SEO标题:数据分析有哪些方法?一文掌握16种最常用的数据分析方法
无论是产品优化、运营决策还是战略规划,都离不开数据分析的支撑。
今天给大家总结了从基础到进阶的十六种核心数据分析方法,不管是电商运营、用户研究,还是广告效果评估、销售预测,这些业务场景都能用上,帮你提升工作效率,把数据价值真正落到业务结果上。
开始之前给大家准备了一份数字化全流程资料包,里面包括数据分析的重点知识和企业数据应用的精选案例,帮你解决在数据应用、数字化落地中的实际困惑,更好地着手数据工作。
第一部分:基础描述类
1. 描述性统计
这是最基础、最常用的方法数据分析方法。它是对数据进行概括性描述,比如计算数据的均值、中位数、众数、标准差、极差、频率等指标
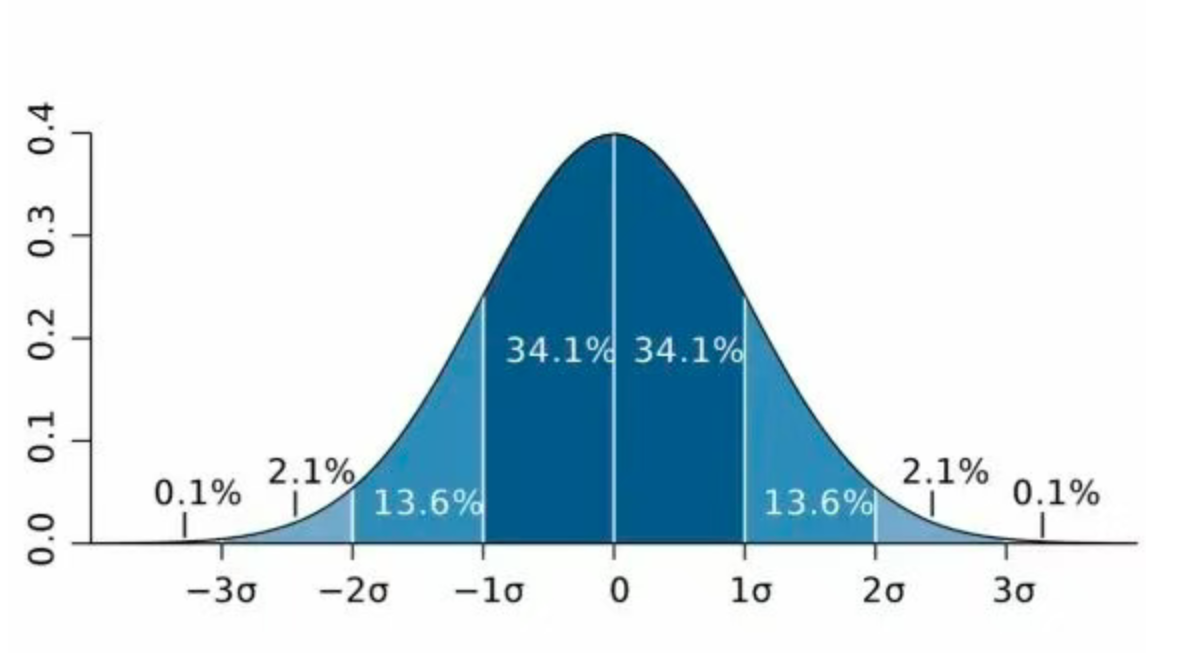
集中趋势:均值(平均水平)、中位数(中间位置)
离散程度:标准差(数据波动大小)、方差、极差(最大值-最小值)
它能帮你发现明显的异常值,并初步判断数据分布是否正常,这直接影响后续方法的选择。
2. 主成分分析
主成分分析就是在保留大部分信息的前提下,将多个存在相关性的原始变量,降维成少数几个互不相关的综合变量(主成分)。主要关注这三点:
看KMO和巴特利特球形检验,判断数据是否适合做此分析。
看“总方差解释”表,确定保留几个主成分(通常累计方差贡献率>80%)。
看“成分矩阵”,理解每个主成分主要由哪些原始变量构成,并为其命名。
比如你做电商店铺运营,涉及10个评价指标:
宝贝描述、物流速度、客服态度、性价比、包装、售后、发货速度、产品质量、颜值、实用性
这些指标相关性很强,变量太多不好分析,用主成分分析就能把这10个指标浓缩成3-4个主成分,比如“服务体验”“产品品质”“物流效率”,既能简化分析,又能快速抓住店铺运营的核心短板。
3. 相关性分析
它的核心就是分析两个或多个变量之间的关联程度,比如收入和消费金额之间有没有关系,关系是正相关还是负相关,相关程度有多高。
关键指标:皮尔逊相关系数(r),取值范围-1到1。正值表示正相关,负值表示负相关,绝对值越大相关性越强。
相关性不等于因果关系。它只能说明两个变量协同变化,无法证明谁导致谁。分析时一定要结合散点图观察,避免被个别极端值误导或误判线性关系。
4. 方差分析
简单来说,方差分析就是比较多个组之间的均值是否有显著差异。
比如你想知道不同年龄段(18-25岁、26-35岁、36岁以上)的用户,对某款产品的满意度是否有区别;或者不同营销方案,带来的销售额是否有差异,都可以用方差分析。
第二部分:深度挖掘类
5. 因子分析
因子分析是从多个变量中提取出潜在的“公共因子”,这些因子是有实际意义的
与主成分分析的区别:主成分分析只是变量的线性组合,不一定有实际意义。
比如你研究用户的购买行为,涉及多个变量(比如价格敏感度、品牌偏好、购买频率等),因子分析可以帮你提取出“消费能力”“品牌忠诚度”这样的公共因子,让你更清楚用户的购买逻辑。
做因子分析时,要先做KMO检验和巴特利特球形检验,只有KMO值大于0.6,巴特利特球形检验P值小于0.05,才能进行因子提取。因子提取后,还需要进行因子旋转,让因子的含义更清晰,方便解读。
6. 聚类分析
说白了,聚类分析就是“物以类聚,人以群分”,把相似的样本归为一类,不相似的归为不同的类,不需要提前知道类别,属于“无监督学习”。主要分为两种:
K均值聚类:需事先指定聚类数K,运算快,适合大样本。
系统聚类:可生成树状图,按距离逐步合并或拆分类别,无需事先指定类别数。
最常用的就是客户分群,比如把电商客户按照消费习惯、购买能力分成4类:
高价值客户(高客单价、高复购)
潜力客户(中客单价、低复购)
流失预警客户(低客单价、低复购)
新客户(首次购买)
后续针对不同群体制定不同的运营策略,高价值客户推专属权益,潜力客户推复购券,流失预警客户推唤醒活动,精准发力。
7. 回归分析
分析自变量(X)对因变量(Y)的影响程度,用于预测或解释。比如分析广告投入对销售额的影响,工资水平对消费水平的影响等等。
常见类型:
线性回归:Y是连续型数值变量。
逻辑回归:Y是二分类变量(如是/否、成功/失败)。
8. T检验
T检验用于比较两组数据均值是否有显著差异,而方差分析用于比较多个组。主要有两种主要形式:
独立样本T检验:比较两个独立分组(如男女、实验组对照组)。
配对样本T检验:比较同一组对象在两种不同条件下的差异(如用药前vs用药后)。
比如你做A/B测试,想知道海报A、海报B的点击率是否有显著差异,就用T检验;再比如,对比实验组(投放优惠券)和对照组(不投放优惠券)的转化率,判断优惠券的投放效果。
9. 卡方检验
卡方检验用于分析两个分类变量之间是存在关联。比如性别和购买意愿之间是否有关联,不同学历的用户对产品的偏好是否有差异。
卡方检验要求样本量足够大,每个单元格的期望值不能太小(一般要求大于5),不然检验结果会不准确。
10. 结构方程模型
它就是用来检验多个变量之间的因果关系,尤其是复杂的因果网络。
比如研究影响用户购买决策的因素,包括产品质量、价格、品牌形象、口碑等。
结构方程模型可以帮你验证这些因素之间的关系,以及它们对购买决策的影响程度,还能检验模型的拟合度,判断模型是否合理。
11. 判别分析
聚类分析是不知道类别,把样本归为不同的类;而判别分析是“已知类别”,建立判别函数,用来判断新的样本属于哪个类别。
比如你已经知道哪些客户是忠诚客户,哪些是流失客户,就可以用判别分析建立函数,后续来了新客户,就能用这个函数判断他属于哪一类,方便做针对性的管理。
12. 时间序列分析
时间序列分析就是分析商业数据随时间变化的规律,核心用于趋势分析和预测,适合有时间维度的商业数据,比如销量、销售额、客流量等。
这是零售、电商、餐饮等行业最常用的方法之一。
连锁餐饮分析每月的客流量变化,预测未来3个月的客流量,提前调整人员配置、食材采购量,避免浪费;
分析电商店铺的月销售额变化,预测双11、618等大促期间的销售额,指导备货、营销预算分配
分析广告投放的月效果变化,判断广告投放的最佳时间,优化投放节奏。
第三部分:验证优化类
13. 中介效应
中介效应就是分析自变量通过“中介变量”对因变量产生影响的过程。
比如广告投入(自变量)通过品牌知名度(中介变量)影响销售额(因变量),中介效应就是检验品牌知名度在其中的作用。还要看是完全中介(广告投入只通过品牌知名度影响销售额),还是部分中介(广告投入既直接影响销售额,也通过品牌知名度影响销售额)。
核心步骤:
先做自变量对因变量的回归,
再做自变量对中介变量的回归
最后做自变量和中介变量一起对因变量的回归
通过系数的显著性来判断中介效应是否存在。
14. 卡诺模型
卡诺模型主要用于分析用户需求的重要性,把用户需求分为基本需求、期望需求、兴奋需求等。
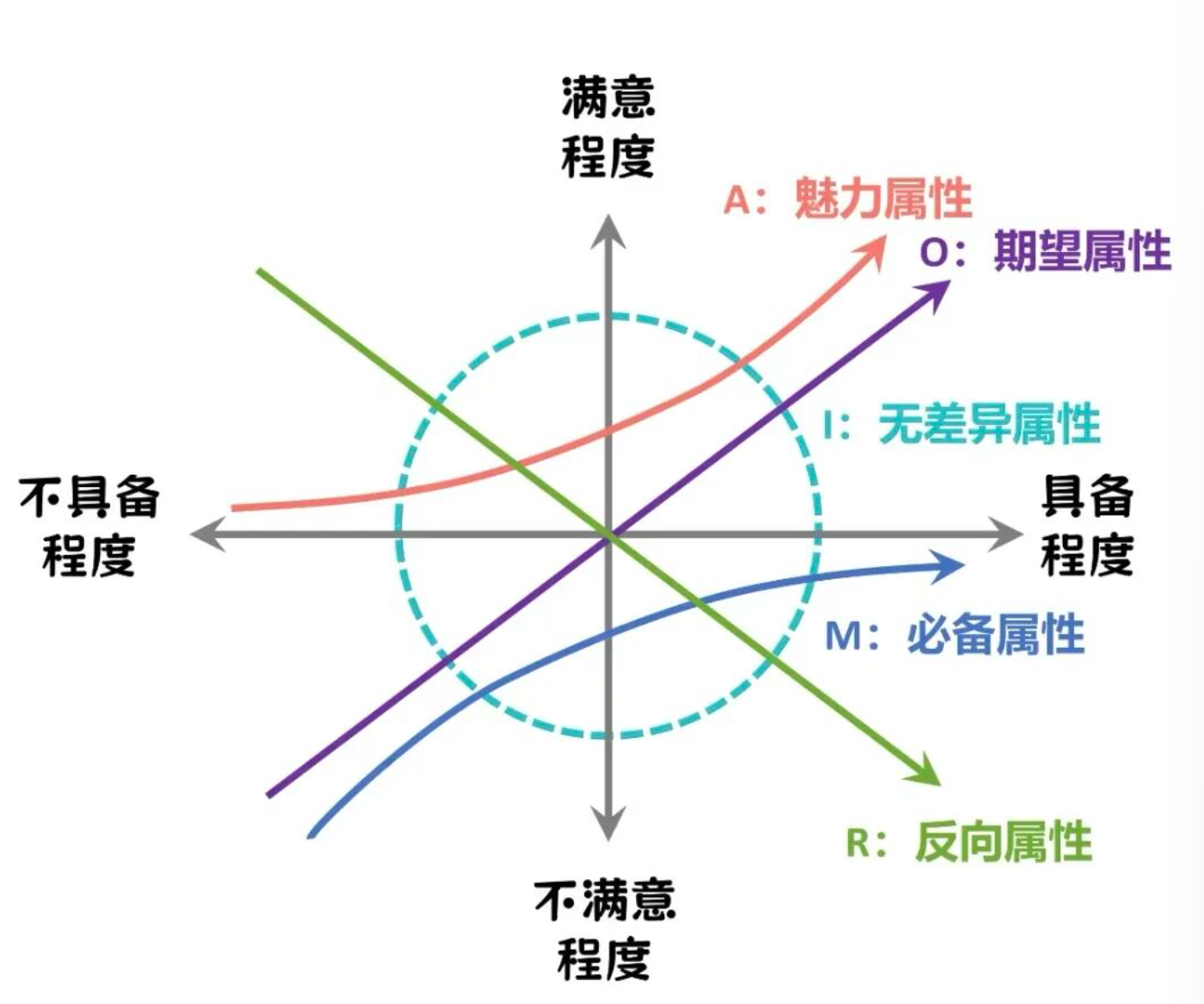
比如用户购买手机
基本需求是能打电话、发短信(如果满足不了,用户会非常不满意);
期望需求是拍照清晰、续航持久(满足了,用户会满意;不满足,会不满意);
兴奋需求是有无线充电、防水功能(满足了,用户会非常满意;不满足,用户也不会不满意)。
15. 信度分析
信度分析就是检验数据的“可靠性”和“稳定性”。
主要指标:克隆巴赫阿尔法系数。通常认为:
系数 > 0.8:信度很好。
系数在0.7~0.8之间:可以接受。
系数 < 0.6:信度不足,需修改量表。
16. 效度分析
信度是检验数据的可靠性,效度是检验数据的有效性,也就是数据是否能准确测量我们想要测量的东西。

比如你想测量用户的满意度,设计的问卷题目是否能真正反映用户的满意度,这就是效度。
常用方法:
内容效度:由专家评判,逻辑判断。
结构效度:最常通过探索性因子分析来验证,看题项的因子负荷结构与理论构想是否吻合。
做好数据分析,除了掌握这些统计方法,一款高效的BI工具能帮你事半功倍。FineBI内置了丰富的统计函数、聚合函数、逻辑函数,还有强大的多维度计算和建模功能,日常场景的数据分析完全够用了。而且不用懂复杂编程,简单拖拽就能完成数据整理、分析运算,还能快速生成柱状图、折线图、仪表盘等可视化图表,把分析结果直观呈现出来,业务人员能快速上手。
数据分析不是套用方法、得出结果就结束了,更重要的是解读结果,结合实际场景,提出有价值的建议,这才是数据分析的意义。希望这篇文章能帮到大家。