今天,华为在上海2026国际电路与系统研讨会公布了“韬 (τ) 定律”,有些人在狂欢,感叹中国半导体行业出现如此巨大的进步,有些人不屑一顾,认为不过是现有的逻辑上的“总结”而已,只是一种营销手段罢了,那么事实真相到底是什么呢?直接来看原论文的内容,彻彻底底的分析一下,到底是一次技术突破,还是一些人口中所说的“噱头”。

先来直接看看论文的摘要部分:

摘要中说明:过去六十年,摩尔的几何缩放推动了半导体领域的进步。如今,这一产业契约已不再成立 :单纯尺寸缩小带来的收益已经趋平,先进芯片的设计预算已超过每颗 10 亿美元,而最 先进节点上的单晶体管成本也不再下降。本文主张一种继任的缩放原则,即 τ 缩放。它把 时间本身,而非晶体管面积,作为进步的首要度量,并以单一特征时间常数 τ 作为统一优 化目标,
摘要中说明:摩尔定律在先进制程工艺越来越难突破的情况下,芯片的造价越来越高,即需要一种新的继任摩尔定律的理论指导未来的芯片进步方向。
摩尔定律:集成电路上可容纳的晶体管数量,大约每隔18到24个月就会翻一番,同时成本会相对下降
摩尔定律告诉我们一个半导体的发展方向:不断的缩小晶体管的大小,提升晶体管的密度,获得更高的性能和更低的价格,因此,目前主流的芯片方向都是不断探索更低的制程,一路从14nm到2nm,光刻机也从DUV光刻机到EUV,为的就是不断提升芯片的集成度,但是,随着芯片的制程越来越逼近物理极限,一味的降低晶体管的大小,漏电现象会越来越严重,因此,可以预料到,摩尔定律总会有失效的一天,华为只不过是提前由于外部因素限制不得不面对这个现实而已。
论文中到底想要解决一件什么事情?论文主要介绍了两种情况:移动端芯片(Soc)和AI芯片,移动端芯片(Soc)受限于手机等产品的大小限制,极其依赖单芯片的性能,换句话说,极其依赖制程提升带来的性能提升,可想而知,一旦制程无法突破,手机的芯片的性能将会陷入一个缓慢的发展期;AI芯片方面,涉及到几万卡,几十万卡的互联,芯片跟芯片之间的通信延迟极大的阻碍了芯片的效率,迫切需要新的方式能够更好的互联几十万卡的集群。

本文认为,未来十年的电子系统演进不应由几何缩放主 导,而应由时间缩放主导,即在堆栈每一层系统性降低单一特征时间常数 τ,从皮秒级开 关晶体管到秒级响应的数据中心工作负载。
论文中主要想要解决的问题是,通过一种新的方式来“继任”摩尔定律,并非取代,让移动芯片可以不强烈依赖制程的提升也能持续发展,AI芯片可以超大规模的进行互联,将延迟降到最低,并且得益于华为过去几十年的芯片研究,在移动Soc和AI芯片上都有相关的技术积累,所以提出了解决的办法。
移动端Soc解决办法先看看原文如何表述:

若还原到对终端用户的本质影响,摩尔定律从根本上说从来不是关于几何。更小的晶体管 之所以提升系统性能,是因为它们开关更快。更高密度的互连之所以提升性能,是因为信 号跨越的距离更短。更高的集成度之所以提升性能,是因为数据跨越的边界更少。每一代 技术本质上交付的都是时间的缩短:器件层从皮秒到纳秒,芯片层从纳秒到微秒,系统层 从微秒到秒。空间缩放只是压缩时间的工具。 一旦认识到这一点,一个自然的重新表述便出现了。时间本身应当被采纳为首要度量。可 以在堆栈的每一层定义一个特征时间常数 τ,即晶体管、电路、芯片和系统,并把降低 τ 视为统一优化目标。于是,几何缩放只是降低 τ 的众多技术之一,而不再是唯一技术。
此处提到,制程的不断提升,本质上还是在解决“时间”的问题,表象上看到的“空间”根本不是摩尔定律的核心价值,通过先进制程获得的性能提升,只是降低 τ 的众多技术之一,而不再是唯一技术。举个例子,牛顿定律,在小尺度的场景下很好用,但是一旦放到宇宙的尺度就会失效,爱因斯坦的相对论提出之后,大家才发现,牛顿定律只是相对论在特殊情况下的近似,上文同此。
知道这一点之后,文中又提出了相关的影响层级

最终得出结论:
使 τ 成为有用的首要指标,而不是对既有指标的重新命名,关键在于它是贯穿整个堆栈的 同一个指标。频率、时延、带宽和吞吐量在各自层级上都受 τ 支配。工艺技术专家、电路 设计师和系统架构师可以用相同单位讨论同一个量。τ 是实现端到端堆栈协同优化的语言 ;各层独立优化、再把时序作为剩余结果处理的时代已经结束。
结论中可以看到,整个设计的最终优化目标是为了优化“τ”,而不是再是每一层独立优化,当然,论文中提出了具体的例子,在移动端Soc的优化上,使用的方法叫“LogicFolding”,逻辑折叠。
什么叫“LogicFolding”Definition. LogicFolding is a design methodology that partitions digital
论文中指出,“逻辑折叠”是一种设计方法论,并不是具体的晶体管设计,还是布线设计等等,是一种方法,类比传统的写代码,把所有的代码文件写在一个单文件中是可行的,但是按照分层架构来写,比如MVVM更加推荐,MVVM就是一种设计方法,为的是实现最终的项目可维护,但是每个层级叫什么由设计者决定,你可以叫“model”,也可以叫“ABCD”,都随意,但是在设计的时候要注意按照MVVM的设计方法来即可(当然这个类比不够准确,但我想不到其他的好的类比方法了,芯片设计比写代码复杂得多)。
“LogicFolding”也是这样的,按照时间缩放原则,将数字、模拟和存储电路 划分到垂直堆叠的有源层中,从而联合优化性能、功耗和面积。以此达到不依赖先进制程也能稳步提升性能的效果。文中举了实例来论证:

在麒麟2026上得到了验证:
• 晶体管密度在单代内从 155 MTr/mm² 阶跃式提升到 238 MTr/mm²(晶体管密度按公式 2/(CPP × cell height) 计算;Kirin SoC 设计的面积利用率为 68%)。这种提升幅度过去需要三年的几何缩放才能实现。
• SoC 性能核能效提高 41%,最高时钟频率提高近 13%。
• 跨上、下两层构建的高速全局片上网络数据路径,使数据路径占用面积减少 55%,同时 改善了供电稳定性。
• 一种硅后时钟偏斜调整方案独立贡献了超过 5% 的 SoC 性能提升。
• 在 SRAM 上,由于访问速度、单位比特能耗和面积强烈依赖位线与字线长度, LogicFolding 缩短了关键路径,降低了单位比特能耗,并使工作频率提高超过 40%。
• 在一个代表性处理核心上,双层折叠架构使时钟缓冲器数量减少超过 50%,时钟偏斜降 低 25%,线长约减少 30%。

可以看到,从麒麟9030Pro到麒麟2026所带来的性能提升,不是依靠摩尔定律就能实现的,充分的体现了“LogicFolding”的有用性,同时,可以看到到2030年,频率将突破5GHz,在无法获得最先进工艺的情况下,提升频率并不是一件容易的事情,但是目前看来似乎确实是可以做到的。
当然,文中还特意提到了一句:

Kirin 2026 中采用的 LogicFolding 实现刻意保守。混合键合间距达到 1.5 μm;TSV 落点 只比顶层金属向下推进一步;折叠也只是沿若干关键路径选择性应用,而非覆盖整个设计。 即便如此,今年 CPU 性能核频率仍回到 3.1 GHz
只是在部分关键的地方进行了优化,但是依旧把频率提升到了3.1GHz,可以想像,如果整个设计中全部优化,那么应该就是麒麟2027了。而且附带了未来的麒麟芯片演进图:
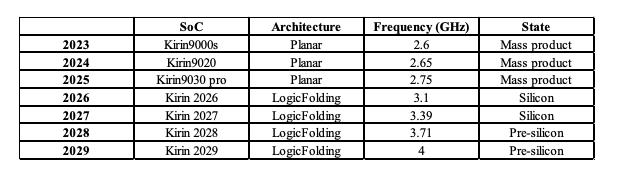
麒麟2026已经量产了,麒麟2027也已经流片了,静候佳音即可。
AI芯片的解决办法根据上方的分析,完全可以自然而然的想到,把每一个AI芯片都按照“LogicFolding”来设计,可以显著提升单颗芯片的性能,文中也提到了:

把 τ 视为系统级目标,并在整条链路上应用,而不是只在单个加速 器内部应用
τ 缩放通过三个协同层落地:系统互连网络(Unified Bus)、近封装光引擎 (Hi-ONE),以及对封装本身进行拓扑重组(3D Folding)。
AI芯片,往往需要组建超大规模的集群,这样,芯片和芯片之间的时延也是不可忽视的优化路径,文中提到了三种优化的方法,准确的来讲应该是四种:系统互连网络(Unified Bus)、近封装光引擎 (Hi-ONE),以及对封装本身进行拓扑重组(3D Folding)以及单芯片的优化。这里就不再展开赘述了。
现在开始解答很多人的疑惑:这不就是3D封装?不是已经有很多厂家在搞了吗?华为这难道不是整合了一下大家的理论然后“打标签”说是自己的吗?
3D封装是什么,现有技术是如何延续摩尔定律的?所谓的3D封装,是将多个芯片的die垂直封装到一起,中间通过硅穿孔等等技术,降低芯片之间的通信时延,提高性能,这里就有一个问题:多个die封装的时候,这些die已经被设计好了,设计的原则还是传统的设计原则,只是在封装方面进行了创新,并没有摆脱传统的摩尔定律(单个芯片设计的时候依旧无法避免触碰到制程的极限,改进的只是封装方式,并非芯片设计)。芯片设计上不是以“τ缩放”为最终的目的。
华为提出的,是一种全新的设计模式,在芯片设计的时候,就以“τ缩放”为设计目标,所有的系统的设计,都有一个共同的语言,那就是“τ缩放”,每一层级之间的相互依赖,最终都是以“τ”为表征的,举个例子,传统的芯片设计,设计的目的是为了通过先进封装获取更高的频率,最终体现的结果也是频率,每个层级都是在分层优化,体现在最终的结果“频率”上。
但是华为设计模式从始至终都是以“τ缩放”为统一的“语言”,设计完成后,最终的结果体现在“τ”上,最终的效果是这样的:因为设计完成后整个系统的“τ”更低,因此体现出来的结果是更高的频率,更好的性能。
提出这个理论后,别的厂家不是很容易复制吗这是很多人另一个疑惑的点:华为的理论“看起来”就像3D封装之类的技术,那么其他的厂家,比如NVIDIA,高通,台积电等等厂家,不是很轻易的就可以复刻了吗?事实并非如此,结合上面的说法,华为提出的压根就不是所谓的“3D”封装,所谓“3D”封装也只不过是“空间缩放”的一种表现形式,华为要做的是“时间缩放”,是要以优化整个系统的“τ”为最终目标,论文中也提到了:

把 τ 缩放描述成一个已经完成的系统将具有误导性。仍有若干实质性问题有待解决,本文 在此列出,既是为了说明正在进行的工作,也是为了邀请合作。 工具链与方法论。当今 EDA 是在这样一个时代发展起来的:面积、时序和功耗沿三个独 立轴优化,系统 τ 则作为剩余结果出现。全规模 LogicFolding 要求工具链把多个堆叠裸 片视为单一连续设计实体;它需要在单元粒度而非模块粒度划分逻辑,在统一成本函数下 跨整个体积进行布局,并在芯片间路径上完成时序收敛。在这些路径中,垂直互连寄生、 KOZ 排除和晶圆间工艺变异相互作用,而传统以 2D 训练的工具无法充分处理。初步内部 工具已经开发出来并能产生有用结果,方法论细节将在未来数月发布。一个 τ 原生、开放、 多物理场且原生 3D 的工具链,是未来十年最重要的使能投资。
为了实现“时间缩放”,需要从EDA软件,晶元加工等等全产业链的共同协作才能实现,让EDA软件原生就有“3D”设计能力,目的是为了替代“传统”的EDA工具链,这是华为无法获得先进制程之后,“被迫”探索出来的一条“新路”,依靠全产业链的把控,华为可以现在就开始验证这套理论的效果如何,其他的厂家想要追赶,那么就必须要从EDA软件,晶元加工等等都要一起改变,所以,短期内想要复刻华为的模式显然是不太可能的。
总结:“韬 (τ) 定律”是一次彻彻底底的产业变革,覆盖上下游全套产业链,是实打实的技术创新,绝非一些人口中的“噱头”综上所述:华为提出的“韬 (τ) 定律”,是一次实打实的技术变革,绝非一些人口中的“营销噱头”,而是需要整个产业链——从EDA工具,晶元加工,封装等等全产业链共同努力的变革,最后,放一段原论文的结尾,结束这篇文章:
The next ten years of work are scoped. Many open questions remain, and no single organization can address them alone — the toolchain, the standards, the benchmarks, the device physics, and the economic models all require contributions from beyond any one company. This perspective is therefore intended as both a report from the field and an invitation. The roadmap ahead is demanding, but the direction is unambiguous
“未来十年的工作范围已经清晰。许多开放问题仍然存在,且没有任何单一组织能够独自解决它们:工具链、标准、基准、器件物理和经济模型,需要来自所有企业的贡献。因此,本文既是来自一线的报告,也是一次邀请。前方路线图要求很高,但方向明确无疑。”
独行易,众行远,不断的突破极限,才能在最后的生存竞争中活下来!