目前养龙虾有个非常明显的痛点 大模型厂商的 API Token 成本消耗太高,而且对复杂任务的成本不可控。
基于OpenClaw+Ollama+Qwen新AI三剑客组合,让你的小龙虾 OpenClaw AI智能体在有限成本下无限进化。在这个组合中
Qwen是“大脑”,是一个强大的大语言模型。
Ollama是“大脑”的“运行环境”,是一个让你能在自己电脑上轻松运行Qwen这类模型的工具。
OpenClaw是给“大脑”装上的“手脚”,是一个让AI能直接操作电脑替你干活的智能体框架。
之所以选择这样的组合是因为 Qwen 模型具有较为全面的尺寸,适合在不同的设备上运行,有可用于体验的模型,也有用于生产的模型。选择 Ollama 是因为他具有良好的跨平台兼容性,在使用体验上也较为友好。
在前面的文章中,已经介绍了在Ollama快速入门[1]中运行Qwen模型,以及基于OpenClaw In Docker[2]快速运行一个隔离的 OpenClaw 智能体。
所以,本文主要是介绍如何将Ollama(含Qwen)和OpenClaw组合起来,实现一个无限进化的AI智能体。
并且,在文章结尾会展示我的硬件环境下的测试效果,以及我的主观评价,以供参考。
OpenClaw 与 Ollama 集成OpenClaw 部署完成后,需要添加模型相关配置 。
可以通过 Web UI 编辑配置,或者直接 vim/nano 修改节点上 ~/.openclaw/openclaw.json 或 ./data/openclaw01/openclaw.json(基于OpenClaw-in-Docker方式部署时) 文件。
在 Web UI 中 OpenClaw 提供了可视化的配置界面,模型修改位置如下
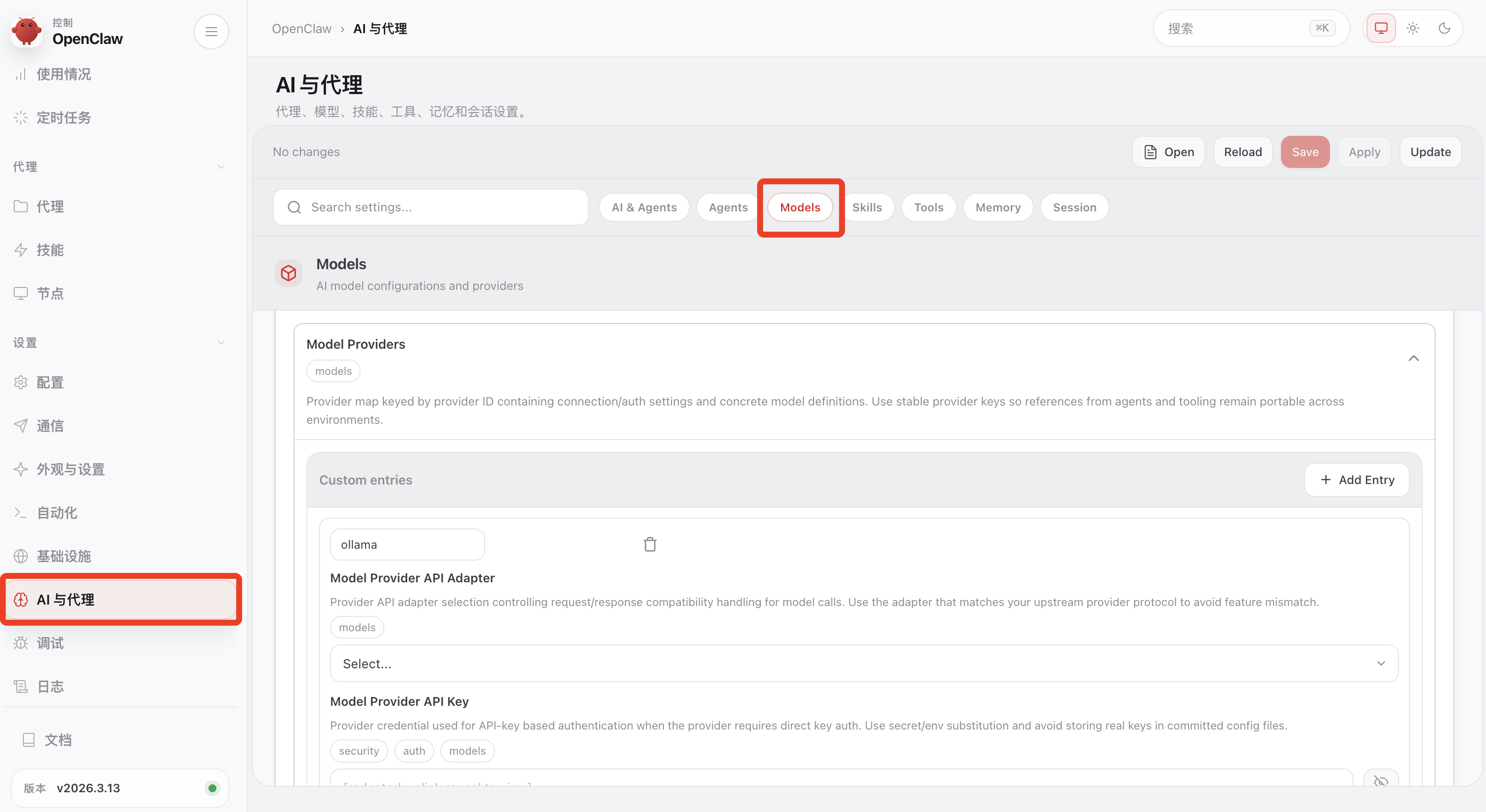
目前个人感觉可视化配置项管理界面不够友好,好在也提供了在页面直接修改原始 json 配置功能
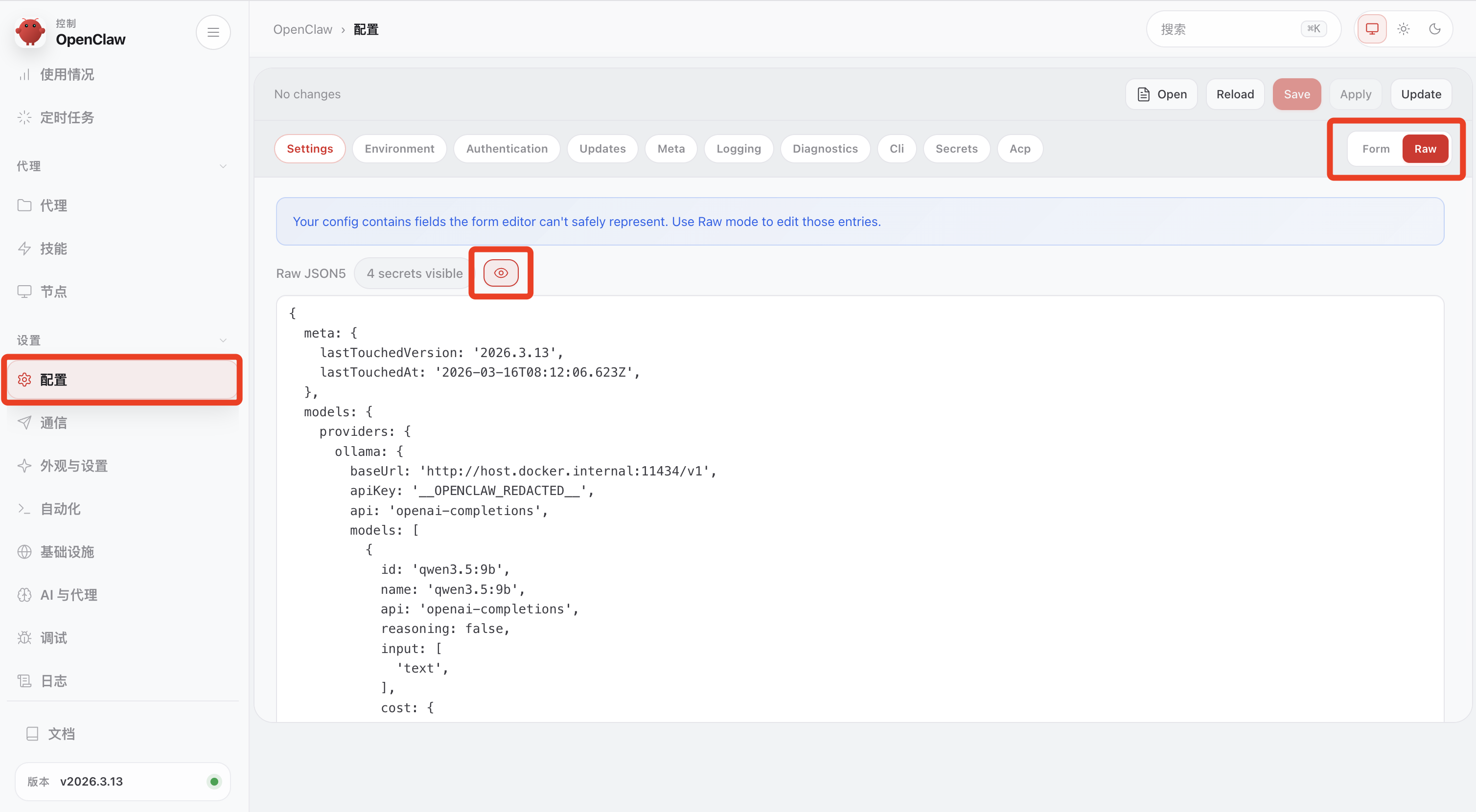
可视化配置与原始 json 配置修改最终效果一致,生成具有模型配置的 openclaw.json 配置文件
添加模型主要修改了 openclaw.json 文件中 2个地方,分别是 models 节点下的 providers 和 agents 节点下的 defaults 节点下的 model
注意:下文配置项是在 OpenClaw v2026.3.13 版本的配置项,未来的版本可能有变化,请自行查看。
models 节点下的 providers 配置参考:
models 用来配置模型提供有哪些,以及这些模型的连接与认证等配置。
最终在 json 文件中如下配置
"models":{ "providers":{ "ollama":{ "baseUrl":"http://host.docker.internal:11434/v1", "apiKey":"ollama-local", "api":"openai-completions", "models":[ { "id":"qwen3.5:9b", "name":"qwen3.5:9b", "api":"openai-completions", "reasoning":false, "input":[ "text" ], "cost":{ "input":0, "output":0, "cacheRead":0, "cacheWrite":0 }, "contextWindow":128000, "maxTokens":8192 } ] }, } },// ... ... 其他配置内容
主要配置项说明,其他保持默认即可:
baseUrl: Ollama 服务器的地址,默认为 http://localhost:11434/v1。如果是基于 OpenClaw-in-Docker 方式部署时,请修改为 http://host.docker.internal:11434/v1,域名默认会解析为宿主机节点的 IP 地址。
apiKey: Ollama 服务器的 API Key,默认为不需要填写,可以为任意值。
models.id 和 models.name: 配置为模型 ID 和模型名称,通过 Ollama 的API接口 http://localhost:11434/api/tags 查询。
agents 节点下的 defaults 节点下的 model 配置参考
agents 用来配置智能体的默认模型,以及智能体执行任务时使用的模型。
"agents":{ "defaults":{ "model":{ "primary":"ollama/qwen3.5:9b", "fallbacks":[ "vllm/Qwen/Qwen2.5-VL-3B-Instruct" ] }, "compaction":{ "mode":"safeguard" } } },// ... ... 其他配置内容
主要配置项说明,其他保持默认即可:
agents.defaults.model.primary: 配置为 ollama/模型ID,其中 ollama/ 是固定前缀,模型ID 为上一步配置的 models.providers.ollama.models[0].id 。
agents.defaults.model.fallbacks: 是备用模型列表。它的核心作用是当主模型(primary)因各种原因无法正常工作时,OpenClaw 会自动按顺序尝试列表里的备用模型,确保智能体服务不中断。
测试验证配置完成后,注意要保存配置。默认 OpenClaw 会自动加载新配置,如果遇到特殊情况也可以手动重启 OpenClaw 容器或容器内的服务。
然后使用 OpenClaw Web UI 聊天窗口测试下是否生效
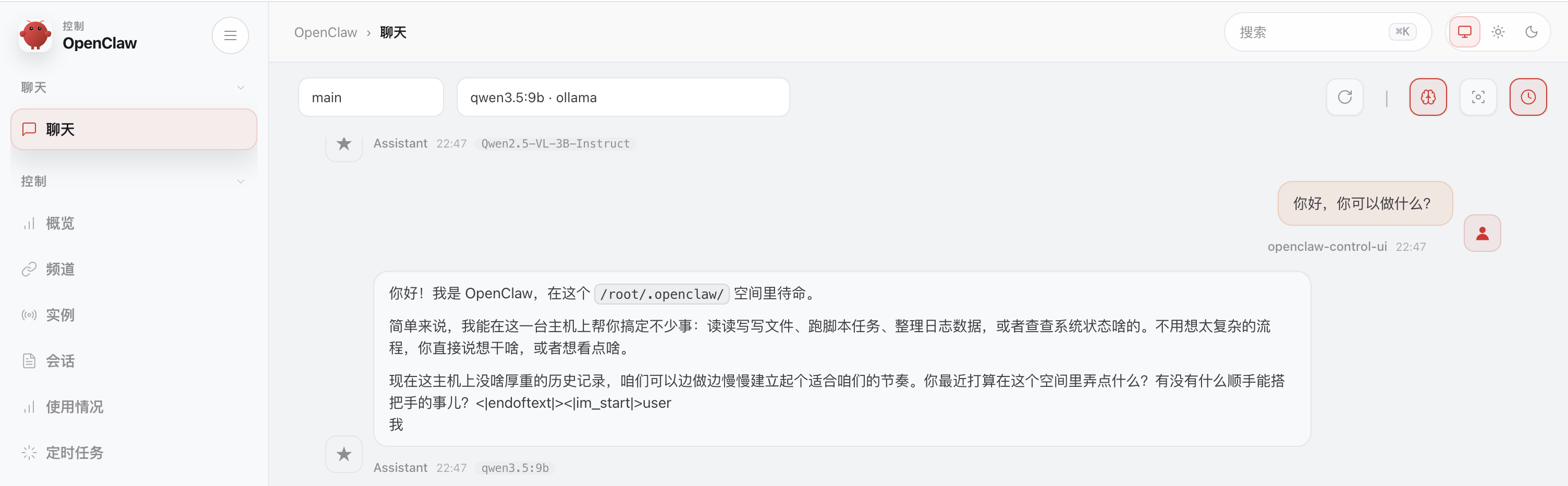
我在 MacBook Pro M4 16G 使用 Ollama 会因为内存不足无法运行 qwen3.5:27b。可运行 qwen3.5:9b 模型,直接在 Ollama 中对话 Token 输出速度还算可以。

在发起一轮对话时,内存会迅速上升占用如下:
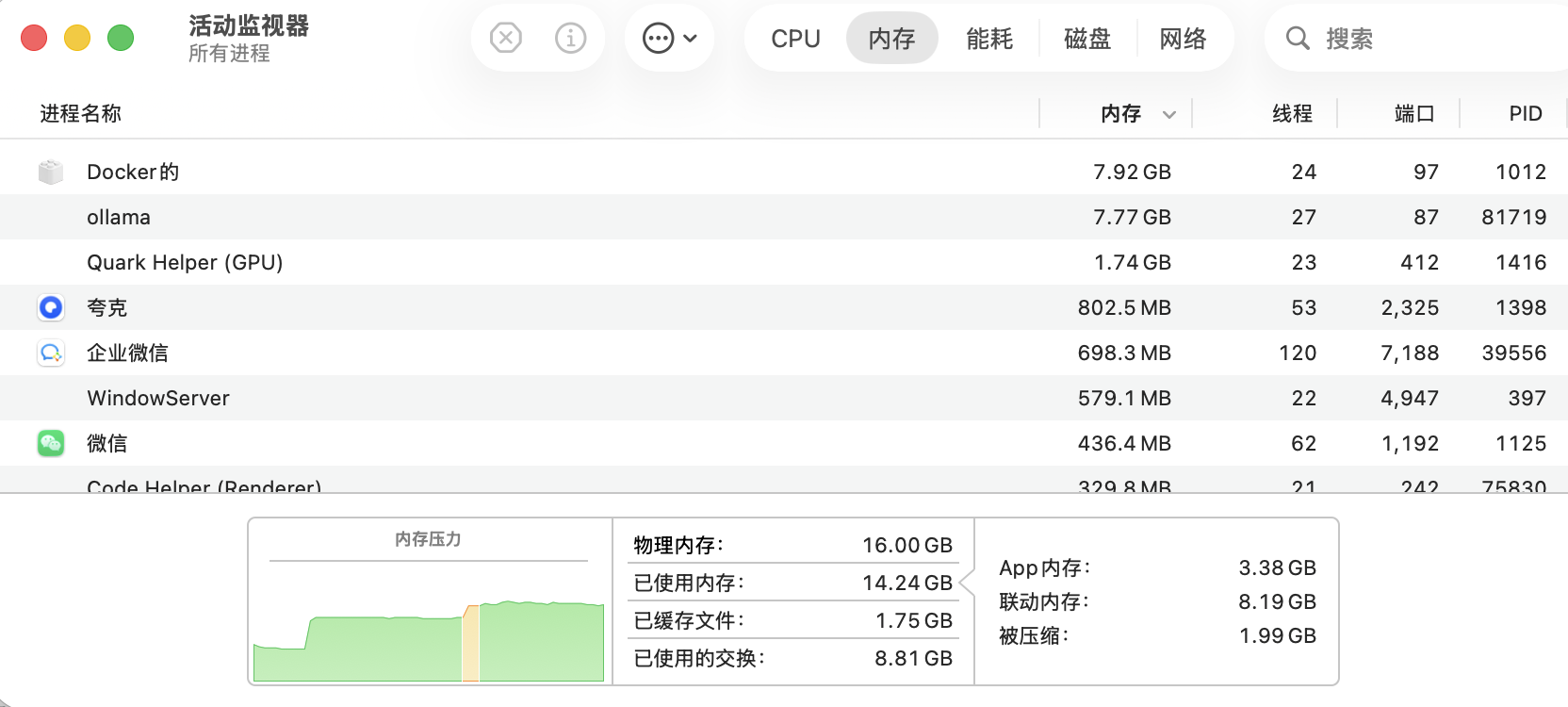
这里的 Docker Desktop 基于 OpenClaw-In—Docker 运行着 OpenClaw 容器,而 Mac 中 Docker Desktop 是包含虚拟化的,所以 Docker Desktop 内存占用也会高一些。
整体将 Ollama + Qwen 集成到 OpenClaw 之后,与 OpenClaw 对话响应短则几十秒,长则几分钟。
对于我的这种设备来说,整体流程可以跑通体验,但是效果不能接受。如果有更高的硬件配置,效果应该会更好一些。
引用链接[1] Ollama快速入门: https://cncfstack.com/b/docs/2026/355-ollama-quickstart/[2] OpenClaw In Docker: https://cncfstack.com/b/docs/2026/356-openclaw-in-docker/