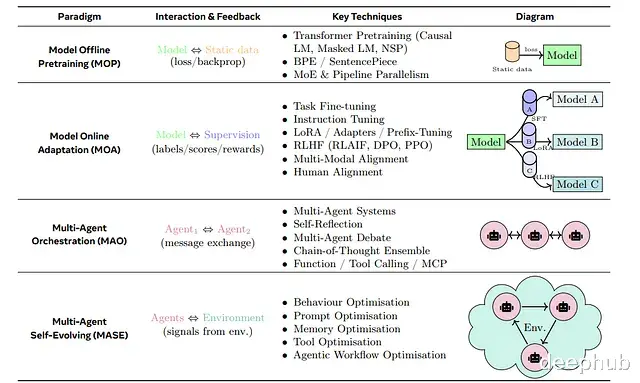
传统AI智能体有个老问题:部署之后就"定住了"。工程师手工打磨的提示词和规则,遇到新场景就容易失灵,性能曲线到达某个点后趋于平缓。而自我进化智能体(Self-Evolving Agent)的思路就是打破这种静态模式——让智能体在运行过程中持续收集反馈,自动调整自身策略,形成一个闭环:执行任务 → 获取反馈 → 自我调整 → 继续执行。
这套机制把基础模型的能力与在线学习结合起来。用更学术的表述,自我进化智能体是"通过与环境交互持续优化内部组件的自主系统,目标是适应变化的任务、上下文和资源"。比如说这类智能体不只是做题,还会批改自己的作业、找出哪里写错了、然后调整学习策略,整个过程不需要人类介入。

上图展示了典型的反馈循环结构。基线智能体执行任务产生输出,由人类评审或LLM评判者打分,反馈信息(分数、错误描述、改进建议)汇总后用于更新智能体,可能是调整提示词、微调参数、或修改配置。这个循环反复执行直到达成性能目标。
与固定配置的传统方案相比,自我进化智能体的核心差异在于能够监控自身表现并主动适应。多数已部署的智能体依赖人工设定的规则或提示,无法跟上数据分布的漂移或任务需求的演变。反馈循环解决了这个问题:每次任务完成后收集评估信号,识别薄弱环节,针对性地更新智能体。长期来看,系统的准确性和泛化性都会持续提升。这种机制对需要高准确率或面对动态环境的场景尤为关键,人类的角色从逐条修bug变成了设定目标和把握方向。
从架构视角看,自我进化系统可以抽象为四个核心要素:输入、智能体系统、环境、优化器,它们在迭代循环中交互。最近有综述将这类系统正式定义为"持续优化内部组件的自主系统,在保持安全性的前提下适应变化的任务与资源"。实际运行时,智能体执行标准的感知-推理-行动循环,但增加了自我评估和参数优化的元步骤。

反馈循环的运作方式:从基线智能体开始(比如一个执行文档摘要的Agent),人类或LLM评判者对其输出进行评估。反馈信号既包括定量指标(0-1评分)也包括定性评论("摘要漏掉了关键细节")。多个信号汇总成综合得分,如果得分低于阈值(假设是0.8),就调整提示或策略重新测试。新版本达标后替换旧版本,循环继续。几轮迭代下来,智能体具备了自我修复能力。
这种设计的优势在于可扩展性(用LLM评估替代昂贵的人工标注)和适应性(自动响应新的失败模式,不需要手动改代码)。但也需要明确的安全约束:智能体在进化过程中必须保持稳定性(变化时不引入安全隐患)和性能单调性(不允许任务效果下降)。
自我进化循环的核心步骤OpenAI Cookbook里有个经典示例,把进化循环拆成四步:
第一步,基线智能体:准备一个初始版本,比如用特定提示词做文本摘要的Agent。
第二步,收集反馈:让智能体跑一批任务,收集输出的评价,人工打分或者"LLM-as-Judge"的自动评分都行。评估内容包括摘要是否准确、是否简洁、是否符合业务规则等。
第三步,量化评分:把反馈转成可度量的指标。可以是规则校验器、也可以是GPT评分标准,最后合成一个综合质量分。
第四步,更新优化:如果得分没达标,就调整智能体内部——优化提示词、微调参数、或者换一个更好的版本,然后重新跑循环。
循环持续到性能超过阈值或达到重试上限。
agent = BaselineAgent() score = evaluate(agent) while score < target_score and tries < max_retries: feedback = get_feedback(agent) agent = optimize_agent(agent, feedback) score = evaluate(agent)
每轮迭代都用收集到的反馈调整智能体。如果优化成功,新版本替换旧版本,成为下一轮的基线。
关键模块解析自我进化智能体由几个紧密耦合的模块构成。
智能体循环是最核心的部分,智能体接收输入(比如文档片段),更新内部记忆或上下文,运行LLM推理,产出结果(比如摘要)。这个流程通常用某种Agent SDK实现,负责管理LLM调用和工具使用。自我进化层包裹在外面,根据需要触发重跑或修改循环。架构上可以是单模块也可以是多模块——比如医疗场景可能同时有Summarizer和Compliance Checker两个子智能体。持续的"思考-行动"循环产生可评估的输出,为后续改进提供素材。
任务性能监控负责追踪智能体的表现,典型配置包括自动评估器和可选的人工复核。以摘要任务为例,每个输出会经过四个评分器检查:
(1) Python函数检查关键术语(如化学名称)是否保留在摘要中;(2) 长度检查器控制冗长度;(3) 余弦相似度检测摘要与原文的语义一致性;(4) LLM评判者按评分标准给出综合评价。
前两个是确定性规则,第三个是模糊匹配,第四个提供灵活的语言理解评估。多个评分器协作,既产出量化分数也生成定性反馈。监控模块输出数字分数或pass/fail标志,外加描述问题的反馈文本。加权平均后得到汇总分数,决定输出是否可接受。这个监控信号驱动整个改进流程。
内存模块对持续学习,短期记忆存储当前对话和规划状态,长期记忆保存累积知识、历史解法、总结出的规则。RAG(检索增强生成)让智能体能从知识库中拉取相关上下文。更复杂的系统会维护"记忆库",存放过去的决策和推理轨迹。记忆帮助智能体保留学到的经验:比如记住哪些提示模式效果更好,或者存储之前遇到的拒绝案例。进化循环可以把反馈和结果写入记忆,后续迭代查询时就能避免重蹈覆辙。
奖励/反馈建模把原始反馈转换成训练信号,对于LLM智能体,通常会构建奖励模型或评分函数。每个评分器产出0-1分数,系统检查是否过阈值(比如0.85)。多个分数可以合并成单一指标(比如取均值),这个综合分数就是智能体的"奖励"。用强化学习的视角看,智能体被优化来最大化这个奖励。反馈也可以定性分类:如果某个评分器挂了,失败原因可以转成纠正指令。LLM评判者特别有用,因为它提供自然语言反馈("摘要需要更多细节"),智能体能直接用这些描述来改进输出。总之,奖励模块确保优化目标清晰——"所有评分器通过,或者均分超过0.8"。
重训练/优化模块在性能不达标时更新智能体,提示词调优、参数微调、结构变化(如添加新工具)。一种常见做法是用LLM做提示改进而非直接训模型——"MetaPrompt"智能体拿到当前提示和反馈,被要求生成更好的版本。代码用新提示替换旧提示。更进阶的系统可能在收集的(输入,输出,反馈)数据上微调LLM,或用强化学习更新策略权重。核心思想是:根据反馈修改智能体内部组件(系统提示、模型权重、工具配置),让下一次执行有更大成功概率。重训后循环再次评估更新版本,形成闭环。
自我进化智能体的反馈主要靠自生成或众包。系统在一批任务上跑智能体,收集性能数据,包括:
分数和标签:输出是否满足长度约束?是否包含必需实体?这些由自动检查器记录。
文本反馈:LLM评判者输出解释性语句,说明哪里不足。
日志和诊断:生成的token数、运行时统计、错误堆栈。
人工标注:如果有人工复核,评级和评论会被记录。
智能体生成摘要后,评估代码调用各评分器,把输出解析成结构化结果(评分器名称、数字分数、pass/fail、推理描述)。辅助函数如parse_eval_run_output提取这些信息。智能体不依赖外部数据——自己的输出就是训练数据。随着时间推移,这会积累起(输入,输出,反馈)三元组的数据集。
import time import json def run_eval(eval_id: str, section: str, summary: str): """使用输入部分和输出摘要创建评估运行。""" return client.evals.runs.create( eval_id=eval_id, name="self-evolving-eval", data_source={ "type": "jsonl", "source": { "type": "file_content", "content": [ { "item": { "section": section, "summary": summary, } } ], }, }, ) def poll_eval_run(eval_id: str, run_id: str, max_polls = 10): """ 轮询评估运行直到完成或超时。 此函数的存在是为了通过定期检查运行状态来处理评估服务中的异步行为。 它通过在固定间隔轮询而不是无限期阻塞来平衡响应性和资源使用。 重试限制可以防止在服务从不返回完成状态的情况下出现失控循环。 """ run = None for attempt in range(1, max_polls + 1): run = client.evals.runs.retrieve(eval_id=eval_id, run_id=run_id) if run.status == "completed": break if attempt == max_polls: print("Exceeded retries, aborting") break time.sleep(5) run_output_items = client.evals.runs.output_items.list( eval_id=eval_id, run_id=run_id ) return run_output_items def parse_eval_run_output(items): """提取所有评分器分数和任何可用的结论输出。""" all_results = [] for item in items.data: for result in item.results: grader_name_full = result.name score = result.score passed = result.passed reasoning = None try: sample = result.sample if sample: content = result.sample["output"][0]["content"] content_json = json.loads(content) steps = content_json["steps"] reasoning = " ".join([step["conclusion"] for step in steps]) except Exception: pass all_results.append( { "grader_name": grader_name_full, "score": score, "passed": passed, "reasoning": reasoning, } ) return all_results
重训练流程:反馈收集完毕后,智能体进入更新阶段。摘要评估失败时,循环调用"MetaPrompt"智能体——输入原始提示、源文档、生成的摘要、失败原因。MetaPrompt LLM输出新提示。系统用这个新提示创建新版SummarizationAgent。本质上,智能体通过LLM重写指令完成了"重训练"。更高级的系统可能微调模型权重或调整其他模块(更新记忆条目、更换工具)。关键点是智能体从错误中学习。
每轮迭代都应该带来性能提升。示例循环给每个部分最多3次改进机会。如果新提示版本让摘要通过所有评分器(宽松阈值),循环继续;否则重复尝试。代码追踪哪个提示版本综合得分最高,处理完所有部分后部署最优版本。这种重训既可以离线批量做,也可以在线随新数据持续适应。最终产出一个只靠自生成反馈就进化得更准确的智能体。
代码实现详解下面是OpenAI Notebook实现的关键部分。
1、评估配置
先定义带多个评分器的Eval来给智能体输出打分,用的是OpenAI Evals API。每个评分器检查特定标准:chemical_name_grader(Python代码)计算化学名称在摘要中的出现比例,保证领域关键词不丢失;word_length_deviation_grader控制摘要长度在容差范围内;cosine_similarity测量源文和摘要的语义重叠度;llm_as_judge用GPT-4.1按评分标准给综合分。这些评分器收集到testing_criteria列表,然后创建评估:
from openai import OpenAI client = OpenAI(api_key=os.getenv("OPENAI_API_KEY")) data_source_config = { "type": "custom", "item_schema": {"type": "object", "properties": {"section": {"type": "string"}, "summary": {"type": "string"}}, "required": ["section", "summary"]}, "include_sample_schema": False } testing_criteria = [ { "type": "python", "name": "chemical_name_grader", "pass_threshold": 0.8, "source": r""" def grade(sample: dict, item: dict) -> float: section = item["section"] summary = item["summary"] # 预期化学名称列表 CHEMICALS_MASTER = [...] present = [chem for chem in CHEMICALS_MASTER if chem in section] if not present: return 1.0 correct = sum(1 for chem in present if chem in summary) return correct / len(present) """ }, { "type": "python", "name": "word_length_deviation_grader", "pass_threshold": 0.85, "source": r""" def grade(sample: dict, item: dict) -> float: summary = item["summary"] word_count = len(summary.split()) expected = 100 tolerance = 0.2 deviation = abs(word_count - expected) / expected if deviation <= tolerance: return 1.0 score = max(0.0, 1.0 - (deviation - tolerance)) return score """ }, { "type": "text_similarity", "name": "cosine_similarity", "input": "{{ item.summary }}", "reference": "{{ item.section }}", "evaluation_metric": "cosine", "pass_threshold": 0.85, }, { "type": "score_model", "name": "llm_as_judge", "model": "gpt-4.1", "input": [ { "role": "system", "content": ( "You are an expert summarization evaluator. Score the summary between 0 and 1..." ) }, { "role": "user", "content": ( "Section:\n{{item.section}}\nSummary:\n{{sample.output_text}}" ) } ], "range": [0, 1], "pass_threshold": 0.85, }, ] eval = client.evals.create( name="self_evolving_eval", data_source_config=data_source_config, testing_criteria=testing_criteria ) print(f"Created Eval: {eval.id}")
这段代码导入OpenAI客户端,配置自定义数据schema(每个item有section和summary),定义四个评分器。Python评分器用内联代码(raw string)定义grade函数。client.evals.create()创建评估但还不执行。这些规则会对智能体生成的每个摘要自动打分。
2、执行评估
接着定义辅助函数,在给定的section-summary对上跑评估并解析结果:
import time, json def run_eval(eval_id: str, section: str, summary: str): """使用一个示例(section+summary)安排评估运行。""" return client.evals.runs.create( eval_id=eval_id, name="self-evolving-eval", data_source={"type": "jsonl", "source": {"type": "file_content", "content": [ {"item": {"section": section, "summary": summary}} ]}} ) def poll_eval_run(eval_id: str, run_id: str, max_polls=10): """轮询直到评估运行完成,然后返回输出项。""" for attempt in range(max_polls): run = client.evals.runs.retrieve(eval_id=eval_id, run_id=run_id) if run.status == "completed": break time.sleep(5) return client.evals.runs.output_items.list(eval_id=eval_id, run_id=run_id) def parse_eval_run_output(items): """从评估运行输出中提取评分器分数和推理。""" all_results = [] for item in items.data: for result in item.results: score = result.score passed = result.passed reasoning = None try: content = result.sample["output"][0]["content"] reasoning = json.loads(content)["steps"][0]["conclusion"] except Exception: pass all_results.append({ "grader_name": result.name, "score": score, "passed": passed, "reasoning": reasoning }) return all_results # 示例运行 EVAL_ID = eval.id SECTION = "...some section text..." SUMMARY = "...agent's summary..." eval_run = run_eval(EVAL_ID, section=SECTION, summary=SUMMARY) run_output = poll_eval_run(EVAL_ID, run_id=eval_run.id) grader_scores = parse_eval_run_output(run_output) print(grader_scores)
run_eval函数把一个样本(section+摘要)发送给评估服务,然后轮询等待完成(poll_eval_run),最后解析结果。输出是字典列表,每个评分器一条,格式类似{"grader_name": ..., "score": ..., "passed": ..., "reasoning": ...}。多数评分器只返回分数和pass/fail,LLM评分器会额外附带推理文本。这种结构化反馈供循环决定如何改进智能体。比如chemical_name_grader失败,说明摘要漏掉了关键术语。
3、智能体与提示版本管理
下一步配置智能体本身和提示版本追踪的数据结构,用OpenAI Agents SDK定义智能体并管理提示。
配置包括:VersionedPrompt类(基于Pydantic)记录提示版本和元数据;PromptVersionEntry存储每个版本的文本、版本号、模型、时间戳等;两个智能体——SummarizationAgent(执行实际任务)和MetaPromptAgent(负责改写提示)。
from datetime import datetime from typing import Any, Optional from pydantic import BaseModel, Field class PromptVersionEntry(BaseModel): """存储提示的一个版本和相关元数据。""" version: int model: str = "gpt-5" prompt: str timestamp: datetime = Field(default_factory=datetime.utcnow) metadata: Optional[dict[str, Any]] class Config: validate_assignment = True extra = "forbid" class VersionedPrompt: """跟踪PromptVersionEntry列表并允许更新。""" def __init__(self, initial_prompt: str, model: str = "gpt-5"): self._versions = [PromptVersionEntry(version=0, model=model, prompt=initial_prompt)] def current(self) -> PromptVersionEntry: return self._versions[-1] def update(self, new_prompt: str, model: Optional[str] = None, metadata: Optional[dict]=None): next_version = self.current().version + 1 entry = PromptVersionEntry(version=next_version, model=model or self.current().model, prompt=new_prompt, metadata=metadata) self._versions.append(entry) return entry # 创建智能体和初始提示 from agents import Agent # 假设的agents SDK METAPROMPT_TEMPLATE = """ Context: Original prompt: {original_prompt} Section: {section} Summary: {summary} Reason to improve: {reasoning} Task: Write an improved summarization prompt that is more specific and preserves all details... """ metaprompt_agent = Agent(name="MetaPromptAgent", instructions="You are a prompt optimizer.") summarization_prompt = VersionedPrompt(initial_prompt="You are a summarization assistant. Given a section, produce a summary.") summarization_agent = Agent(name="SummarizationAgent", instructions=summarization_prompt.current().prompt, model=summarization_prompt.current().model)
VersionedPrompt确保每次提示变更都有记录(版本1、2、3...)。PromptVersionEntry存储文本及相关模型、版本号等信息。代码实例化了一个"MetaPromptAgent"专门负责重写提示,以及一个用简单初始提示的SummarizationAgent。循环中每次更新提示时调用summarization_prompt.update(...),新条目追加到版本列表,需要时可以回滚。这套机制让提示演变过程可追溯。
4、自我进化循环编排
最后是核心的自我改进循环实现。单次迭代的逻辑:
智能体用当前提示生成摘要;
在(section, summary)上跑评估拿到评分;
计算综合分数(评分器均值),检查是否过宽松阈值;
通过则成功;未通过则收集反馈并改进提示;
每个部分最多重试若干次;
所有部分处理完后,选择综合得分最高的提示版本。
简化代码如下:
MAX_RETRIES = 3 for section, content in dataset: for attempt in range(1, MAX_RETRIES+1): # 运行总结智能体 result = Runner.run(summarization_agent, content) summary = result.final_output # 用评分器评估 grader_scores = await get_eval_grader_score(eval_id=EVAL_ID, section=content, summary=summary) avg_score = calculate_grader_score(grader_scores) passed = is_lenient_pass(grader_scores, avg_score) print(f"Attempt {attempt}: avg score={avg_score}, passed={passed}") if passed: break # 如果失败,收集文本反馈并向MetaPromptAgent询问新提示 feedback = collect_grader_feedback(grader_scores) prompt_input = METAPROMPT_TEMPLATE.format( original_prompt=summarization_prompt.current().prompt, section=content, summary=summary, reasoning=feedback ) meta_result = await Runner.run(metaprompt_agent, prompt_input) improved_prompt = meta_result.final_output # 更新总结智能体的提示 summarization_prompt.update(new_prompt=improved_prompt, metadata={"section": content, "summary": summary}) summarization_agent = Agent(name="SummarizationAgent", instructions=improved_prompt, model=summarization_prompt.current().model) print(f" Improved prompt to version {summarization_prompt.current().version}")
对每个文档部分,SummarizationAgent生成摘要,然后跑评估(get_eval_grader_score)计算分数。未通过检查时,组装反馈字符串(如"化学名称缺失"或LLM给的原因描述),调用MetaPrompt智能体传入原始提示、文档片段、摘要和反馈。MetaPrompt LLM返回新提示,更新VersionedPrompt并重建SummarizationAgent。重试最多MAX_RETRIES次直到通过或放弃。处理完所有数据后,追踪哪个提示版本综合得分最高。实际循环会记录每一步并最终打印最优版本。这展示了自生成反馈(评分器结果)如何驱动迭代改进——智能体在教自己如何写更好的提示。
总结自我进化智能体适用于任何任务复杂且持续演变的领域。除了医疗文档,金融(智能体跟随市场变化更新策略)、编程(代码生成智能体适应新库和新错误模式)、生物医学(研究助手迭代优化文献综述)都是潜在场景。相关研究已经指出生物医学、编程、金融这些垂直领域的具体策略。代码生成智能体可以根据测试结果持续改进编码风格或错误检测逻辑;客服聊天机器人可以从新类型的用户咨询中在线学习。
随着AI智能体被部署到关键任务,自动自我改进能把人力从繁琐的debug转移到高层决策——设定目标、确保安全。能够自我纠错的智能体长期来看更可靠。
最后这个领域还很新,算是对这个方向的首批系统性审视之一,开放问题很多。比如说如何安全地允许智能体改写自身行为?什么评估基准最适合持续学习?但前景很有吸引力:未来的助手能优雅地从经验中学习;工厂机器人随生产需求自我调整;教育导师为每个学生个性化自己的教学策略。从静态AI到真正的终身学习智能体,这条路刚刚开始。
https://avoid.overfit.cn/post/39758407b909479aab400a01b29bac65
作者:DhanushKumar