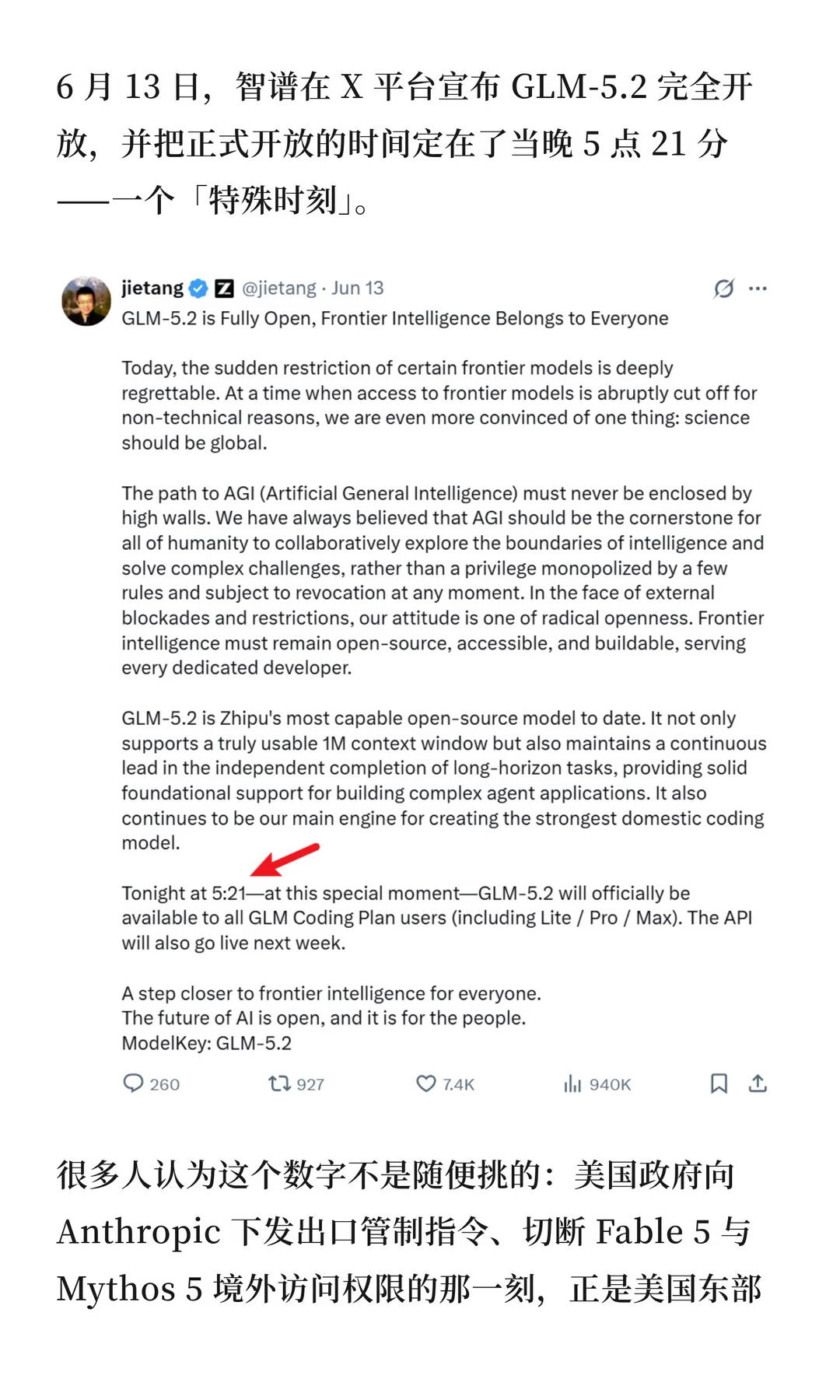
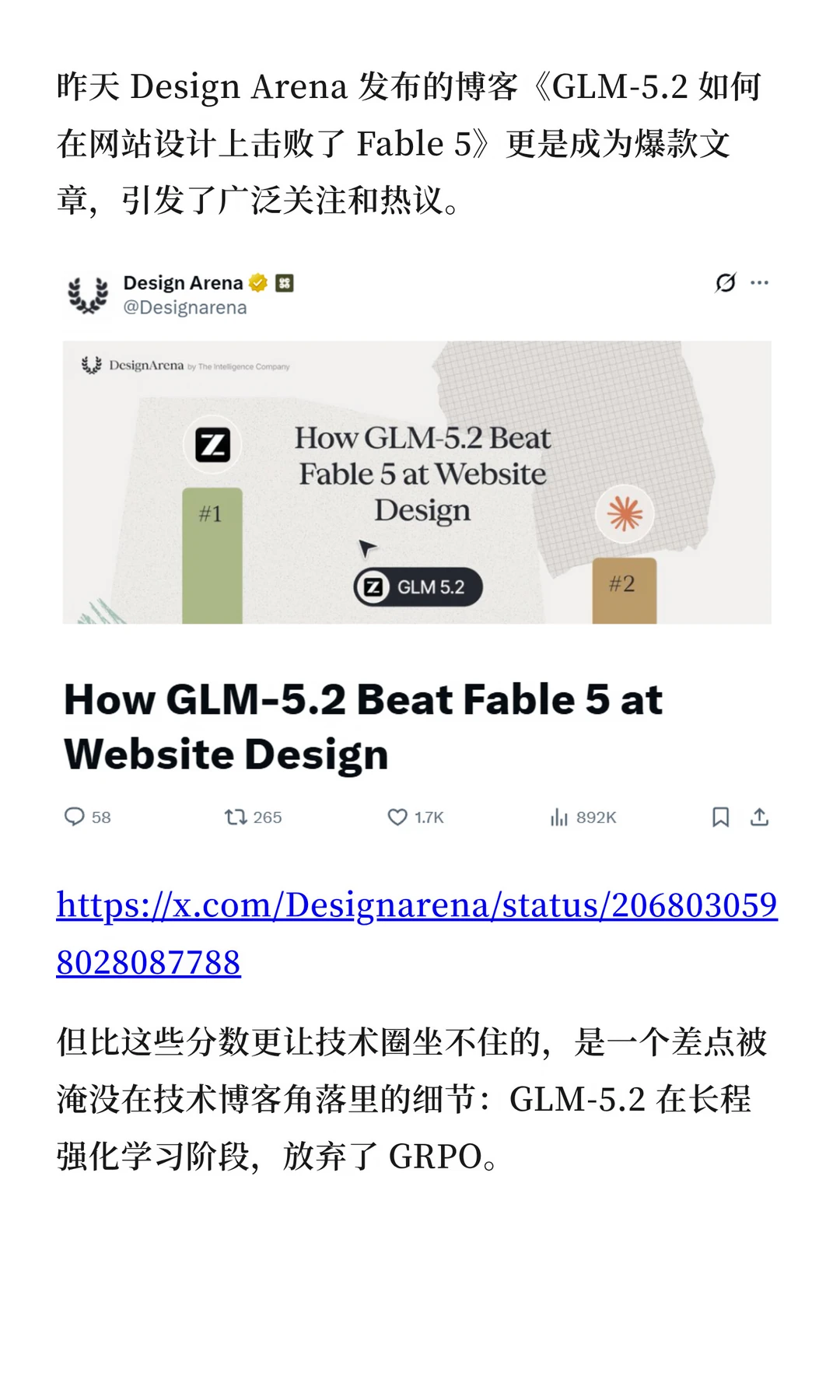
Design Arena 发布的博客《GLM-5.2 如何在网站设计上击败了 Fable 5》更是成为爆款文章,引发了广泛关注和热议。
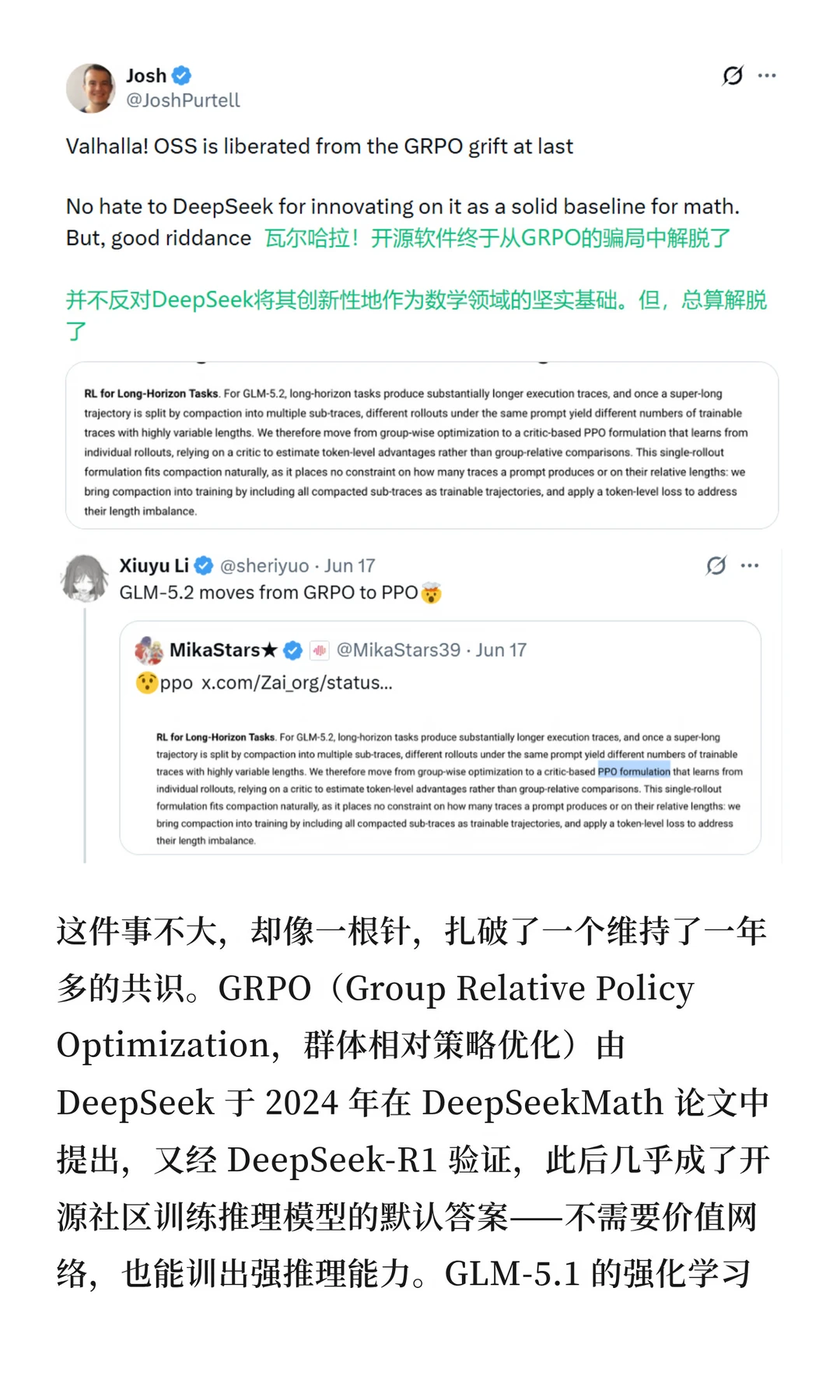
但比这些分数更让技术圈坐不住的,是一个差点被淹没在技术博客角落里的细节:GLM-5.2 在长程强化学习阶段,放弃了 GRPO。
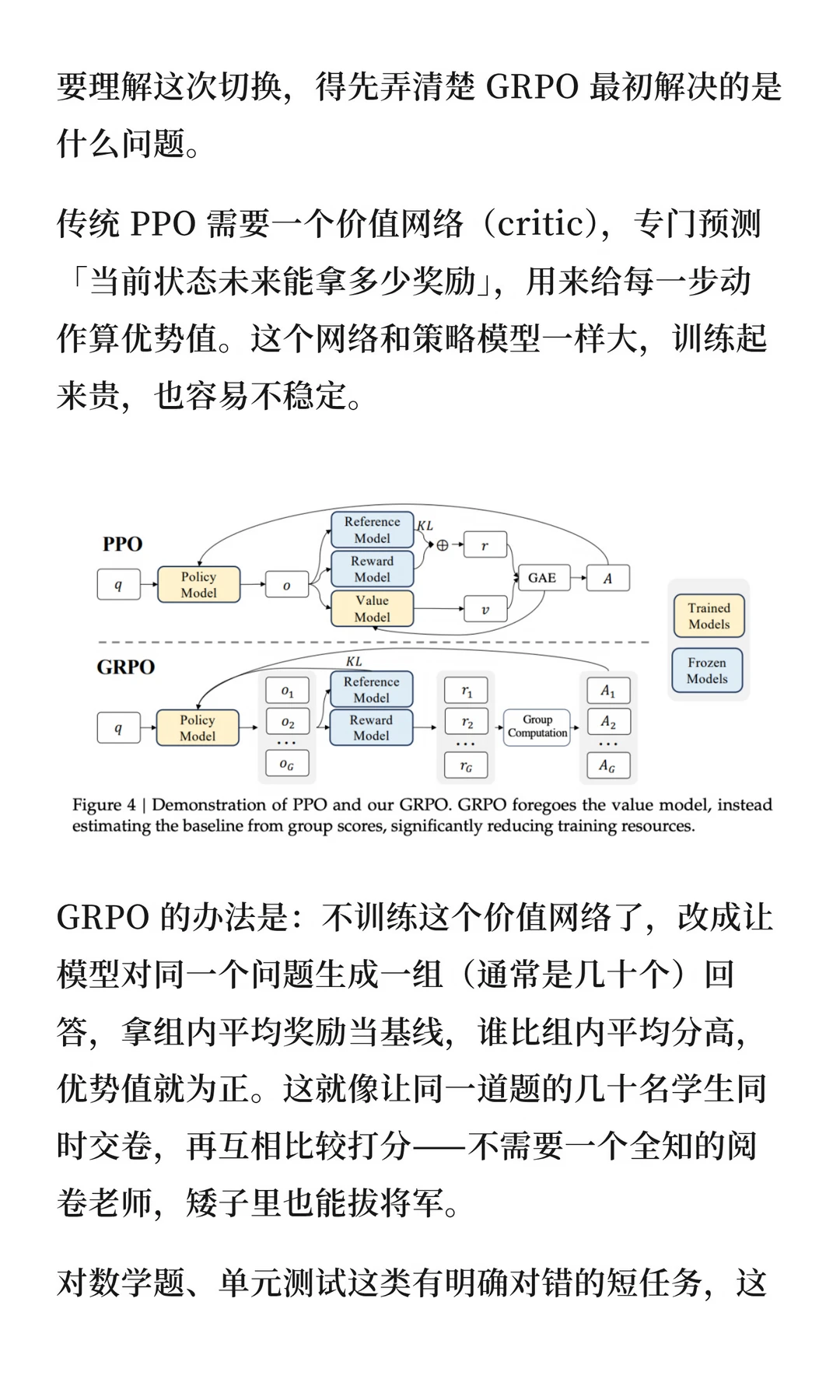
这件事不大,却像一根针,扎破了一个维持了一年多的共识。GRPO(Group Relative Policy Optimization,群体相对策略优化)由 DeepSeek 于 2024 年在 DeepSeekMath 论文中提出,又经 DeepSeek-R1 验证,此后几乎成了开源社区训练推理模型的默认答案——不需要价值网络,也能训出强推理能力。GLM-5.1 的强化学习阶段,用的正是这套思路。一年多以后,GLM-5.2 悄悄把它换掉了。
一个被验证过的范式,正在被它最早的追随者之一悄悄抛弃。
完整内容戳👆🏻正文~ 感谢阅读,如果你觉得对你有用的话 ~ 欢迎点赞收藏并分享给你的盆友们~非常感谢!