你有没有注意到,今年以来AI生成视频的质量突飞猛进。
但与此同时,这个赛道的玩家们似乎都撞上了同一堵墙:模型越来越大,效果越来越好,但成本也越来越离谱。
就像Sand.ai的创始人曹越所说,视频模型存在一个不可能三角,成本、速度、效果,三者很难同时兼顾。
想让生成的视频更逼真更流畅,模型就得更大;模型更大,训练和推理的算力开销就更高;算力开销更高,要么烧更多钱,要么用户等更久。
1
如何理解这句话呢?
你可以把现在主流的视频生成模型想象成一个超大型的全能餐厅,不管客人点的是一碗阳春面还是一桌满汉全席,厨房里所有厨师都得全员上阵。
炒菜的、煲汤的、做甜点的,一个都不能少。每来一单,整个厨房就全力运转一次。
这就是所谓的Dense模型的工作方式,模型里所有的参数,每次推理都要参与计算。
效果当然好,但问题也很明显:太贵了,太慢了,而且越往上堆规模,边际成本越高。
那怎么办?这就要说到MoE了。
MoE全称Mixture of Experts,翻译过来叫混合专家模型。
还是用餐厅打比方。
MoE的思路是:厨房里确实有很多厨师,但每来一单,不是所有人都上,系统会根据这道菜的类型,智能地调配最合适的几位厨师来处理。
你点了一碗面,面点师傅上;你点了法式甜品,西点师来,其他人可以休息。
模型的总参数量很大,意味着能力上限很高。但每次实际计算时,只有一部分专家网络被激活,所以推理成本远低于同等规模的Dense模型。
2
为什么这件事很重要?
视频生成模型正在遇到一个关键的规模化瓶颈。
过去两年,行业的主旋律就是把模型做大,更多参数、更多数据、更多算力,效果确实在肉眼可见地提升。
但这条路走到一定阶段,会碰到天花板:继续按Dense的方式堆规模,训练成本和推理成本都会急剧攀升。
对企业来说,这意味着更多的算力成本。
对用户来说,这意味着产品要么贵、要么慢。
所以行业需要一种新的范式,让模型能力继续往上走,但成本不要跟着线性增长。
MoE就是目前最被看好的路径之一。
3
Sand.ai最近发了一篇技术博客,专门讲他们在视频扩散模型上应用MoE架构的探索。
核心思路就是通过MoE,让视频生成模型在效果、速度和成本之间找到一个更优的平衡点。
但这不是一个容易啃的工程问题。
在大语言模型领域,MoE已经有不少成功案例了,但把它迁移到视频生成上,挑战完全不一样。
视频数据的时空复杂度远高于文本,如何设计专家网络的分工,如何保证生成质量的一致性,如何在工程层面高效实现,这些都需要从头摸索。
4
说到这里,我特别提一下Sand.ai这家公司的技术风格。
他们似乎特别喜欢干一件事:押注非共识。
曹越自己也说过,每一代模型,他们都在押注一个非共识。
具体来说:Magi-1那一代,行业主流是Diffusion扩散模型,他们押注了自回归;Gaga-1那一代,他们押注音画同出,也就是视频和音频一起生成;到了新一代模型,他们又把方向压在了MoE上。
有意思的是,前两次的非共识后来都逐渐变成了行业共识。
自回归现在已经成为视频生成领域的主流选择之一,音画同出也被越来越多团队采纳。
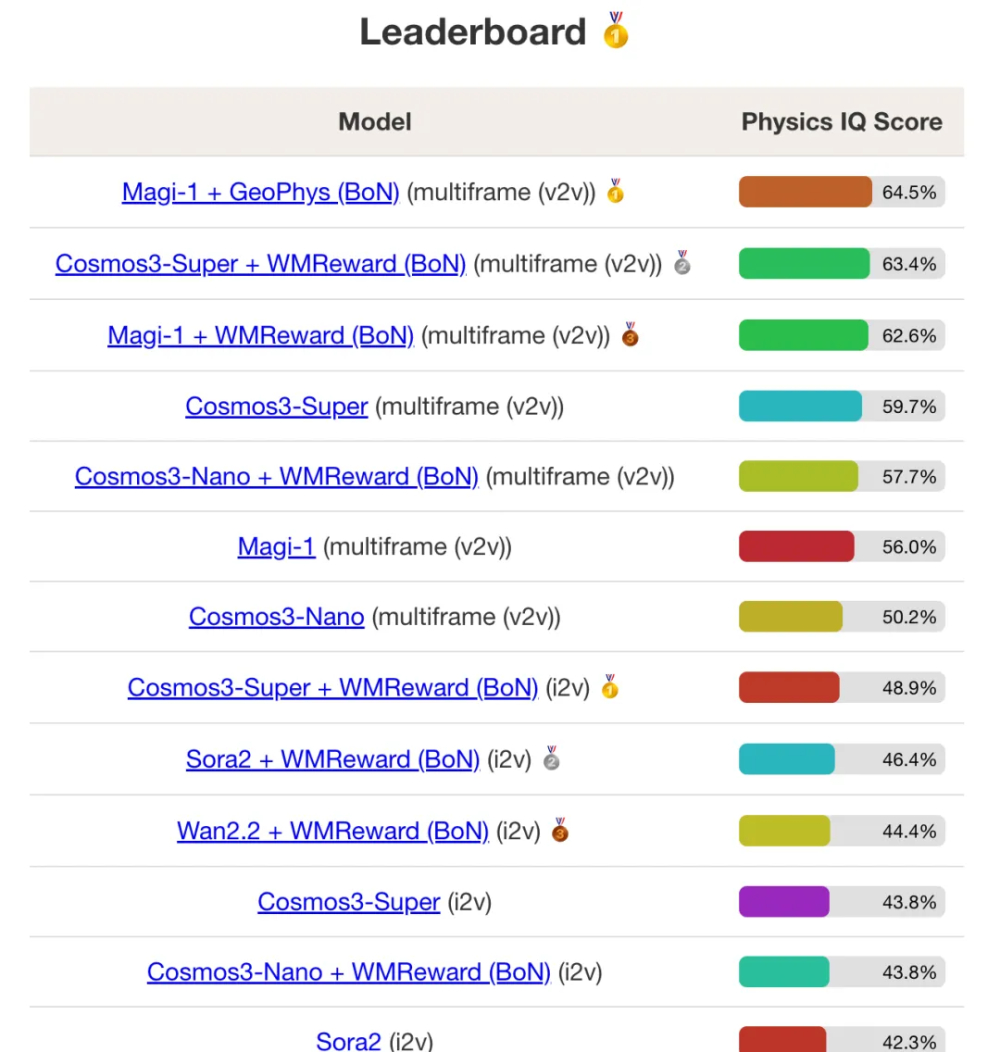
而且他们的Magi-1模型在Google DeepMind提出的Physics-IQ物理真实性测试中拿到了领先成绩,甚至超过了Nvidia最新推出的旗舰级世界模型Cosmos3-Super,更远超Sora2等其他纯Diffusion模型。
这说明Sand.ai基础模型的技术积累非常扎实,不是嘴上说说而已。
5
现在MoE这个新路线能不能再次被验证,还需要时间。
但从技术逻辑上看,它指向的是视频生成行业一个非常核心的问题:如何让模型继续变强,同时让更多人用得起。
资本市场显然也看到了这一点。
Sand.ai在三个月内连续完成了两轮融资,总金额超过1亿美元。
投资方阵容相当豪华,包括Look Capital、Lollapalooza Capital(王慧文家办)、九坤创投、经纬创投、和玉资本(MSA Capital)、创新工场等十多家一线机构。
这么多顶级资本在短时间内集中下注同一家公司,说明他们对Sand.ai的技术路线和商业化前景形成了比较一致的判断。
如果Sand.ai的探索能够再次成为主流,则意味着视频生成模型有机会在不大幅增加成本的前提下继续提升能力,这对整个行业都是好消息。
技术路线的验证当然需要时间,MoE在视频生成领域的应用还处于早期阶段。
但从目前的信号来看,无论是技术方向的合理性,还是资本市场的集体态度,都在指向同一个方向:MoE很可能是视频生成下一阶段最重要的变量之一。
而Sand.ai,又一次提前站到了这个位置上。