谷歌又干了件大动作,直接把大家念叨好几个月的 Gemini 3.0 扔出来了。
我一看到 LMArena 的榜单,整个人都愣住了。
1501 分,这成绩真像是开挂一样。
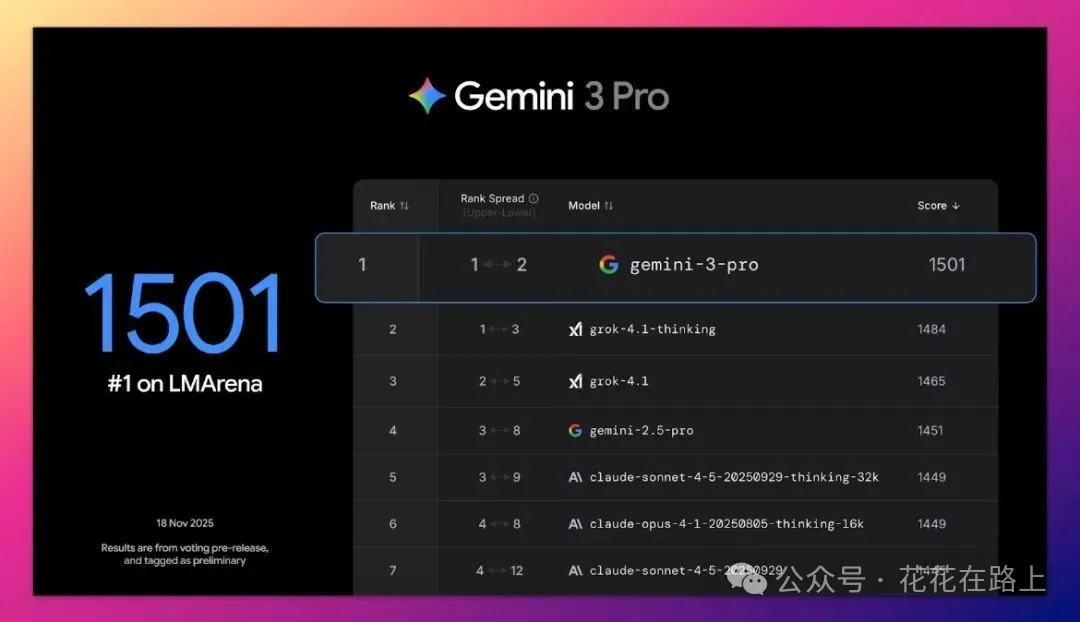
Grok 4.1刚上线那会,马斯克拿了 1483 分乐得飞起,现在倒好,只高兴了一晚上,风向就变了。
谷歌这次来的不是更新,是“宣战”。

01 Gemini 3.0到底有多强?断层领先!
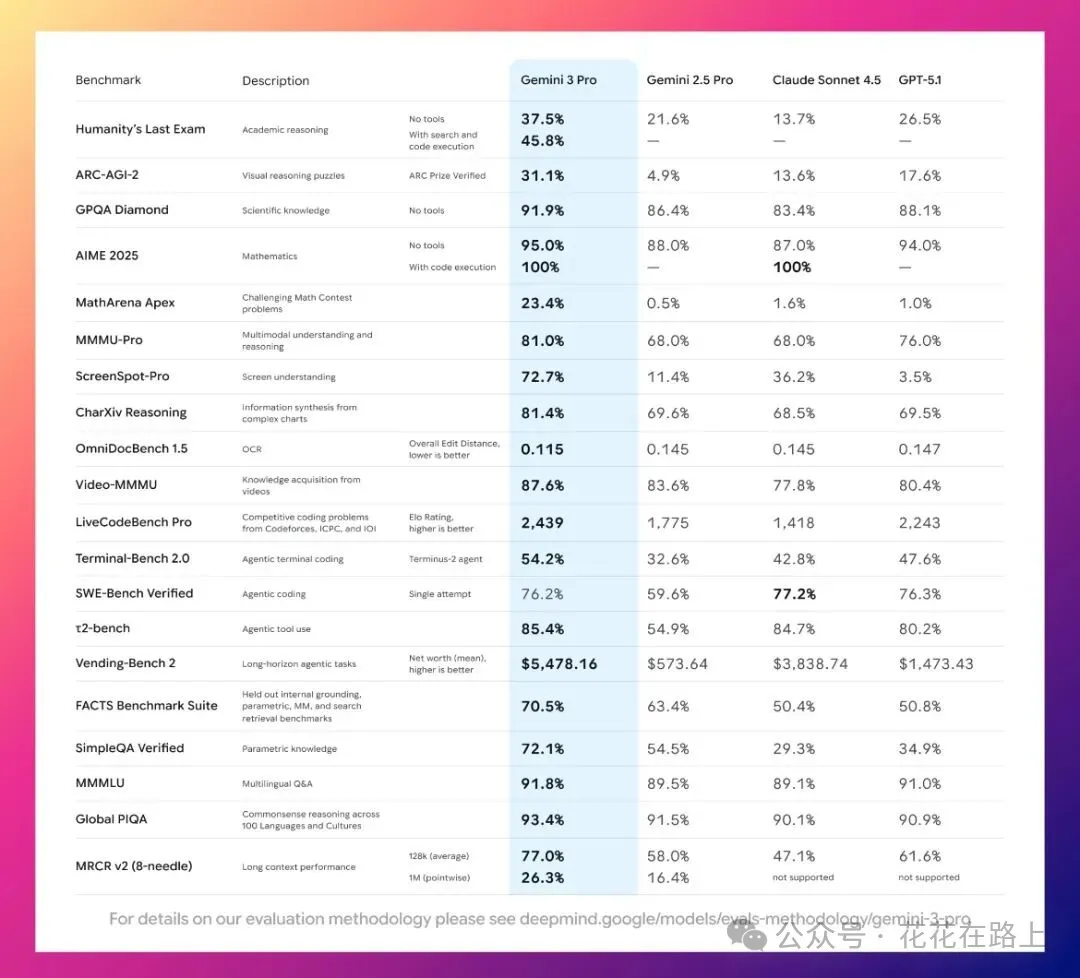
这次最让人服气的,是谷歌把 Gemini 3 Pro 的完整测试数据全摊在台面上,不遮不掩。跑下来几乎是全项目通杀,除了编程领域有一项没拿第一,其他结果都在天花板上吊着。
尤其是那个博士级难度的 HLE 测试,它能做到 37.5%,还是不带任何外部工具的纯推理。你再看 GPT-5.1 的 26.5%,Claude 的 13.7%,就知道什么叫差距肉眼可见。
再说数学。
MathArena Apex 那 12 道题都是全球数学竞赛里挑出来的“地狱模式”,以前的模型在那儿挠头的时候,Gemini 3 Pro 来了个 23.4%,这不叫领先,这是降维打击。
唯一能挑毛病的 SWE-Bench Verified,它也拿了 76.2%,只比第一少 1%,实力依旧站在顶上。
02 开挂的Gemini 3.0
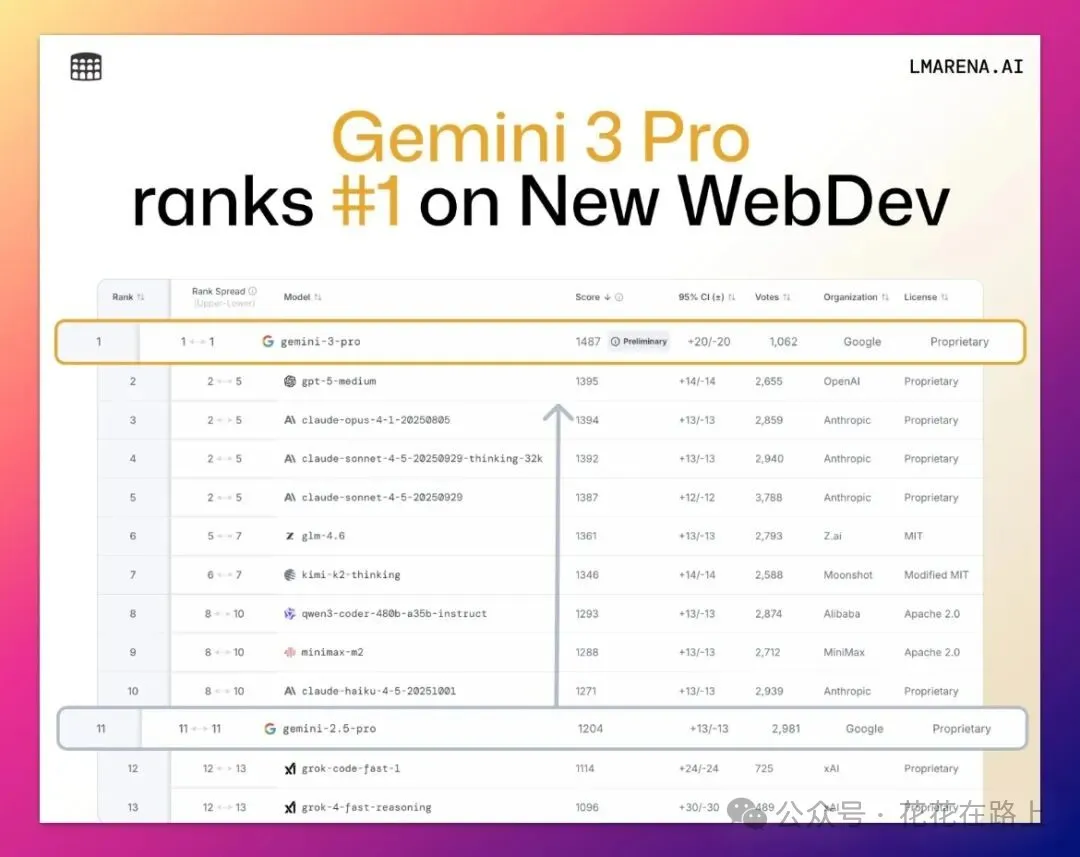
之前传说 Gemini 3 主攻前端,这次算彻底坐实了。
在 WebDev Arena 上,它一句话生成网页的分数直接甩第二名 GPT-5 将近100分!
谷歌还顺手扔了个 Google Antigravity 的工具,不是普通代码编辑器,而是“你一句话,AI 团队集体给你干活”的那种。
有的写代码,有的改 Bug,有的优化性能,像你突然多了几个不睡觉的开发同事。
03 秒杀级的多模态理解
模型本体也没让人失望。
Gemini 3 Pro 继续保持 100 万 tokens 的超长上下文,依旧是最大那个。文本、视频、图片、PDF 都不用你处理,它自己就能吃进去。
在看屏幕界面理解的 ScreenSpot Pro 测试里,它直接做到 72.7%,GPT-5.1 甚至只有 3.5%,差到让人怀疑是不是跑错题库了。
谷歌还塞了一个很实用的功能:media_resolution。可以自己调阅读图片和视频的精细度,普通合同几百 tokens 就能解析完,要看细节再把精度拉高,灵活又省钱。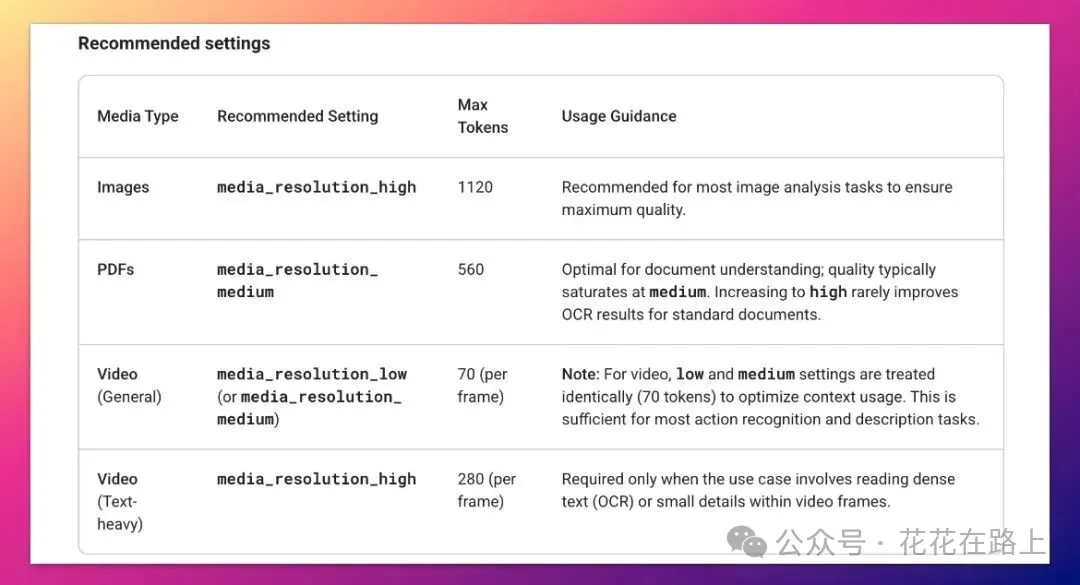
04 还有更狠的
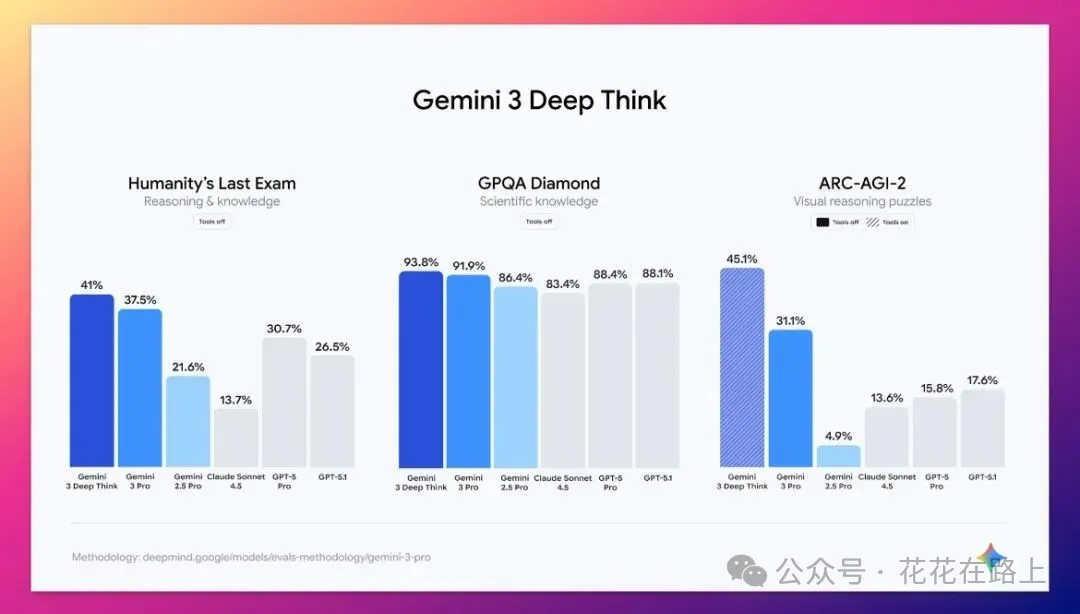
谷歌的 Gemini 3 Deep Think,就是那个数学界吊打对手的 Deep Think 的升级版,推理更猛,只是还要做安全评估。
很多朋友已经开始问我:“Gemini 3 Pro 那么猛,我怎么升级?会不会弄错地区?卡在验证?”
这里也顺便说一句,如果你想试试 Gemini 3 Pro,又嫌升级麻烦、不会调环境、怕扣错钱,直接来找我就行(\/:gptpro2233)
谷歌这波更新,确实有点宣告新时代的味道。
等你体验完 Gemini 3 Pro,说不定你也会有种“原来科幻是这么落地的”感觉。