中国搞AI大模型和芯片是一个路子,连美国人都看到问题在哪了,他们现在还能走回头路吗?答案是可以,但是代价非常大!
中美都在拼命往AI领域投钱,美国就不用说了,AI产业上已经投下数千亿美元,如果综合美国科技巨头的算力开支,那么AI领域可能已经超过7000亿美元。
中国也在加大AI领域的投入,据公开预测数据,中国在2026年在AI领域的投入(窄口径)大约在4000~6000亿,如果是宽口径(算力、数据中心、AI 芯片、企业 AI 改造全部资本开支)可能高达1.2–1.8 万亿元人民币。
与美国相比规模差的不是一星半点,而从大模型性能上来看,中美之间差距也是相当明显!但是仅从数据上比较可能两者的可比性并不是特别大,因为中美两国的AI可能正在走向两个方向!
美国的大模型走的是稠密注意力路线,比如像Claude等模型全程使用稠密架构,推理时激活全部参数,性能优秀,但在处理百万级长上下文时存储、算力需求爆炸。只能用GPU、内存硬件堆砌资源解决问题。
其导致的结果就性能优秀但成本高昂,美国顶级大模型百万Token输出定价动辄30-50美元,单次亿Token任务成本数千美元,这个成本让大企业也纷纷收紧调用权限,性能良好但用不起实在是个大问题。
而中国的玩法是使用稀疏注意力机制,比如DeepSeek DSA就是这种模式,筛选舍弃无关注意力计算,将复杂度降低,存储需求,算力等指数级下降,仅激活少量参数完成推理,以小幅性能损耗换取极大成本优势,形成整套低成本技术优化体系。
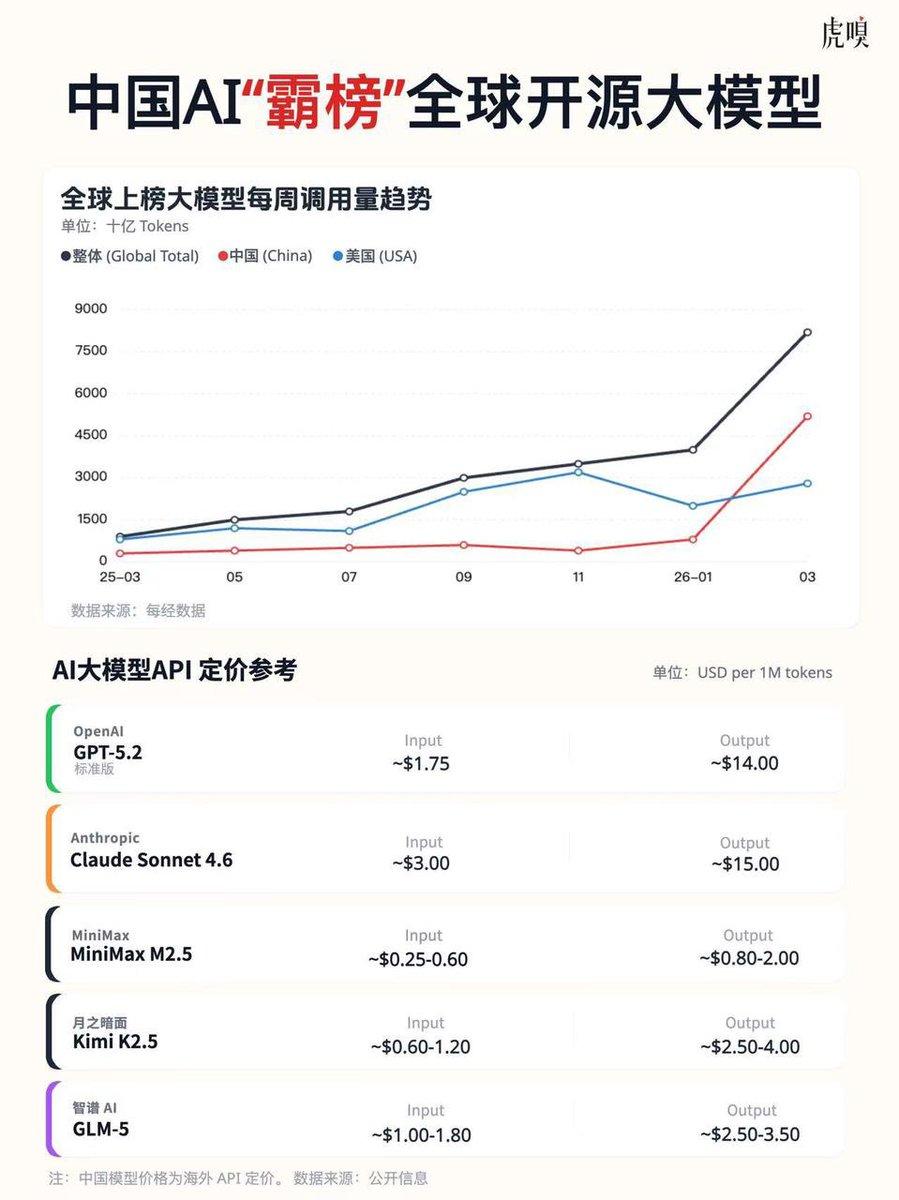
其结果是性能上相对没有Claude这类模型精确,但在要求不高的情况下完全够用!而价格则能低至美国大模型的五分之一甚至百分之一,这个价格带来的结果就是大家都用得起!全球聚合API平台“OpenRouter”在今年2月份公开的数据表明:
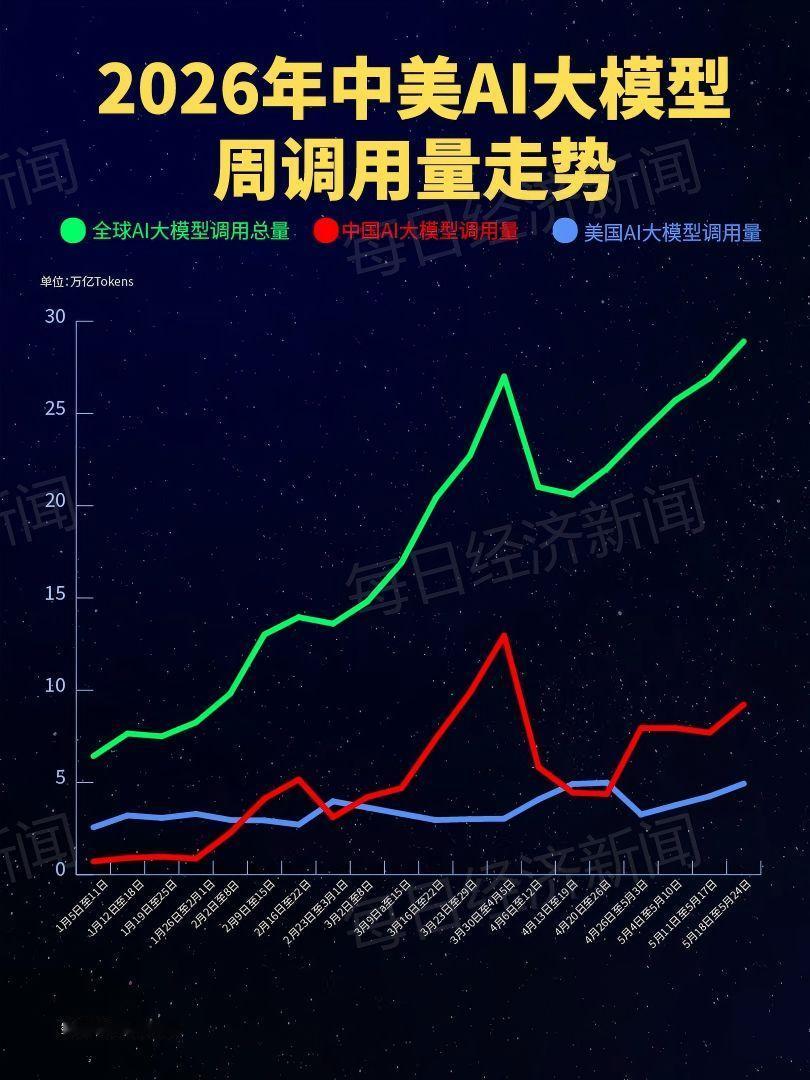
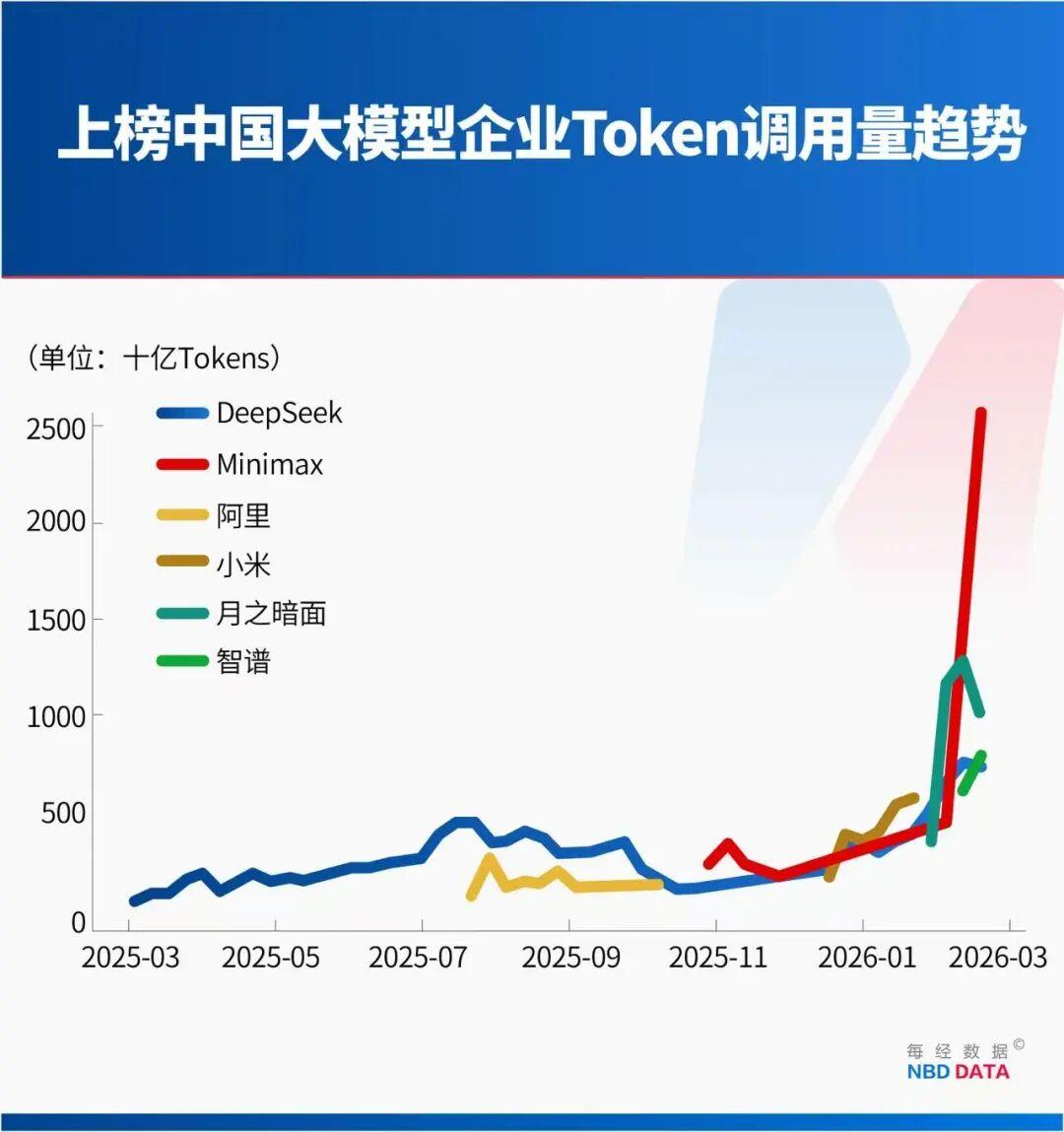
中国大模型周Token总调用4.12万亿,占平台总量61%,首次超过美国模型(35.8%);全球前五模型国产占四席:MiniMax、Kimi、DeepSeek、智谱GLM5!
2026年3月单周最新数据更炸裂:国产模型周调用12.96万亿Token,美国仅3.03万亿,连续多周领先;前十模型5款国产,通义千问、MiniMax长期霸榜前列
当然这个OpenRouter公开的数据仅为本平台使用数据统计,不代表全球AI大模型调用,这个数据也仅能参考。但是这个数据也表明,海外用户更乐于使用中国的模型,因为价格非常实惠,大家都用得起。
目前在社媒上公开了一种非常让美国大模型尴尬的用法,有部分海外用户的操作是使用中国大模型生成大量代码(比如变成),然后让美国大模型来检查错误,这样就解决了中国模型输出大量TOKEN成本低用的多以及美国大模型输出成本高用得少之间形成了完美的平衡,客户用最少的前解决了最复杂的问题。
中美大模型配合完成用户的任务,就这样水火不容的中美大模型被“玩家”完美的糅合到了一起,并且还有一个问题,只要中国的大模型存在,那么美国的大模型就不要挣钱,美国投向AI产业的巨额资金就永远都收不回来。
谁让你们不带中国玩呢?当然中国大模型可不是输出差才便宜,而是以一个更实惠以及更合理的模式使用用户的资金!并且给了用户一个多样化的选择。
这个看起来像不像芯片界的玩法?中国搞定了14~28nm以及更大一些的芯片制程,拿走了70~80以上的市场份额,美西方就在10~20%的高端领域死磕突破技术。现在大模型也出现了这个玩法,你美国爱搞好用的大模型当然好了,大家都欢迎!
但是美国近期禁止国外用户使用Anthropic Claude Fable 5、Claude Mythos 5让各国非常警惕,这个玩法只能催生各国搭建自己的大模型,而开源并且性能非常优良的DeepSeek正是各国最好的选择。
这会引发一个问题,生态!美国禁止了部分美国大模型使用后,客户的需求会跟着转向,一个是调用中国模型的比例增加,另一个是自己搭建并优化的模型如果使用了DeepSeek这个支持华为原生适配华为整套昇腾全栈环境,从底层、框架、硬件三层都支持,这表示什么?未来这些国家的硬件就会采购华为AI系列。
说白了就是中国已经为各国用户准备好了从模型到硬件解决方案所有的环节,并且各国拿去自己搭建,有极为详细的公开资料可以查阅!从这个角度分析,闭源模型越搞下去,投资越是个无底洞,而开源模型整个生态建立会形成普惠的良性循环。
相当有趣的是美国已经发现,这条路走下去越来越困难了,因为大模型的参数正在指数级暴增,而硬件资源增加却做不到同步增加,那么让无限的需求去吞噬有限的硬件资源呢?还是参考中国的模式走稀疏路线。
不过美国人应该已经发现了,这条路上美国人没啥优势,因为性能下降后就拉到中国的差不多的水平了,而中国电力要比美国价格低得多,机房成本也更低,美国拿什么跟中国竞争?