「NAS、键盘、路由器······年轻就要多折腾,我是爱折腾的熊猫,今天又给大家分享最近折腾的内容了,关注是对我最大的支持,阿里嘎多」
引言

项目地址为https://github.com/zhuguadundan/VideoWhisper,感兴趣的可以去多多支持。
部署机

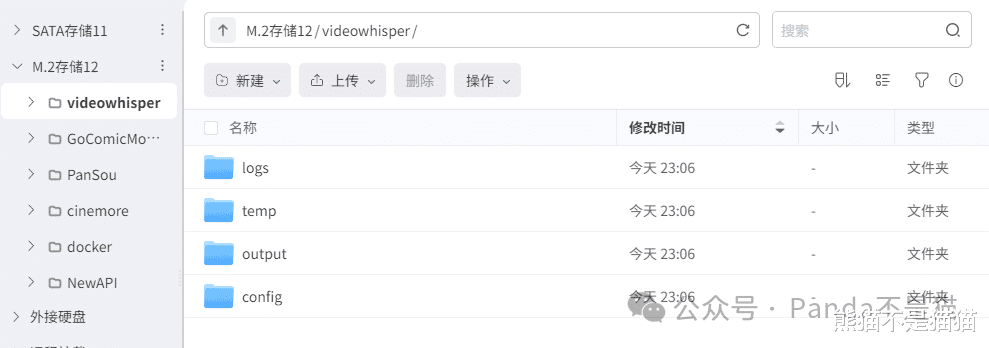
咱回到部署过程。项目都已经提供 compose 文件了,所以部署起来特简单。不过因为涉及数据持久化,所以部署之前,咱们得先把对应的映射文件夹建好。
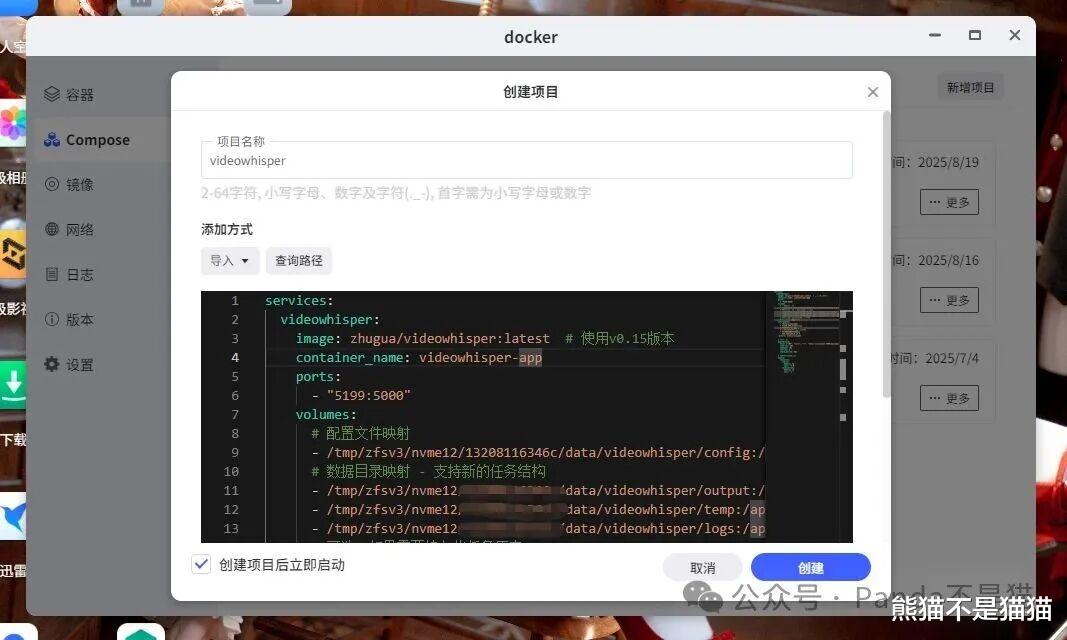
随后我们打开极空间的Docker应用,来到compose新建项目复制代码。
services: videowhisper: image: zhugua/videowhisper:latest # 使用v0.15版本 container_name: videowhisper-app ports: - "5000:5000" volumes: # 配置文件映射 - ./config:/app/config # 数据目录映射 - 支持新的任务结构 - ./output:/app/output - ./temp:/app/temp - ./logs:/app/logs # 可选:如果需要持久化任务历史 # - ./data:/app/data environment: - TZ=Asia/Shanghai - FLASK_ENV=production - PYTHONPATH=/app # 设置文件权限相关环境变量 - PYTHONUNBUFFERED=1 - APP_VERSION=0.15.0 restart: unless-stopped # 健康检查 healthcheck: test: ["CMD", "curl", "-f", "http://localhost:5000/api/health"] interval: 30s timeout: 10s retries: 3 start_period: 40s # 资源限制(可选) deploy: resources: limits: memory: 2G cpus: '4.0' reservations: memory: 1G cpus: '1'
这里面的文件夹映射,可以通过极空间查询路径的方法来映射。除此之外,咱们还得检查一下端口占用情况,要是发现有占用的,记得改一下。最后就是资源限制这方面,如果不想占用太多资源,自己设置个阈值就行。
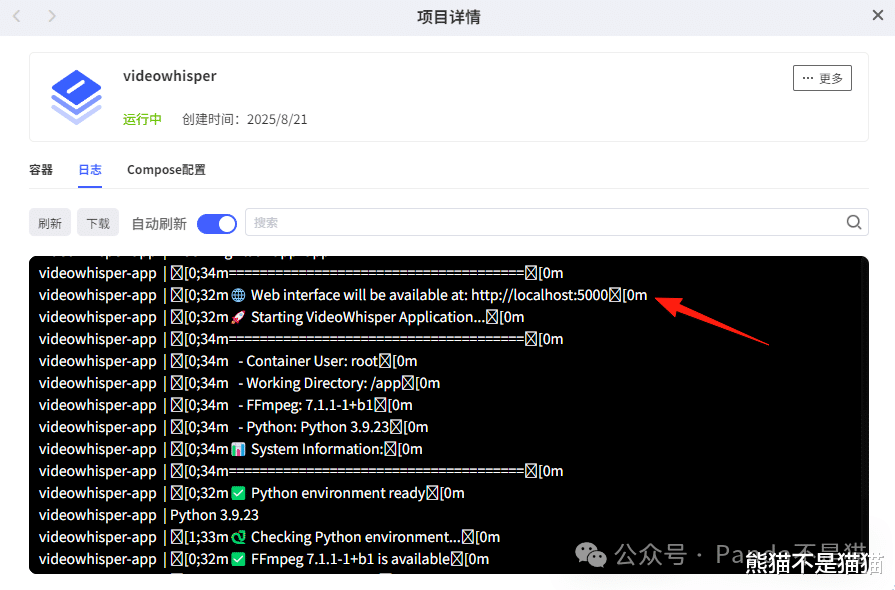
不管是通过极空间的远程访问,还是直接在浏览器里输入极空间 IP 加上冒号再加上端口号,都能访问项目的 Web 界面。项目没设置鉴权,所以千万别把它暴露到公网上用。
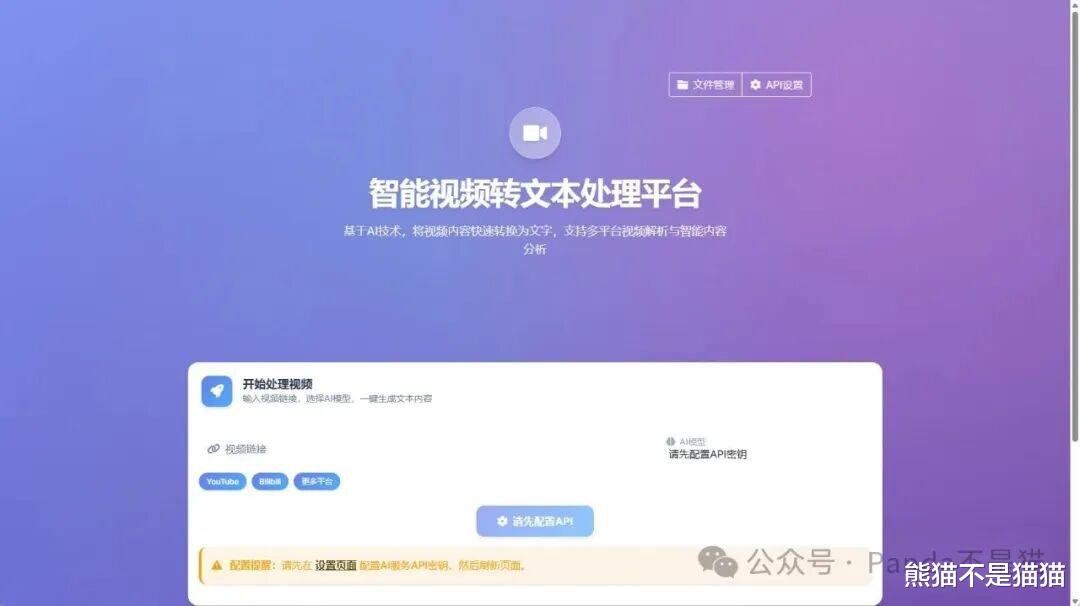
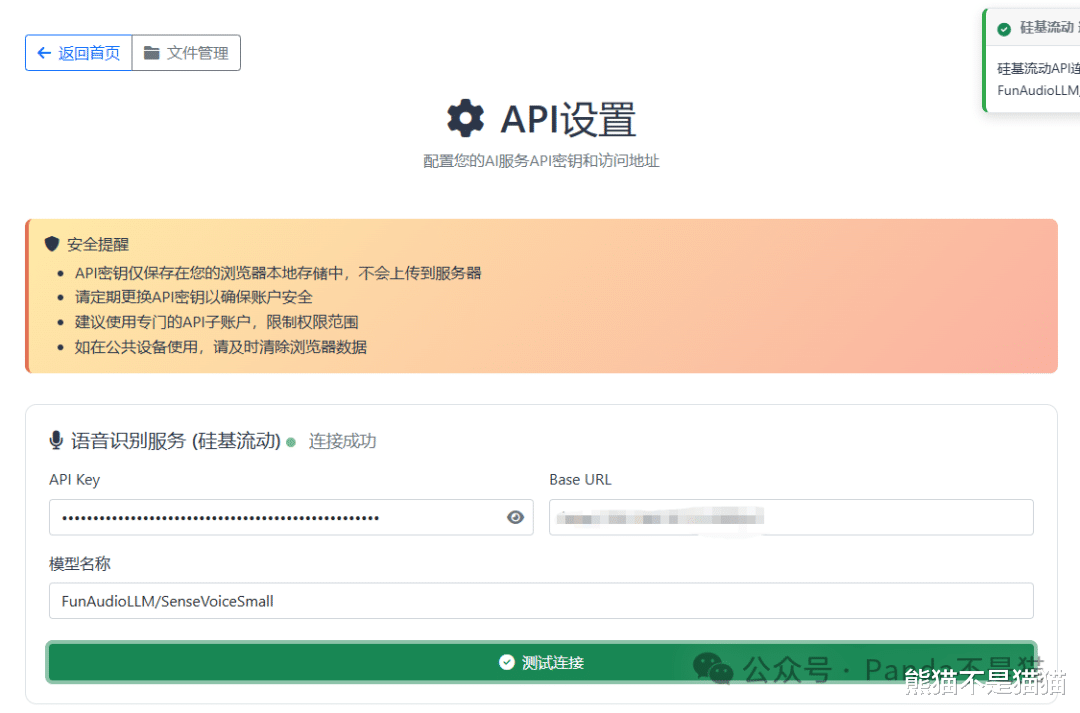
必填项填好以后,回到首页。这儿熊猫拿 B 站举例,把需要解析的 B 站视频链接复制下来,粘贴好,接着选择 AI 模型,再点击智能处理。这时候,项目就开始进行音频下载,之后会把音频分成几个片段来做语音转文字,最后对文字进行 AI 总结,还会优化格式再输出。
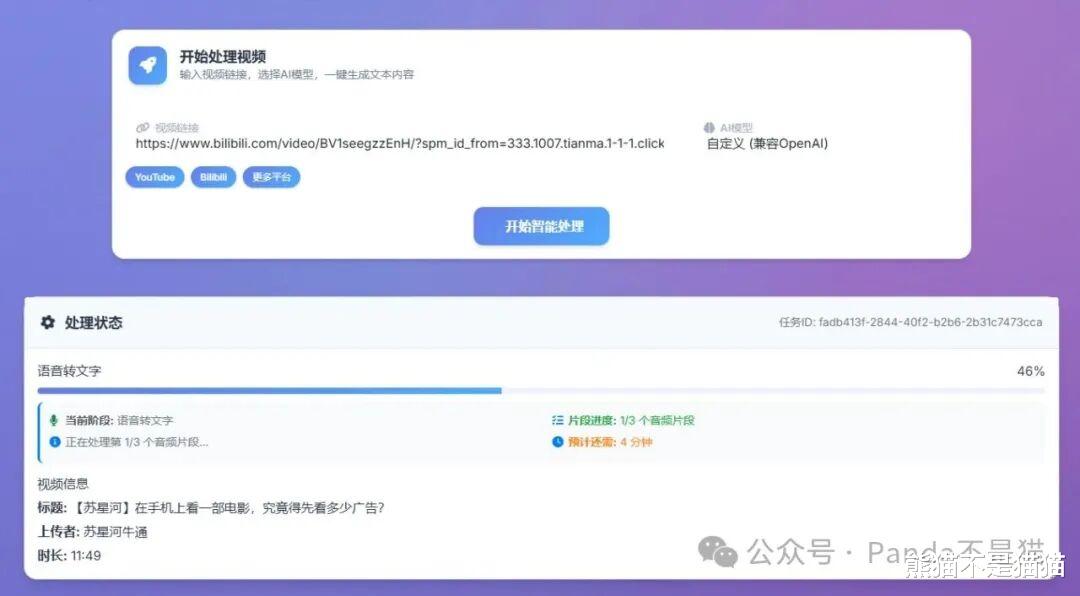
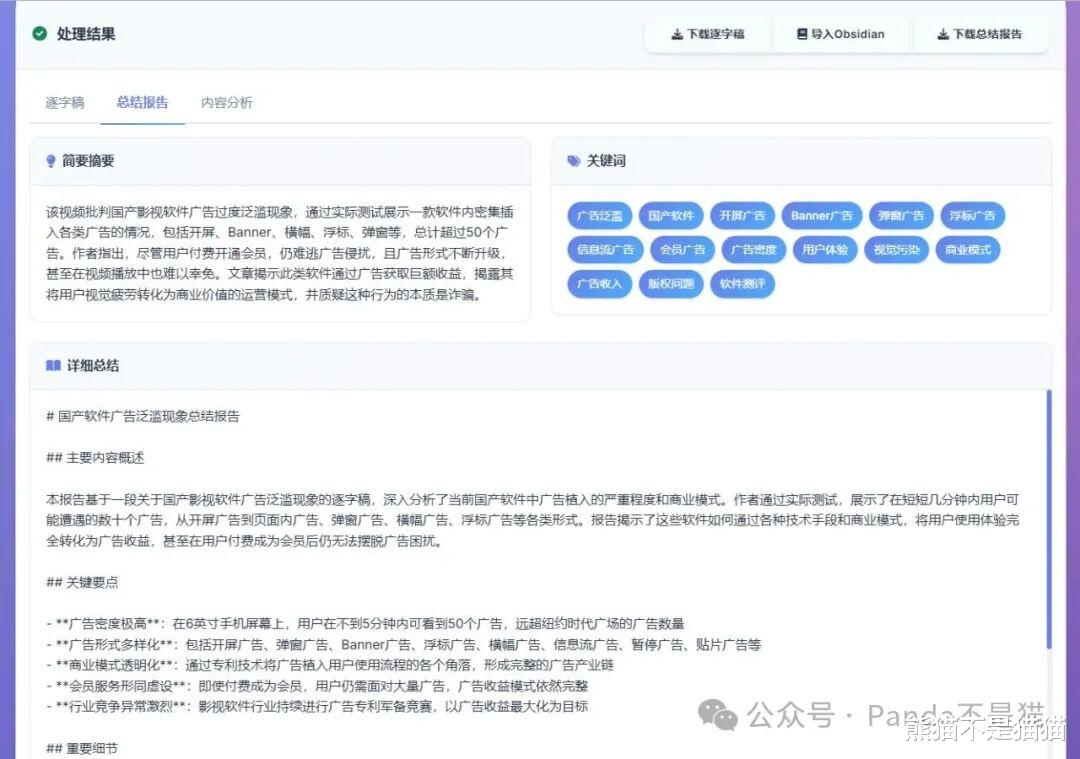
速度跟 AI 模型、项目性能设置,还有视频长短都有关系。输出的内容还挺好的,能把原视频里的重点基本都概括到。在处理结果里,你可以选择查看逐字稿、总结报告,还有内容分析,而且还支持下载。
项目挺好用的,不管是当成教程视频或者学习视频的总结工具,还是想给一些长视频做文字摘要,体验都不错。就算你没这方面需求,自己部署一个放着也没啥不行的,万一哪天有需要了,能马上拿出来用,毕竟技多不压身嘛。
