实测数据一览|豆包 2.1 Pro 发布,Coding 与 Agent 评测比肩海外主流旗舰
6月23日,在火山引擎 FORCE 原动力大会上,豆包大模型2.1 Pro、豆包视频生成模型 Seedance 2.5、Seedance 2.0 4K 版、豆包图像创作模型 Seedream 5.0 Pro、豆包音频生成模型1.0五大模型集中亮相,豆包大模型 2.1 Pro,本次更新聚焦工程代码、多智能体两大生产力赛道,配套完整公开测评数据、企业落地案例与分层定价体系,客观对比主流海外模型,清晰展现国产大模型当前技术水平与成本优势。
从行业使用规模来看,豆包大模型产业落地规模持续走高,截至 6 月,日均 Token 调用量达 180 万亿,对比去年同期增长 10 倍以上。国内公有云 MaaS 赛道火山引擎占据 49.5% 市场份额,两百余家企业年度 Token 消耗突破万亿,半年规模翻倍,庞大的企业使用体量持续反向优化模型稳定性与场景适配能力。
火山引擎总裁谭待提出 “生产级质变点” 概念,区分普通辅助模型与可承接完整业务的生产模型。在 Coding 与 Agent 领域,此前仅有 Claude Opus 4.6 达到该标准,本次豆包 2.1 Pro 通过多轮工程实测与权威基准测试,正式跨过这一门槛,三大升级方向分别为代码工程、智能体协同、VLM 多模态理解。
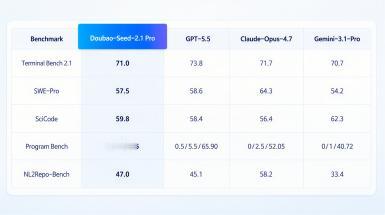
整理公开代码测评数据,可直观对比各旗舰模型表现:Terminal Bench 2.1 评测豆包 2.1 Pro 得分 71.0,接近 GPT-5.5 的 73.0,高于 Claude Opus 4.7、Gemini 3.1 Pro;SciCode 科研代码测试得分 59.8,优于 GPT 与 Claude 同代产品;NL2Repo-Bench 仓库级代码改动测试 47.0,领先海外两款主流模型;SWE-Pro 软件工程修复 57.5 分,处于行业中上游区间。多项基准测试综合表现,证明模型具备大型软件、硬件工程完整交付能力。
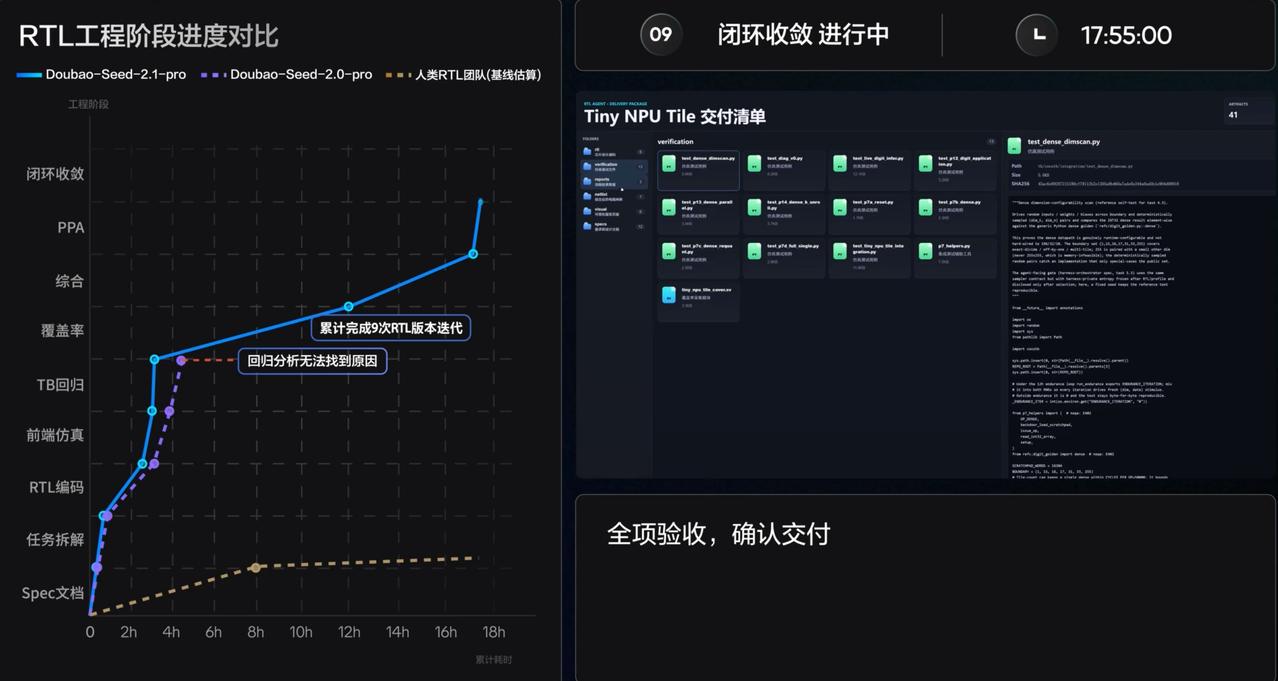
硬件芯片 RTL 实测案例验证落地效果:无人工干预连续运行 18 小时,输出 1303 行标准化硬件描述代码,9 轮迭代修复逻辑漏洞,自主完成仿真、测试、综合检查整套流程。传统模式下该项目需要多名硬件工程师数周协作,AI 可独立完成标准化开发环节,释放研发人力专注创新设计。
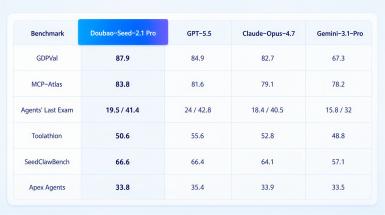
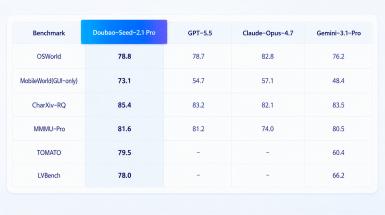
Agent 智能体评测维度,OSWorld、MobileWorld、CharXiv-RQ 多项榜单中豆包 2.1 Pro 国内排名靠前,GUI 跨设备操作、长任务连续执行能力稳定。3D 城市构建演示中,单模型调度 500 个 Agent 协同作业,上千次工具调用完成场景搭建、素材渲染、成片输出,具备多智能体分工、自我纠错、流程复用能力,适配数字员工、自动化办公、内容生产等场景。VLM 视觉能力加持下,两小时长视频可一次性解析,自动完成文案、配音、字幕、背景音乐全流程制作,时序推理、长记忆能力有明显提升。
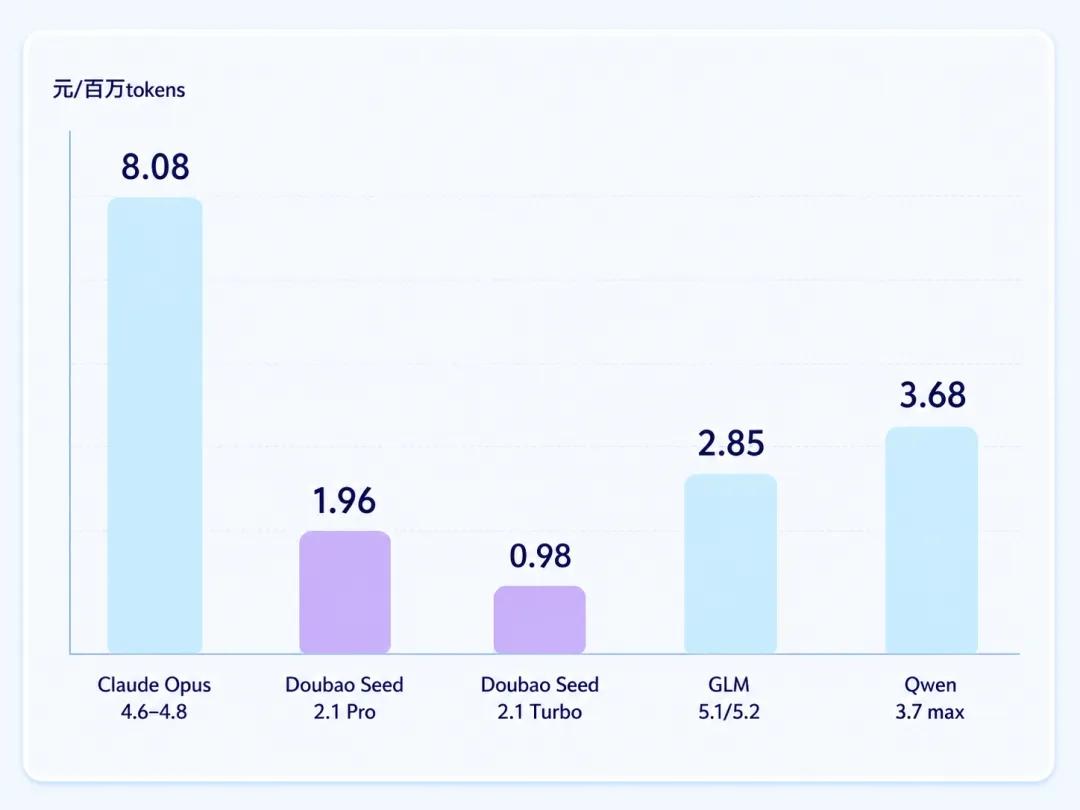
定价体系具备较强成本优势,官方统一计价标准清晰透明:豆包 2.1 Pro 输入 6 元 / 百万 Tokens,输出 30 元 / 百万 Tokens,缓存复用场景单价降至 1.2 元,综合使用成本较 Claude Opus 系列降低近 80%。面向高频批量调用推出 2.1 Turbo,价格为 Pro 一半;Evolving 专属迭代版本按月更新,企业无需修改接入链路即可获取最新优化版本,降低长期迭代适配成本。
配套 AI 云原生架构同步升级,方舟 CLI 简化 Agent 接入流程,AgentKit 新增 Policy 权限管控、Registry 智能体资产统一管理模块,HiAgent 3.0 实现数字员工招聘、考核、调度、迭代全周期管理,AI Trust 机密计算体系保障政企数据安全,中国移动已联合推出专属机密模型服务专区,适配高敏感数据业务。
目前,豆包大模型2.1已在火山引擎开放 API 服务,火山方舟体验中心同步上线,并接入豆包、TRAE、扣子等产品。综合测评、落地案例、定价三方维度来看,豆包 2.1 Pro 为企业提供兼顾性能与成本的国产大模型选择,打破海外旗舰模型在工程、智能体赛道的优势格局。
豆包 2.1 Pro 测评数据AI Coding大模型企业级Agent平台火山引擎FORCE 大会