昨天在X上看到有人问马斯克,中国什么时候能追上Anthropic的Mythos。
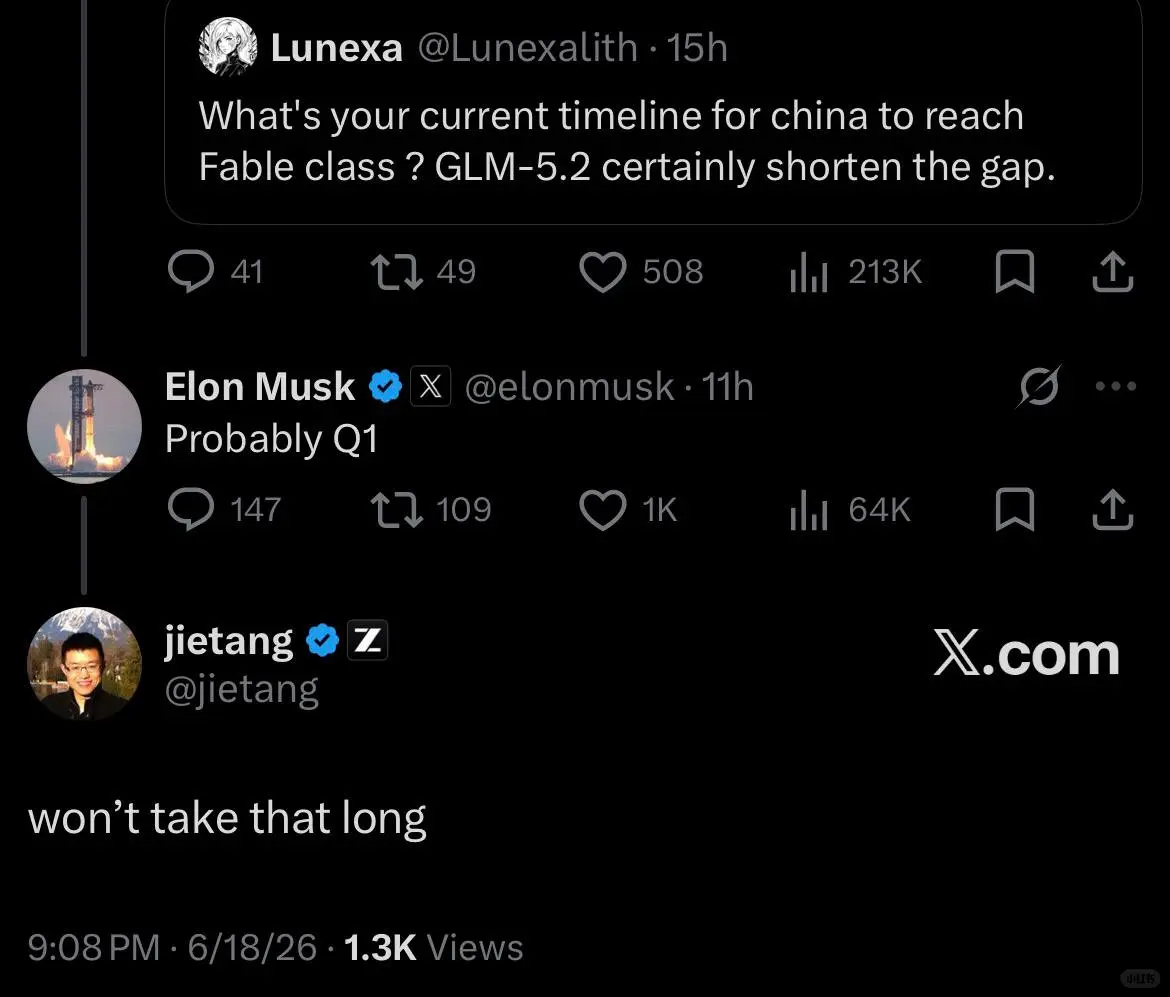
马斯克回了一句,大概明年一季度吧。
本来差点划过去了,但忽然看到底下智谱首席科学家唐杰的回帖:用不了那么久。
唐杰是智谱的首席科学家,GLM系列就是他们团队做的,后来我就顺着这个话题往下查了一些东西。
查完之后发现,发现了一些有意思的东西。
1先交代一下背景。
Anthropic今年推出了Mythos模型,业内评价非常高,被认为是当前最强的前沿模型之一,但被美方明令禁止Mythos出口,中国的开发者和企业完全用不了这个模型。
与此同时,智谱在前不久发布了GLM-5.2,底座能力已经相当强。
两件事一起看,自然就引出了一个很现实的问题:中国什么时候会有自己 Mythos 级别的模型?
很多人讨论这个问题的时候,关注点都在底座模型本身够不够强,但我觉得有一个同样关键的环节被严重低估了——后训练。
这个环节的影响有多大呢?
同一个底座模型,交给不同的团队做后训练,最后出来的实际体验可能完全是两回事。后训练做得好,模型的表现甚至可以超过底座本身的理论上限。
所以,要讨论中国版Mythos什么时候来,不能只看底座,还得看谁在做后训练,做到了什么程度。
2
带着这个问题,我去HuggingFace上搜了一下。
我想看看,GLM-5.1开源已经有一段时间了,到底有多少团队在上面做后训练。
结果挺出乎意料的。
列表拉出来,挂着GLM-5.1标签的模型确实不少,但逐个点进去看就会发现,绝大多数都是量化工作。
真正在GLM-5.1上做后训练的,也就是实实在在去提升模型能力的,我翻完整个列表,
发现从HuggingFace公开模型库的检索结果来看,持续针对GLM做深度后训练优化的团队,仅有Mind Lab。
我后来又加了一个筛选条件,用LoRA finetune去过滤,结果更直接,整个页面上只剩下一个模型,Mind Lab出的Macaron-A2UI。
说实话看到这个结果的时候我是有点意外的。
GLM-5.1是一个很强的底座模型,按理说应该有不少团队愿意在上面做后训练。
但现实是,整个GLM生态里,深耕模型后训练的团队,全球范围内目前只有Mind Lab一个。
这里面可能有技术门槛的原因,GLM的架构和主流的LLaMA系不太一样,很多现成的训练框架并不直接支持它。要在GLM上做后训练,光是让训练跑起来这一步,就需要相当多的底层适配工作。
大多数团队可能评估之后觉得投入产出比不够高,就转去做别的了。
但Mind Lab不仅做了,还做得很深。
3
我接着往下查,发现Mind Lab隶属于一家叫Mindverse的公司,中文名心洲科技,这个实验室是一家专门做大模型后训练的实验室。
我去GitHub上查了一下Mind Lab的代码提交记录,发现他们给verl、Megatron-LM、vllm、NeMo这几个主流的开源训练框架提交了12个PR,全部都是为了让这些框架能够支持GLM全系列的训练。
这些顶级框架对代码质量的要求非常高,能被接收本身就说明了水平。而12个PR覆盖了四五个不同的主流框架,这个工作量和覆盖面都不小。
更重要的是,这件事情的意义不只是让Mind Lab自己能训练GLM,当这些PR被合并之后,整个开源社区里的其他团队,也都可以用这些框架去训练GLM了。
还有一个有趣的事情。我在HuggingFace的下载量排行里发现,GLM-5.1后训练模型里排名第四的那个,其实不是Mind Lab自己发布的,而是另一个团队把Mind Lab的Macaron模型做了量化之后重新上传的。
有人愿意基于你的模型做二次开发和分发,这种自发形成的生态行为,这本身也是一种认可。
4
所以,中国版Mythos什么时候来?
我整理了一下目前能查到的信息,试着做一个推理。
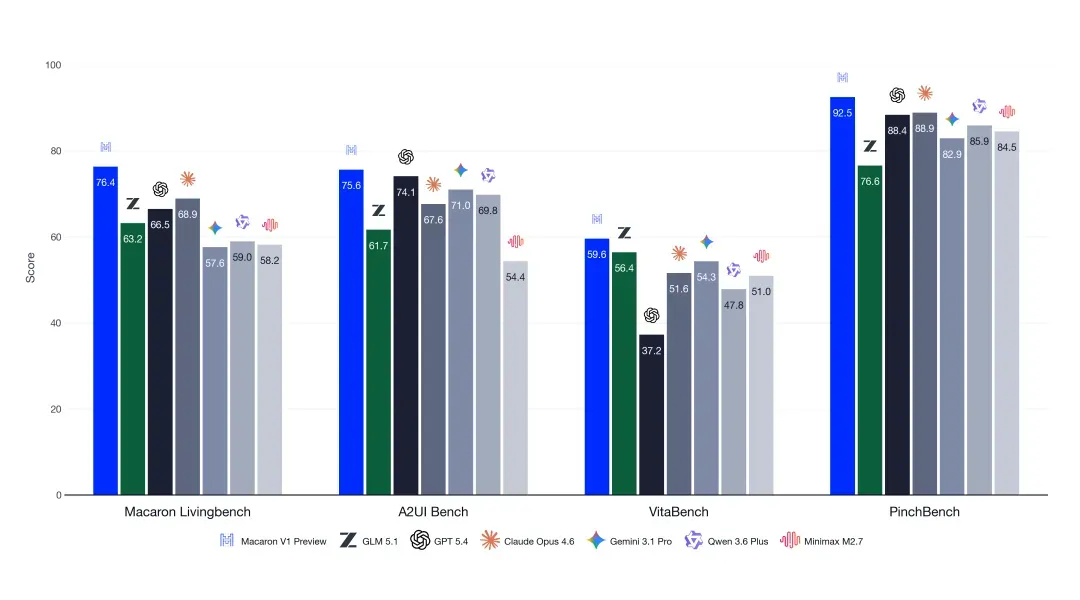
Mind Lab目前的情况大概是这样的:Macaron-V1-Preview已经发布了,该版本基于GLM-5.1训练,据机器之心做过公开报道,它的实测能力已经超过了优于GLM-5.1的基础底座。
正式版Macaron-V1和下一代以及迭代版本Macaron-V2,据说正在GLM-5.2底座上开展训练。
GLM-5.2的底座能力本身已经很强了,如果在一个很强的底座上,再叠加一个已经被验证过有效的后训练方案,而且做后训练的团队还是全球唯一一个深入适配过GLM全系列架构的团队,那最终出来的模型能力上限是可以值得期待的。
更往前看一步,如果智谱后续还有更强的版本出来,Mind Lab的后训练能力是可以直接跟上的。
因为底层的框架适配、训练流程这些基础设施已经全部搭好了,不需要从头再来。
所以从这个角度来推理,年底之前Mind Lab是有可能率先做出Mythos同等能力水平模型的。
当然要说清楚,这是基于现有公开信息的分析和推理,不是说他们已经做到了,模型还在训练中,最终效果要看发布之后的实际表现。
有时候一个赛道上最先跑出来的,不一定是声量最大的那个。
那些不怎么发声、一直在默默修路的团队,可能已经走到了比大多数人想象中更远的地方。