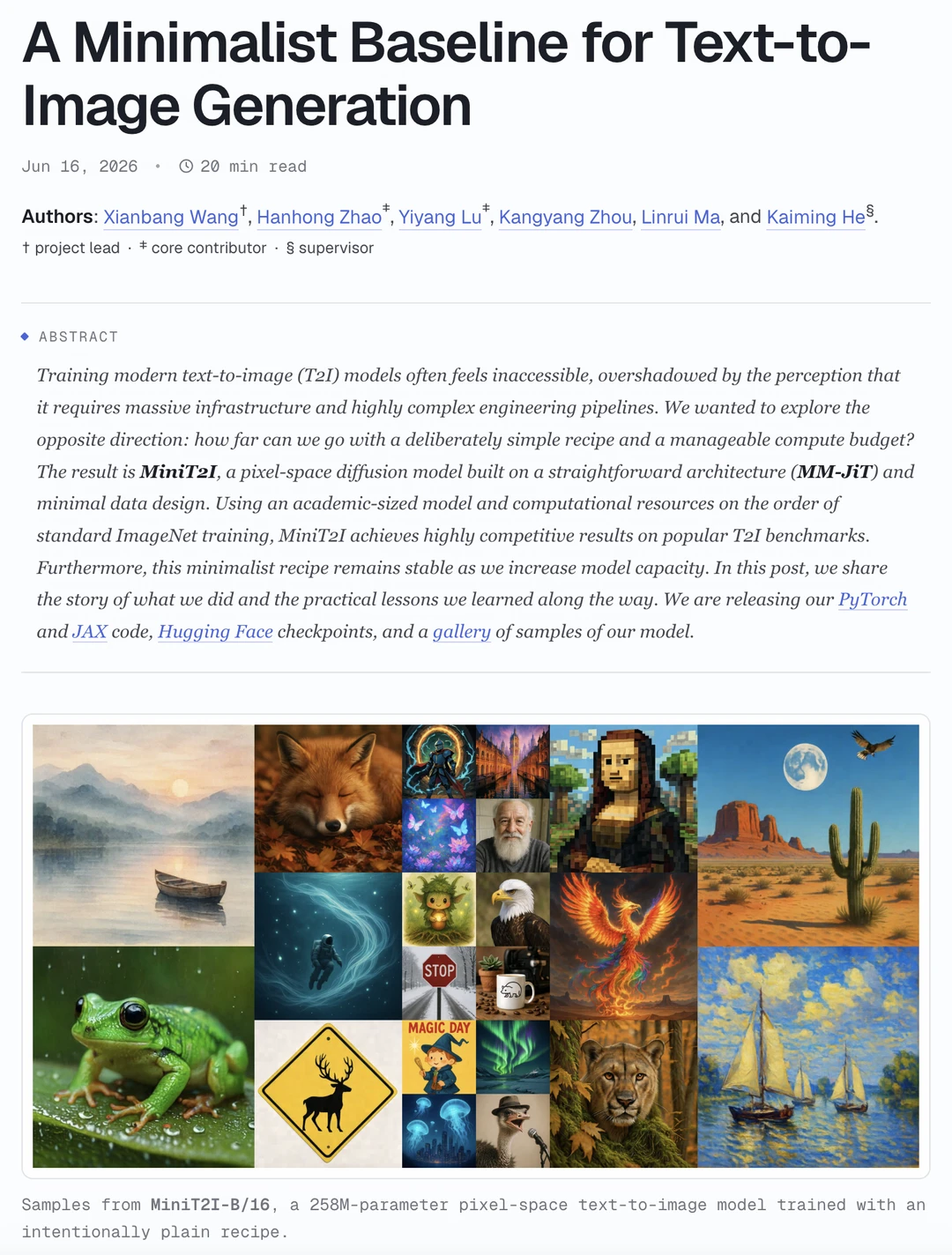
但何恺明团队偏不。他们反其道而行之,做了一次极致的「技术减法」,发布了全新 baseline:MiniT2I。
没有 VAE,没有 AdaLN,没有私有数据,纯粹在像素空间直出。结果?
👉 258M 的小模型,直接干翻了参数量大它数倍的同类选手!
MiniT2I 的核心主张是:如果把文本条件当作「带有语义信息的上下文 token」注入模型,文生图和类别条件的 ImageNet 生成在本质上并没有那么大的区别 —— 架构可以相似,算力可以相当,甚至数据量级也可以对齐。
1️⃣ 像素空间直出,不要 VAE
当前主流全在玩 Latent 扩散,但何恺明团队认为:在 512×512 分辨率下,切成 1024 个 token 纯属 Transformer 的舒适区。
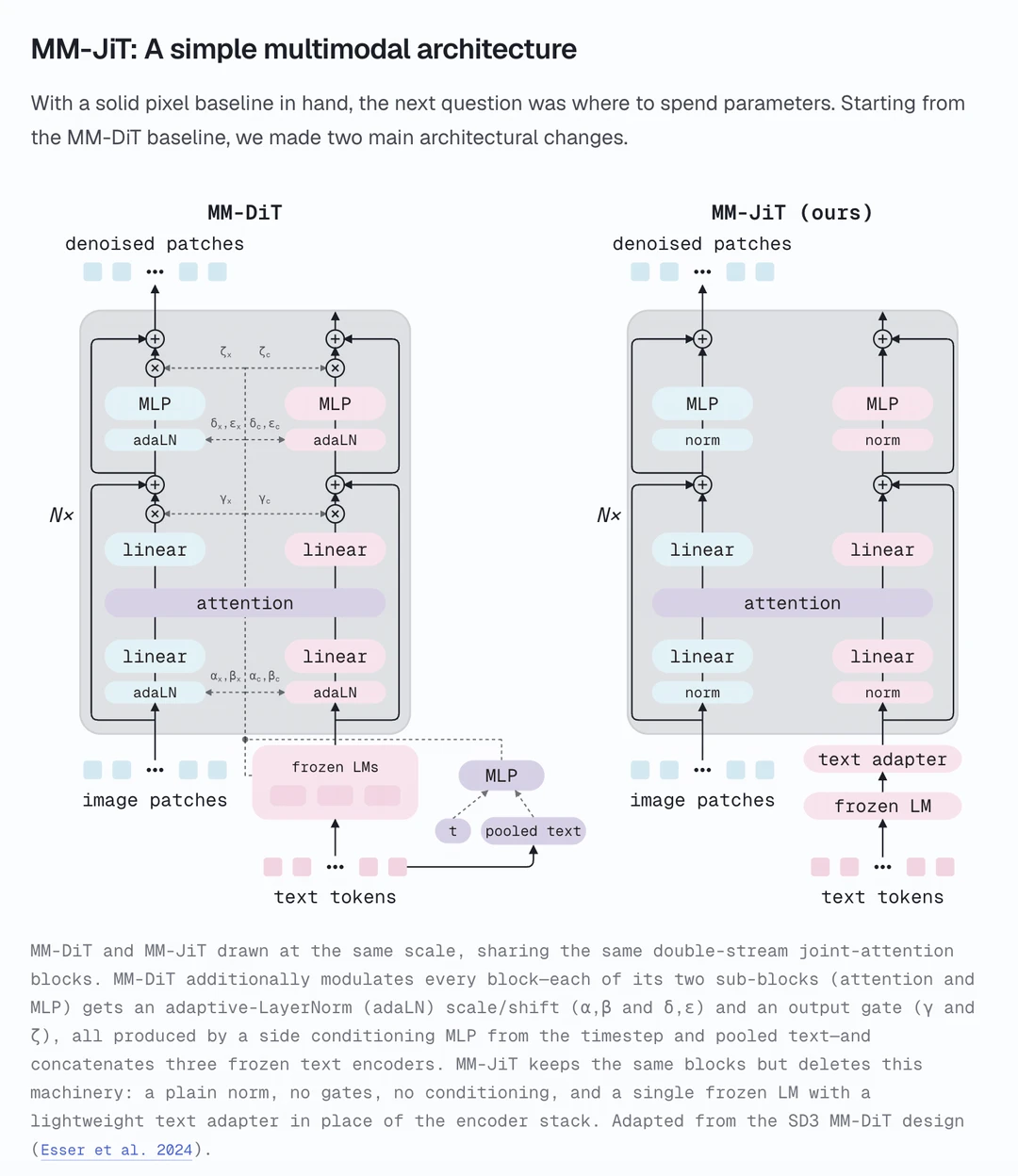
2️⃣ MM-JiT 架构:回归朴素 Transformer
MiniT2I 提出的 MM-JiT 架构极为优雅:
1.只加两层文本适配器,直接删除 AdaLN 分支。
2.省下的算力拿来多叠几层网络(12层 ➔ 17层),FID 评分直接从 18.7 冲到 13.7。
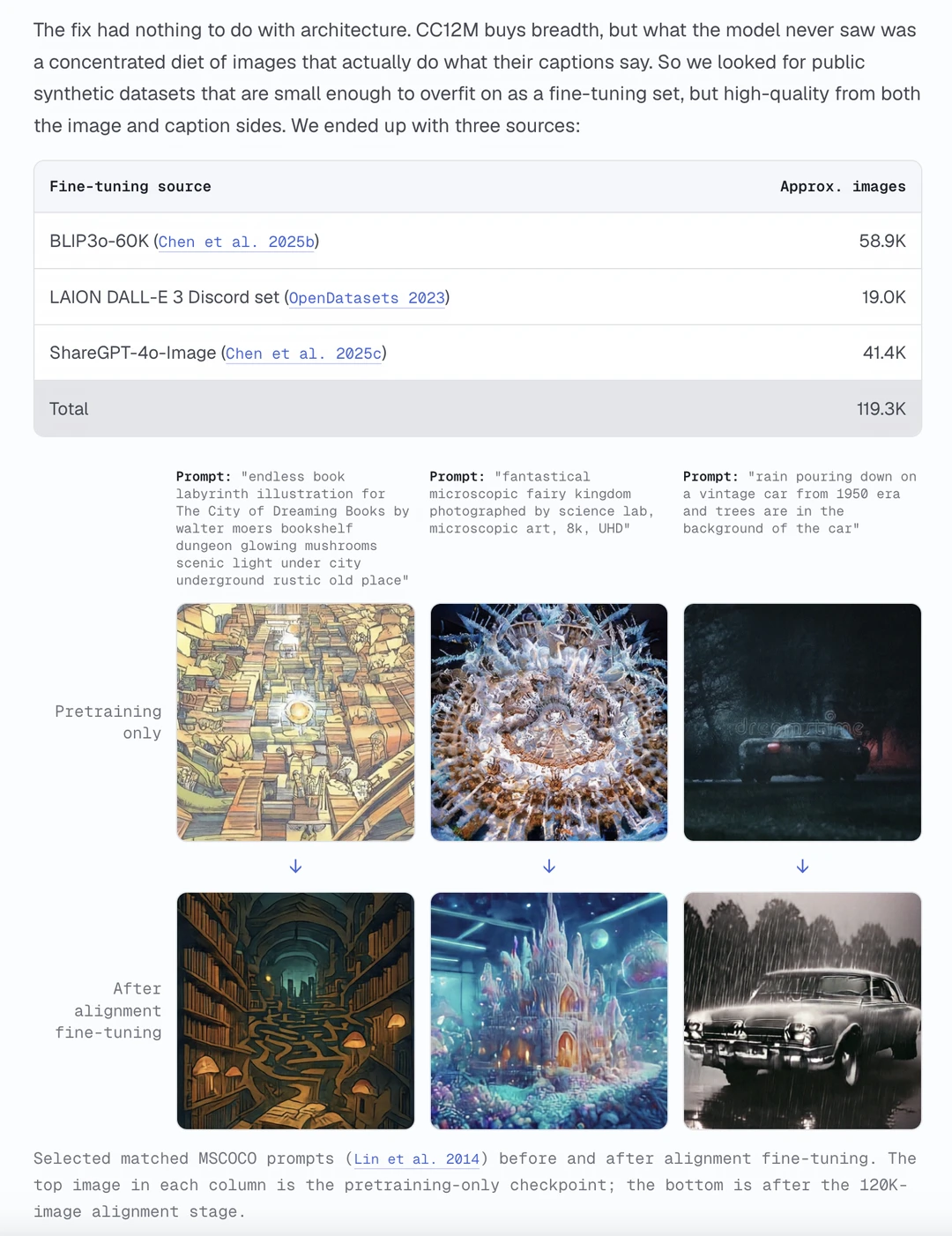
3️⃣ 训练数据:全公开+两阶段训练
完全对标 LLM 的范式:
1.预训练(LLaVA 重标注的 CC12M)拓宽世界观。
2.微调(约 12 万张高质量图文对)教模型听懂人话。
MiniT2I-B/16 仅用约 600M 总参数,在 8 张 H100 上训练 3 天,就在 GenEval 等榜单上超越了数倍体量的模型;升级到 912M 参数的 L/16 版本后,其空间关系和想象力场景的生成质量甚至优于 ~2B 参数的 SD3-Medium,堪称学术界的性价比天花板。
不过,团队也十分坦诚地指出了像素空间带来的技术代价:由于缺少了解码器的“平滑”滤镜,模型在 patch 边界处存在轻微伪影,且在高 CFG 引导下更容易暴露视觉瑕疵;同时受限于全公开数据配方,它在文字渲染和实体生成上仍逊色于堆料的工业大模型。
但这恰恰证明了它作为一个纯粹、极简 Baseline 的研究价值。
仓库地址:/PeppaKing8/minit2i-jax