传统的 Transformer 语言模型在所有层中都保持恒定的宽度(Width)。这意味着每层分配的参数量和计算预算都是均等的。
但实际上,网络中不同深度的层可能承担着完全不同的计算任务。
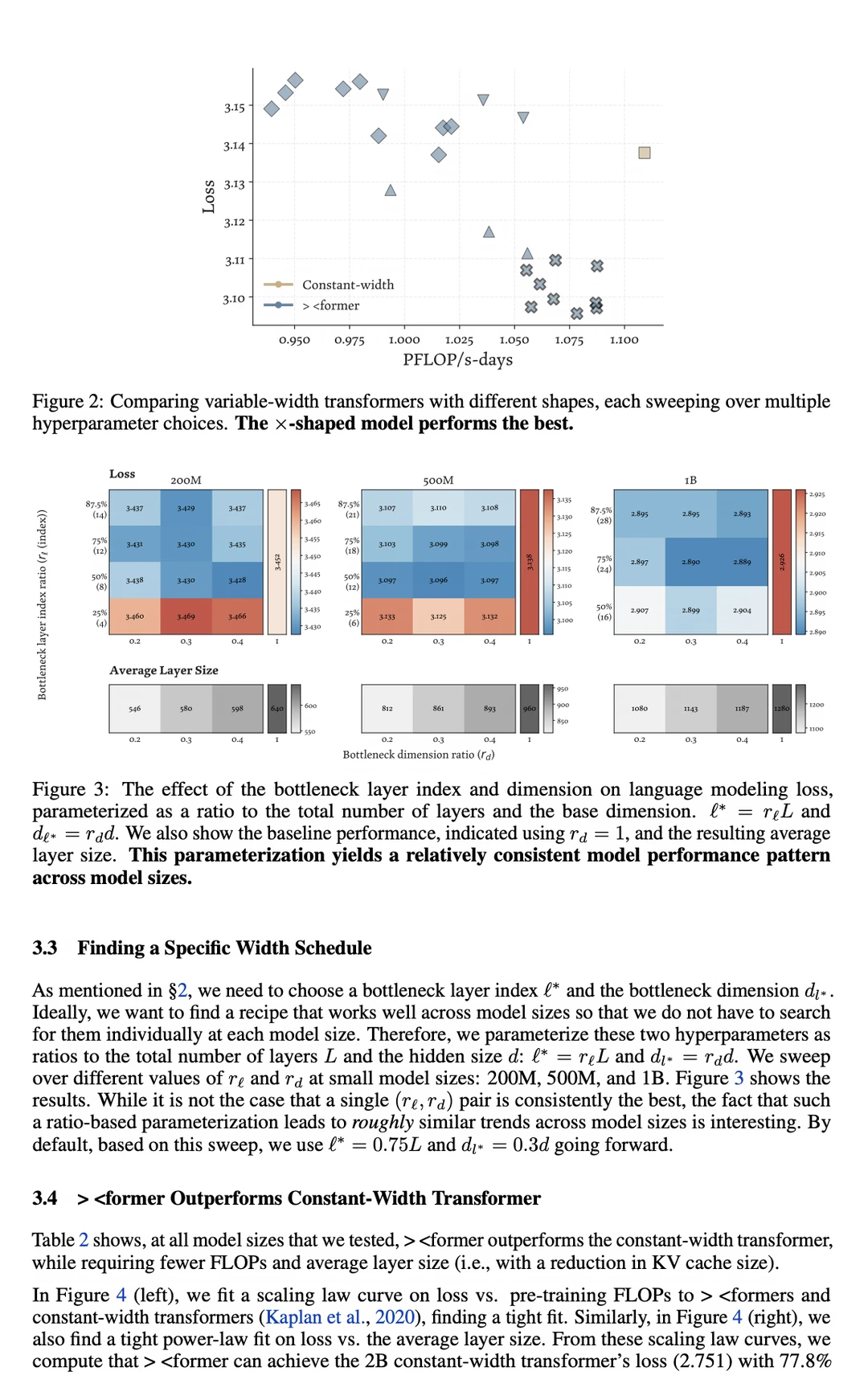
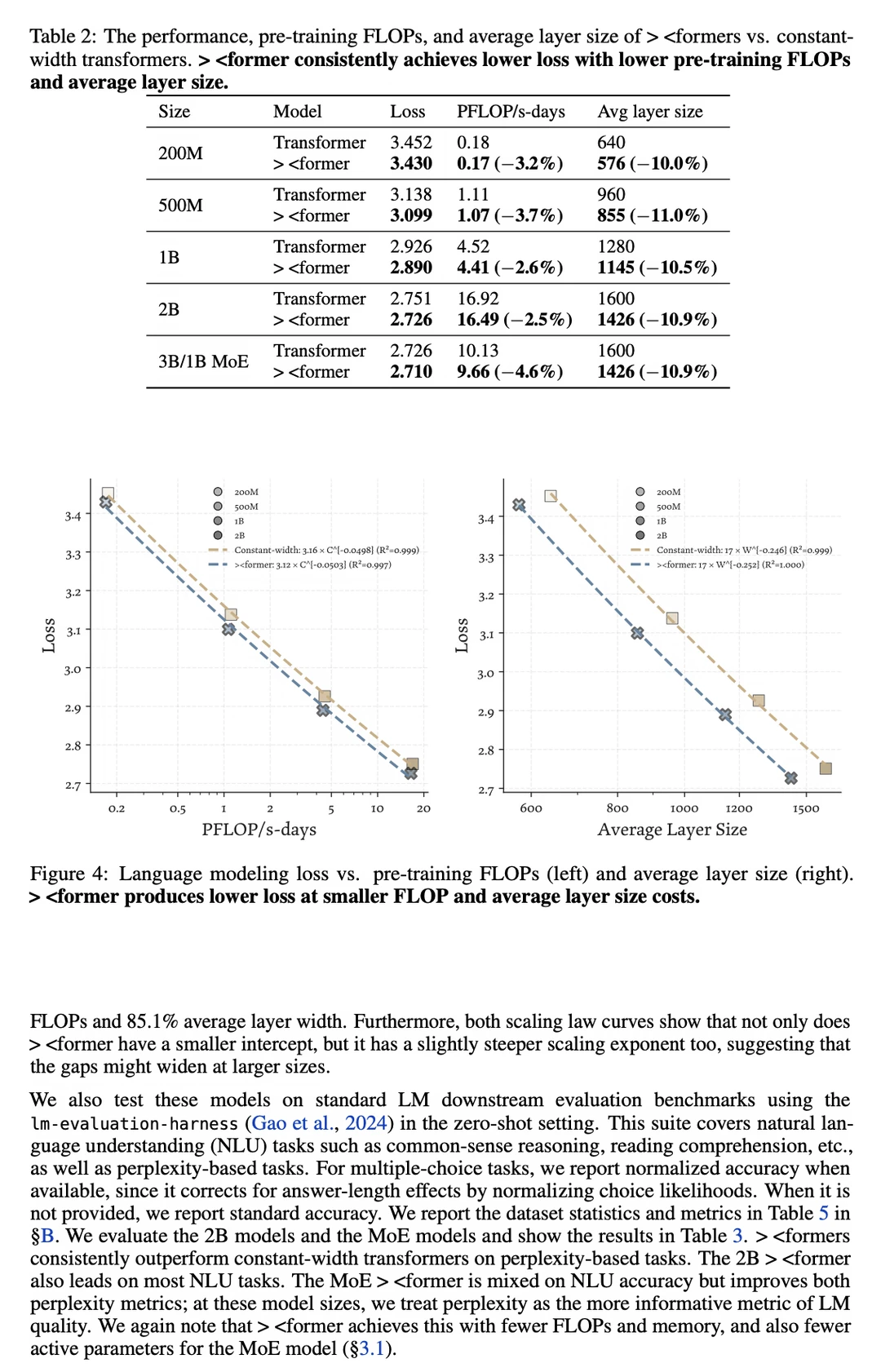
来自 MIT(麻省理工学院)的研究员们提出了一种全新的架构——「X-former」,一种非均匀容量分配的 × 型( hourglass 漏斗状 / 沙漏状)架构。
他们没有采用老一套的做法,而是让前期的层和后期的层保持很宽的维度,但在物理上把中间的层“挤压”成了一个计算瓶颈(bottleneck)。
通过这种设计,他们成功让模型的总参数量与标准均匀宽度的基线模型保持完全一致。但最让人兴奋的重磅炸弹是——它能把训练的 FLOPs 算力消耗降低多达 22%!
并且它还能将 KV Cache 的显存占用和 I/O 成本削减 15%!更厉害的是,做到这一切完全没有牺牲任何下游任务的性能表现。
这开辟了Transformer scaling的新自由度,挑战了长期默认假设,提供可落地(且更高效)的架构改进,值得关注scaling和高效LM研究者一读。
论文可以直接👇🏻download哦~ 拿走不谢,可以点个赞嘛~