DeepSeek发布DSpark给大家梳理一下 DSpark 这次更新的要点:1. 底层算法逻辑重构摒弃传统推测解码固定预生成长度的旧架构,采用半自回归生成+置信度动态调度全新框架,不再机械批量生成候选词元,可实时预判候选内容准确率,自动剔除大概率核验失败的无效 Token ,削减无效算力运算。
2. 三重核心机制整合(三大基础能力)一站式融合草稿预生成、置信度动态调度、硬件感知前缀调度三大模块:草稿快速产出候选文本片段;置信度实时筛选精简计算量;硬件调度读取 GPU 显存/负载动态调整核验长度,最大化硬件利用效率。
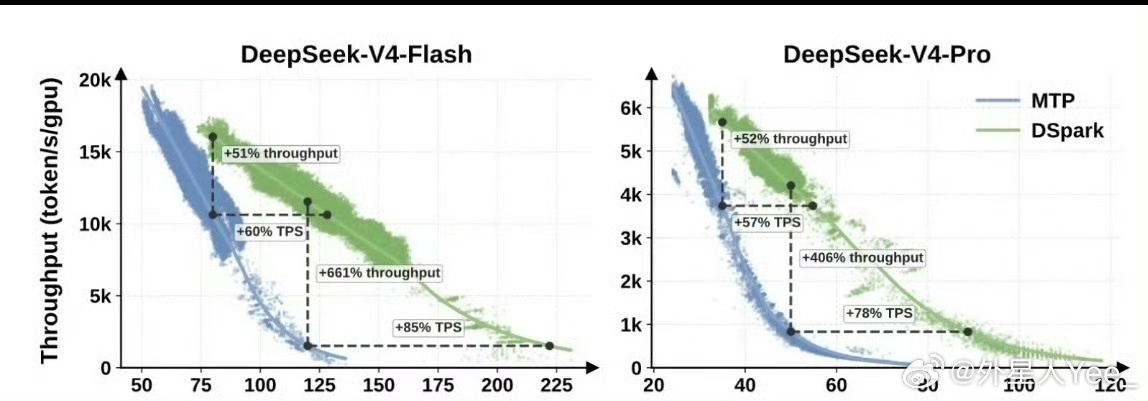
3. 性能上限大幅突破,高并发增益极强对标经典 MTP 基线方案,推理吞吐量整体提升 51%~400% ;在 DeepSeek-V4-Flash、V4-Pro 两款模型中,并发流量越高提速效果越突出,解决传统加速方案大流量场景性能大幅衰减的短板。
4. 跨模型通用适配,落地实用性更广并非 DeepSeek 模型专属优化方案,具备优秀迁移性,可在 Qwen、Gemma 等第三方主流开源大模型上部署生效;落地后可降低大模型推理算力开销,为高并发对话、代码生成、长文本解析等场景提供通用工程优化方案。