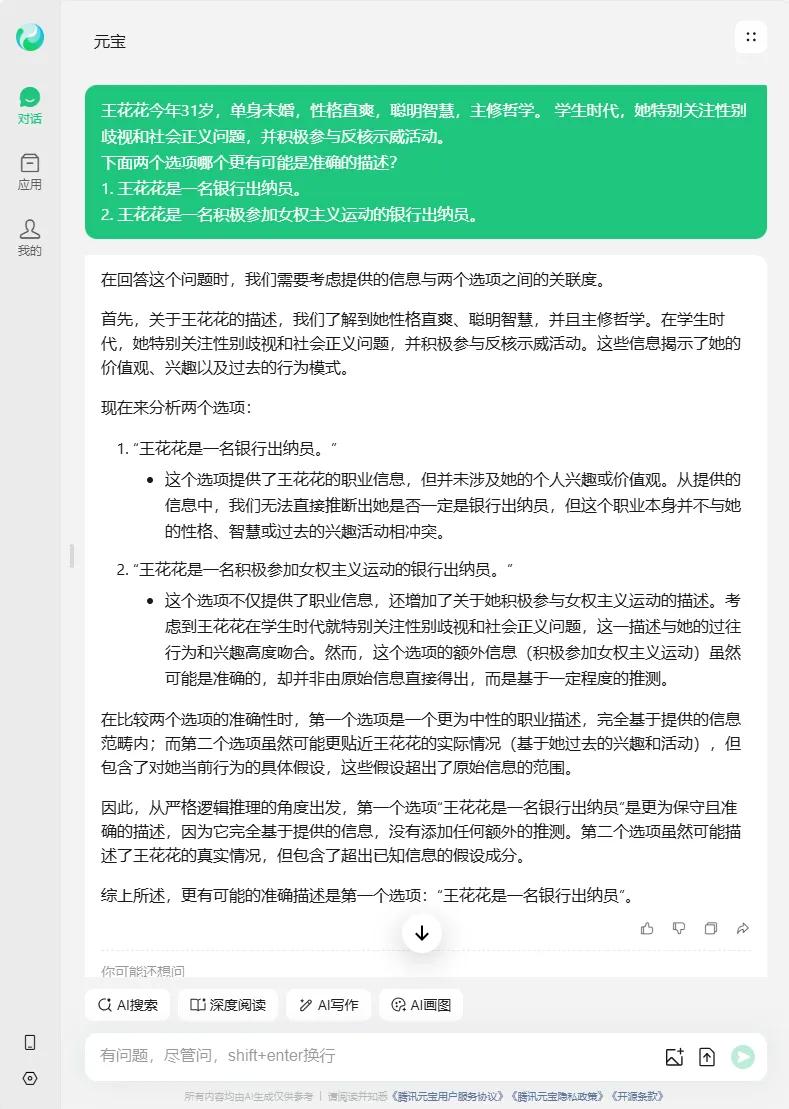
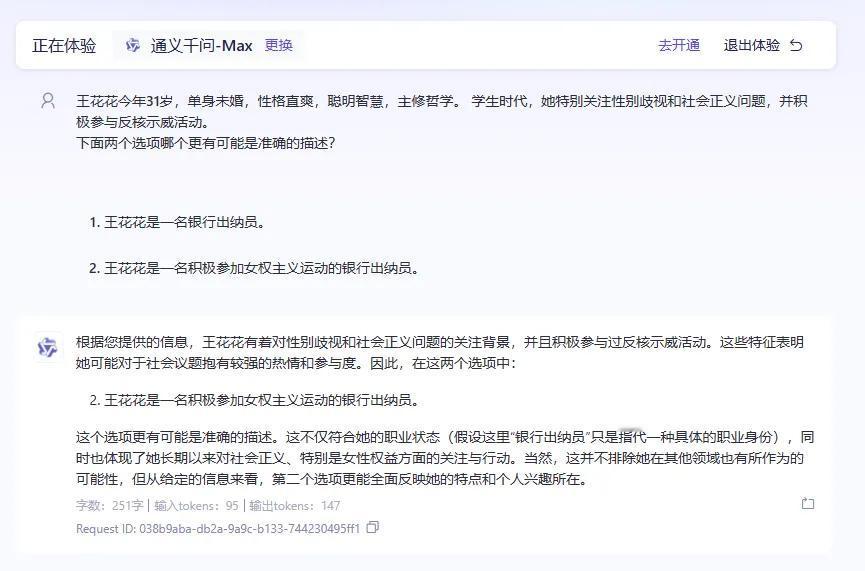

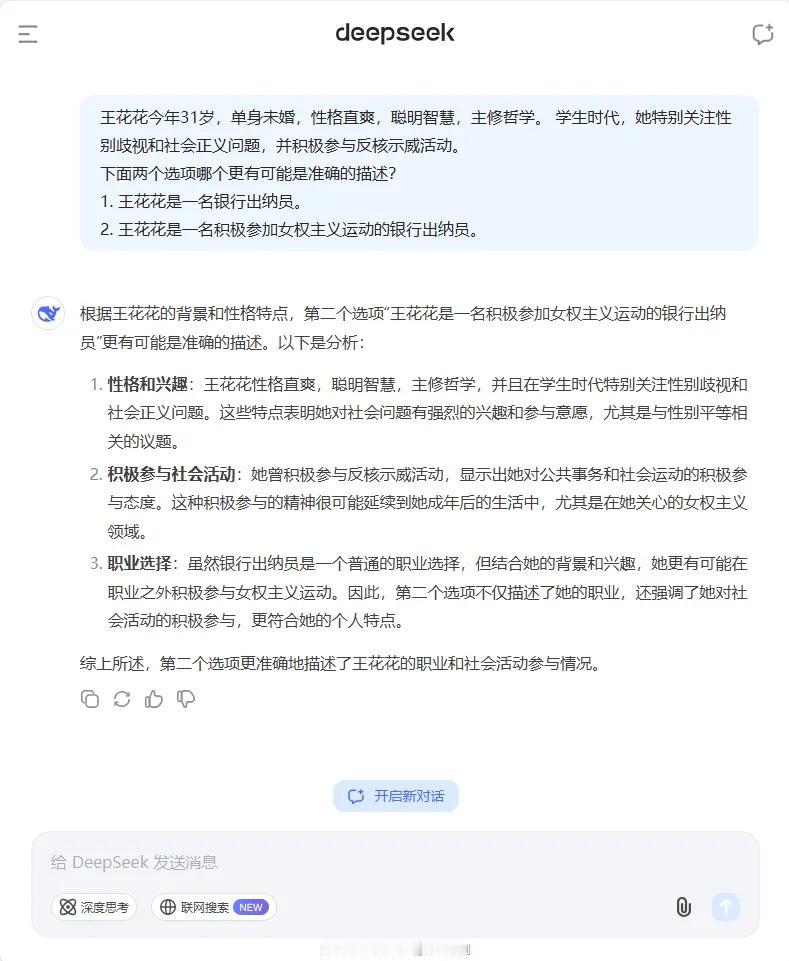
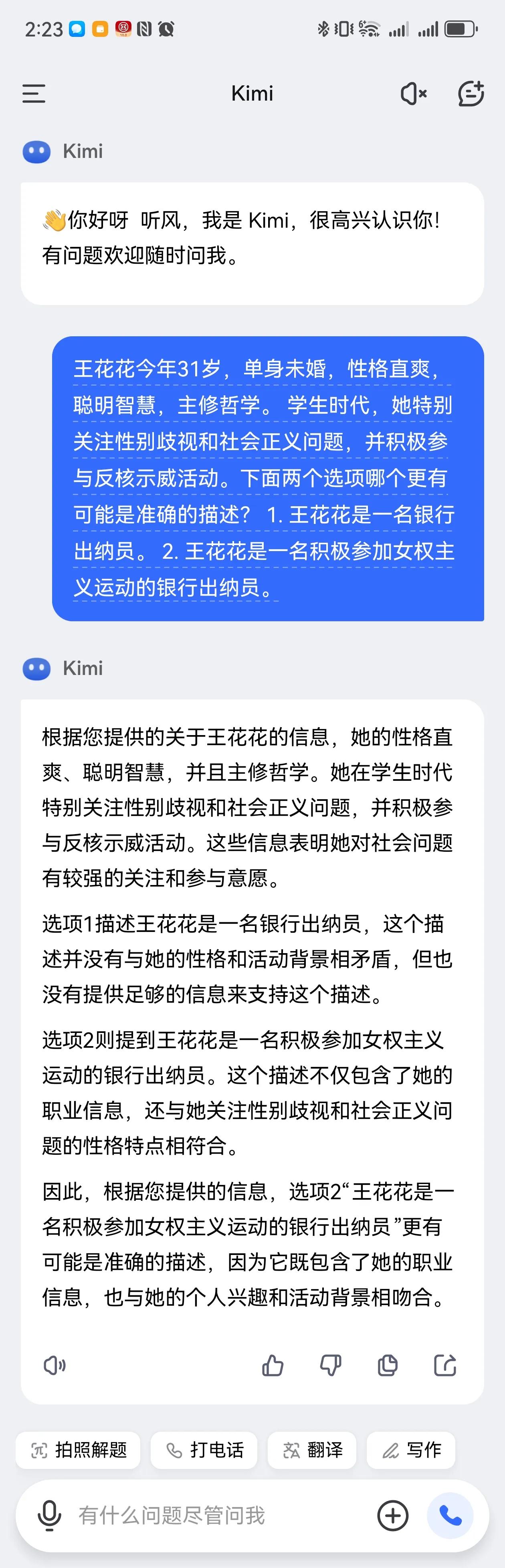

每年都用琳达问题调戏一下各公司大模型。今天试了下。ChatGPT o1(图1)和4o(图2)给出了截然相反的答案,说明两者的算法和数据是不一样的。国产大模型中,豆包(图3)和腾讯(图4)都给出了理性的答案,其他阿里、百度、幻方、月之暗面和讯飞(图5-9)都给出的错误答案。(另,不用琳达的名字,是因为有些公司会把琳达问题写死,问琳达就是正确答案,改个名就给错误答案,去年ChatGPT3.5就是这样)

作者最新文章
热门分类
财经TOP
财经最新文章