这本书到底讲了什么?(敲重点)
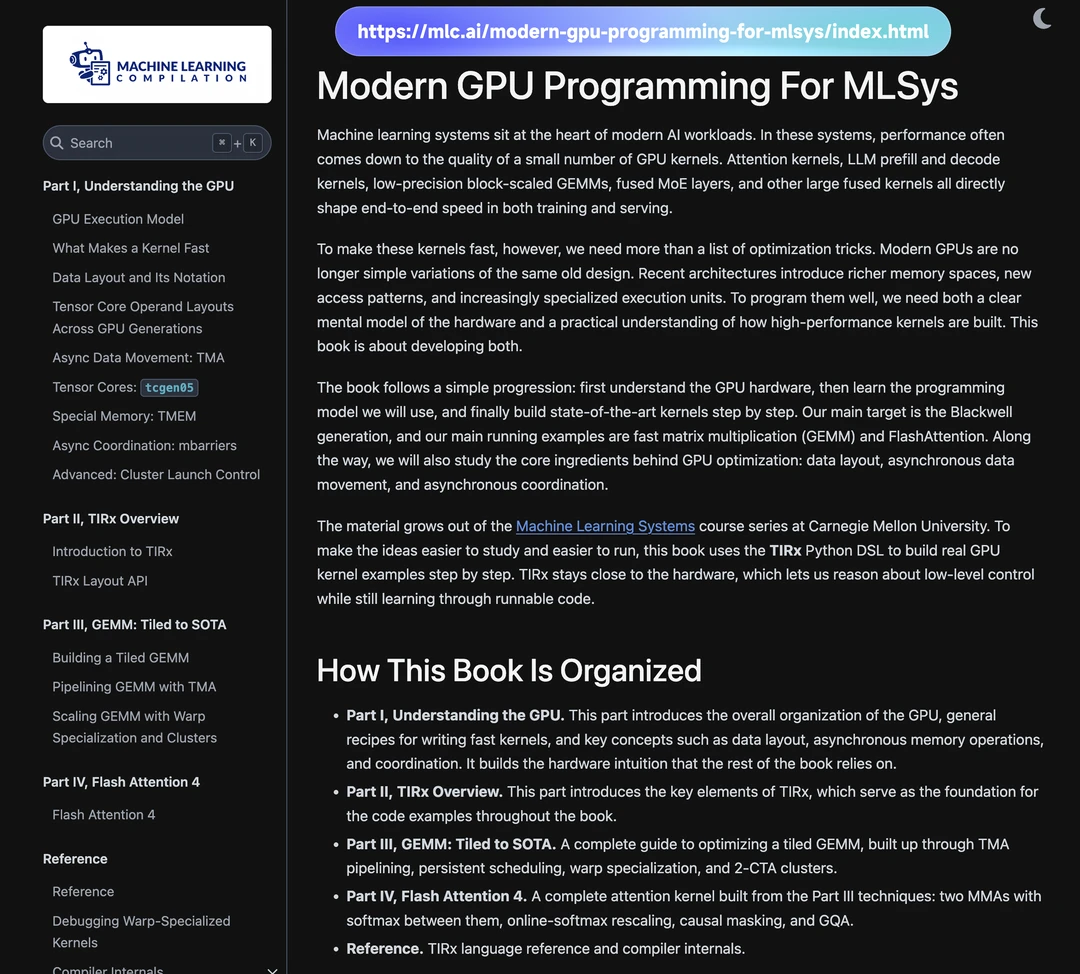
这不是普通的 CUDA 入门,而是直奔 Blackwell 的高性能 kernel 开发,目标是帮你写出 LLM 训练/推理里真正能跑快的核心内核(Attention、GEMM、MoE 等)。
全书采用阶梯式实战教学,从硬件心智模型开始,一步步升级到 SOTA 技巧:
🔸 Part I:理解 GPU 硬件
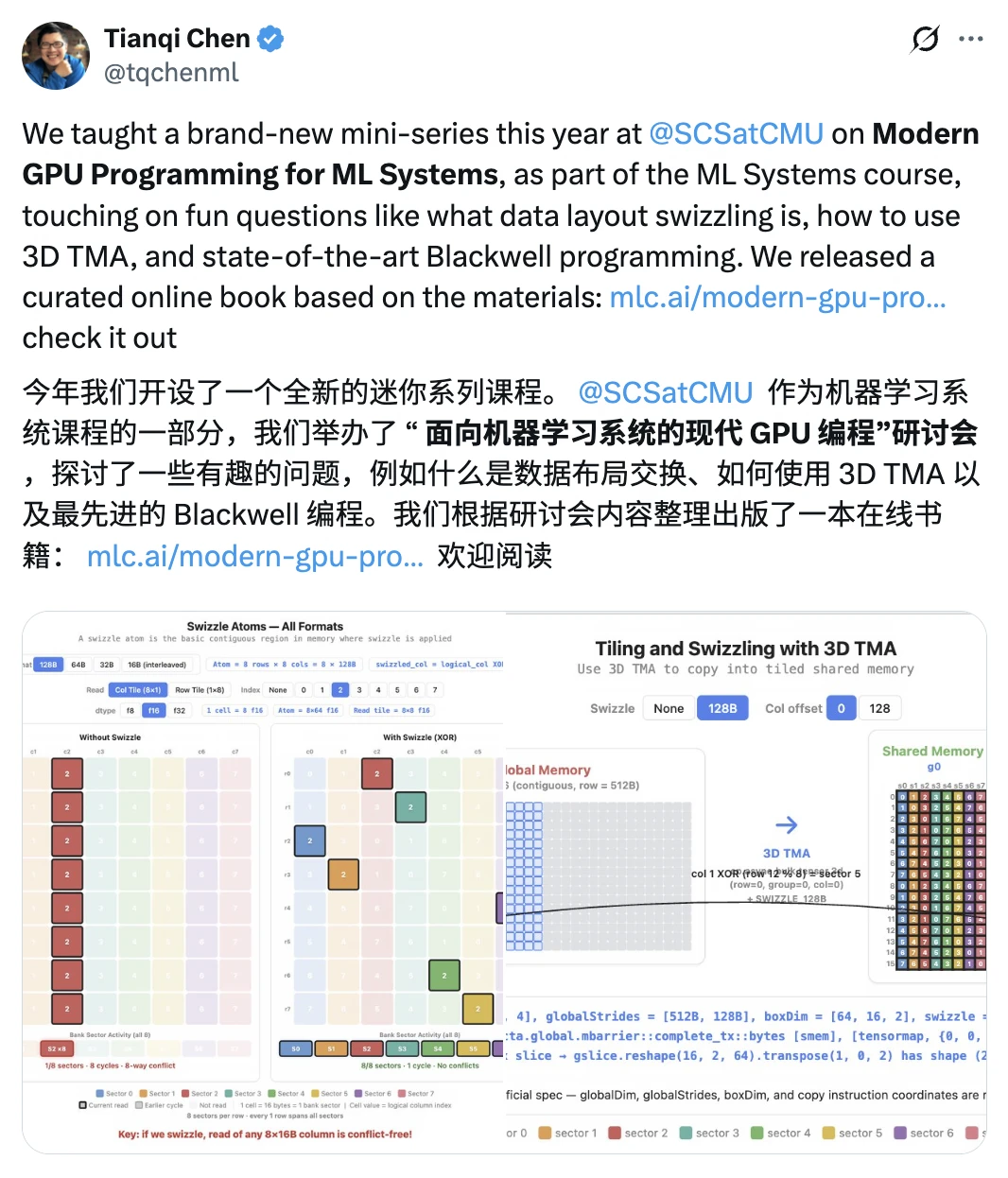
GPU 执行模型、Roofline 性能分析、数据布局(Data Layout)与 Swizzling(避免 bank conflict)、TMA 异步数据搬运(支持 3D tiling)、Tensor Core 、TMEM 新内存、mbarriers 异步协调、Cluster Launch 等 Blackwell 新特性。
🔸 Part II:TIRx 编程模型概述
用 Python DSL 写 kernel,降低学习门槛。
🔸 Part III:GEMM 从基础到 SOTA
从最简单的 single-tile GEMM 开始,逐步加上: K-loop 累加 → 多 CTA 空间 tiling → TMA 异步加载 + 软件流水线 → Persistent Kernel + Tile Scheduler → Warp Specialization(生产者-消费者分离)→ 2-CTA Cluster、多消费者等高级技巧。最后给出端到端性能对比。
🔸 Part IV:Flash Attention 4
用前面所有技巧完整实现一个现代 FlashAttention 内核,包括两个 MMA 阶段、online softmax rescaling、causal masking、GQA 支持、tile scheduling 等,详细对比和纯 GEMM 的区别。
核心理念:光知道 trick 不够,必须懂硬件(内存层次、异步、重叠计算与搬运、layout),再结合实战代码一步步优化。
总体来说,这是 2026 年非常硬核但教学友好的一份资料,图文+可运行代码+互动demo结合得很好,感兴趣的冲。(地址放图3了)