明明只是调整了一个字段命名,却导致下游好几张核心报表报错。
业务找你质疑数据准确性,结果翻遍文档也说不清数据的来龙去脉,最后只能拉上多个部门开扯皮会。
出现这样的问题,都是因为没有建立起规范的数据血缘。
你肯定要问数据血缘是什么?今天这一篇文章,就带你把数据血缘这个概念搞清楚,教你一步步搭建能用、管用的数据血缘体系。
一、数据血缘到底是什么?
简单来说,数据血缘就是记录和展示数据“从哪里来,经过哪些加工处理,最后去了哪里”的完整脉络图。
每一个环节源数据、处理任务、加工后的表、字段、乃至最终的报告,都是这个血缘网络上的一个节点。而数据在这些节点间的流动关系,就是连接它们的边。记录下所有这些节点和边的来龙去脉,就是数据血缘在做的事。
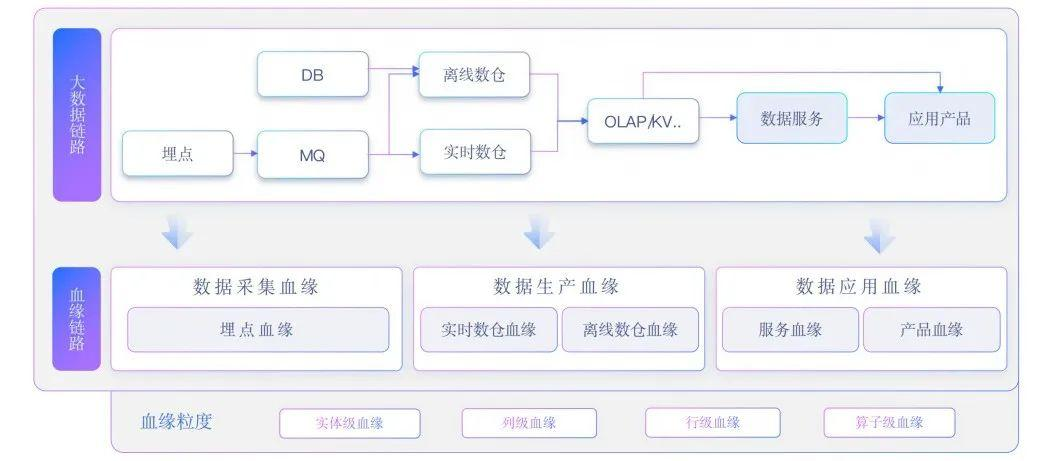
数据血缘的核心四大维度
1、上游溯源。说白了,就是能顺着数据链路,追溯到最原始的数据源。这是数据血缘最基础的要求,连源头都找不到,后续的一切分析都是空谈。
2、加工记录。数据从源头到最终应用,中间会经过无数次ETL加工、SQL计算、报表层二次处理,甚至是手工整理的Excel数据。加工记录就是要把每一步的加工逻辑、加工工具、加工时间记录清楚。有了这些记录就知道数据中间被改过什么,自然就能判断数据的准确性。
3、下游影响。它指的是一个字段或一张表被修改后,会直接影响哪些下游的表、报表、API接口甚至是业务系统。
4、责任归属。责任归属要求数据链路的每个关键节点,都必须明确唯一的责任人。这个责任人要负责该节点的数据质量、变更管理、问题处理。
二、数据血缘的三种粒度怎么选?
数据血缘的粒度需要根据企业的不同业务进行选择。
1、表级血缘
表级血缘只记录表与表之间的依赖关系,不关注表内字段的具体关联。
这种粒度的优势是投入成本低、落地快,适合数据血缘建设刚起步的企业,能快速覆盖大部分数据变更的影响评估需求。
2、字段级血缘
字段级血缘是记录字段与字段之间的关联关系,能精准定位到具体字段的来源、加工和影响。
比如报表的收入字段来自数仓中间表的revenue字段,而revenue字段又来自业务订单表的order_amount字段。这种粒度的实施成本是表级血缘的3-5倍,适合数仓体系成熟、已经完成表级血缘建设,需要精细化分析字段变更影响的企业。
3、值级血缘
值级血缘是记录行级数据的关联关系,能追溯到具体某一行数据的来源,适合金融、医疗等强监管行业,有严格的审计追溯要求的企业。
三、血缘系统到底长什么样?
数据血缘的落地需要一套完整的架构体系,从数据采集到最终应用,层层递进,缺一不可。
1、采集层
采集层的核心任务是把分散在各个系统中的数据血缘关系采集出来。企业的数据链路散落在数仓、业务系统、ETL工具、报表平台、Excel文件等多个地方,采集层需要覆盖这些所有的数据源。
2、存储层
采集到的血缘数据需要用合适的方式存储,才能支撑后续的查询和分析。
存储层的核心是采用图模型存储,同时要支持多层级穿透查询,保留血缘的版本快照,记录不同时间点的血缘状态,方便后续对比和追溯。
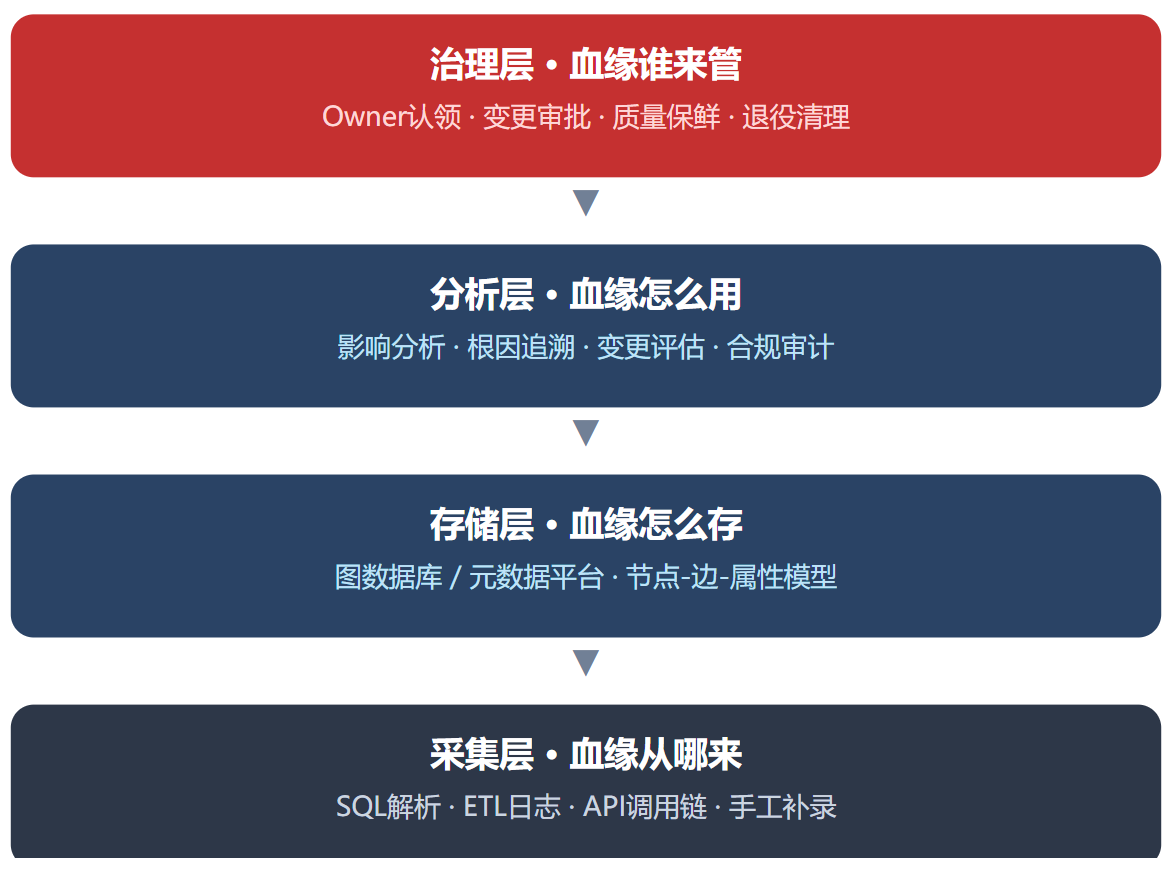
3、分析层
血缘数据采集存储后,最终要落地到使用场景中,这就是分析层的核心价值。
变更影响评估,改一个字段或表时,自动查询下游影响范围;
根因追溯,数据异常时,沿血缘链路逐层定位问题节点;
变更评估,统计上线涉及的血缘链路数量和影响范围。
分析层的价值能否发挥,完全取决于治理层的责任归属,没有责任人,分析结果就没有对应的处理主体。
4、治理层
血缘图谱不是一成不变的,数据链路会不断变化,没有治理层,血缘图谱很快就会变成过期的无用数据。
治理层的核心是明确责任归属,给每个关键节点指定唯一的Owner,改数据前必须查询血缘并通知下游Owner,定期做血缘准确率巡检和废弃数据的清理。
四、从0到1怎么建数据血缘?
1、
不用一开始就梳理全量数据链路,先聚焦企业最核心的20张报表。
比如CEO、CFO每周必看的经营报表、财务报表。画出这20张报表的链路草图,从报表一直追溯到最源头的ODS层或业务系统表,确保每条链路至少追溯到核心数据源。
2、
团队内部要先统一认知,明确什么是数据节点(表、字段、报表、API、Excel等),制定统一的节点命名规范和Owner认领模板。
先在一个业务域试跑,确保标准和模板落地后再推广,避免后续出现认知分歧。

3、
启动血缘采集工具,自动采集数仓、ETL工具等标准化环节的血缘数据,输出自动采集覆盖率报告。
对于工具无法采集的存储过程、Excel搬运等环节,组织人工补录,明确补录的链路和责任人。
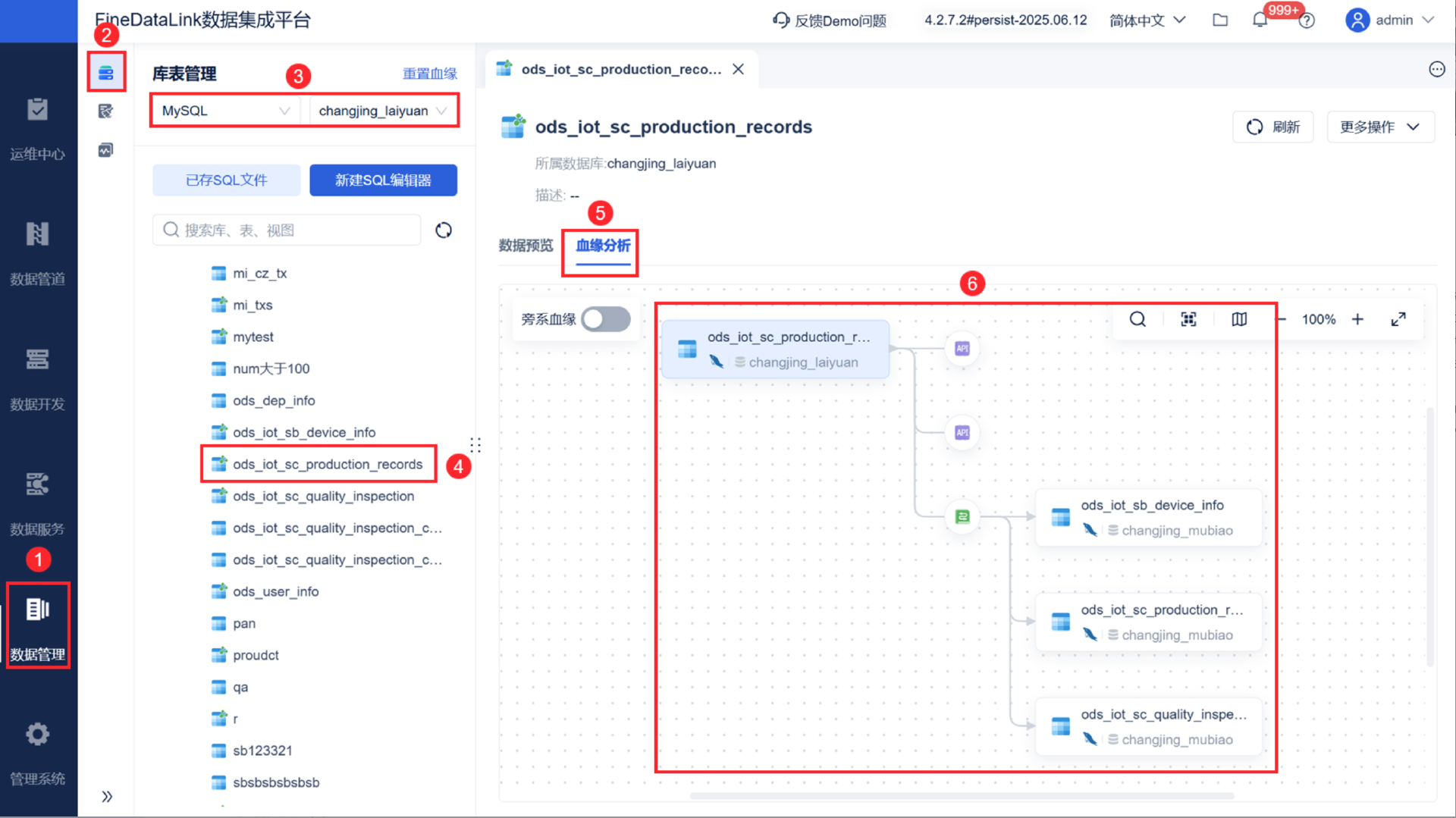
分享一个我们团队正在用的血缘采集工具FineDataLink ,它不仅能自动解析主流数仓的 SQL 脚本、对接 Informatica、Airflow 等常见 ETL 调度工具,还支持实时与离线双引擎采集,高并发场景下也能稳定同步数据,表结构变更同步自动捕捉,不用手动跟进。更省心的是它有断点续传功能,遇到网络中断或数据源故障也不用重新采集,大大降低重复工作量对于工具无法采集的存储过程、动态 SQL、Excel 手工搬运等场景,它也提供了直观的手工补录入口,支持批量录入链路关系并标注补录人,方便后续追溯核对.
4、
明确唯一的Owner,这一步需要拉上业务和管理层协同,让Owner认领成为制度。
没有管理层的推动,Owner认领很难落地,血缘的责任归属也就无从谈起。
5、
血缘不是一次性的项目,要变成团队的日常习惯。
把血缘查询嵌入数据变更审批流程,改数据前必须查询血缘并评估影响。建立季度血缘巡检机制,定期检查血缘准确率。
最后总结
数据血缘的核心不是采集多少数据、建多复杂的图谱,而是把数据的来龙去脉记录清楚,把每个节点的责任落实到人。从核心链路开始,定义标准,采集信息,落实责任,最后融入流程,它是一个需要持续投入,但效果是长远的,它能带来更少的问题排查时间,更可靠的数据变更评估,更顺畅的数据沟通文化,让数据真正成为一个可信、可用的资产。