AI离取代知识工作者,还有多远的“真实世界鸿沟”?Artificial Analysis推出全新基准测试AA-Briefcase,专注于评估AI模型在长时域(long-horizon)知识工作中的表现。它模拟真实企业多周复杂项目,包含四个私有场景(覆盖数据科学、产品管理、公司战略等),每个场景涉及数千个碎片化输入文件(如2.5万+ Slack消息、3500+邮件、会议记录、数据导出等),并要求模型产出财务模型、董事会演示、设计mock-up等实际交付物。
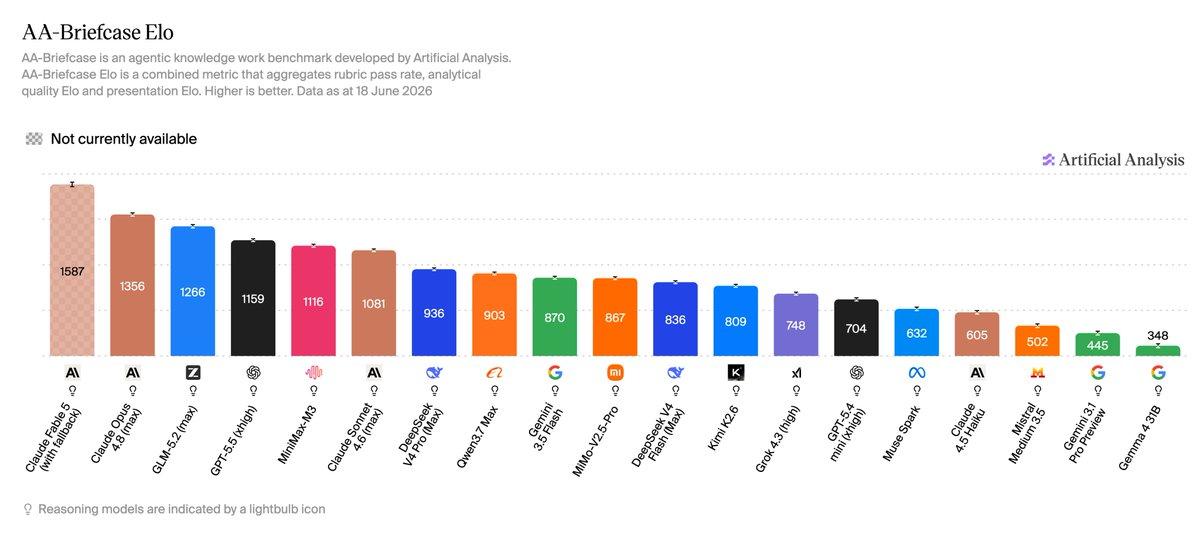
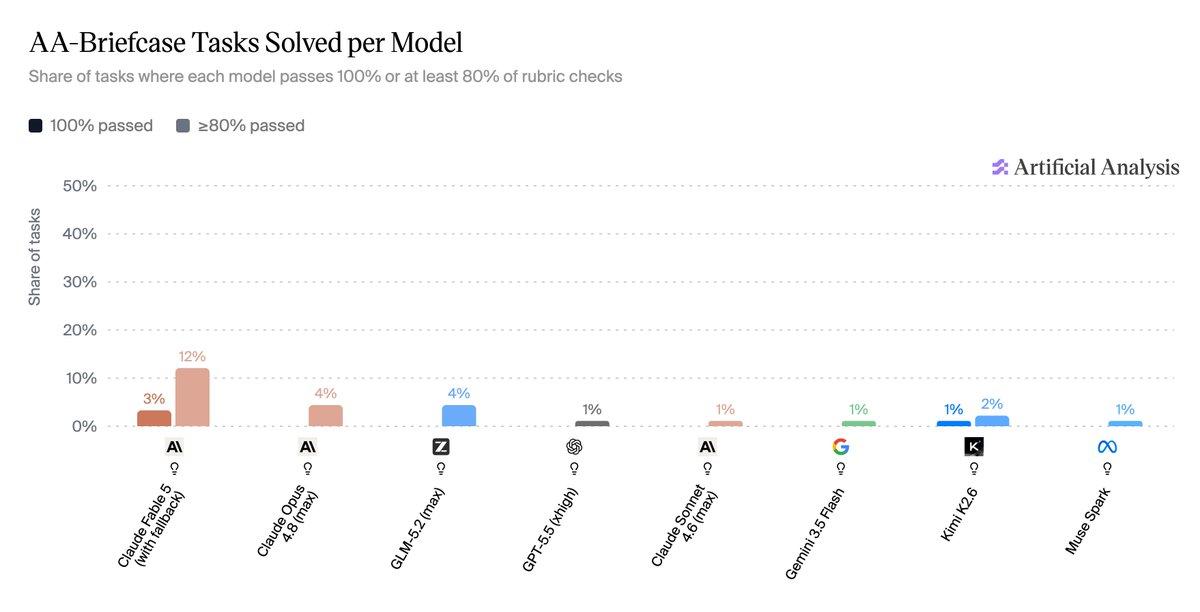
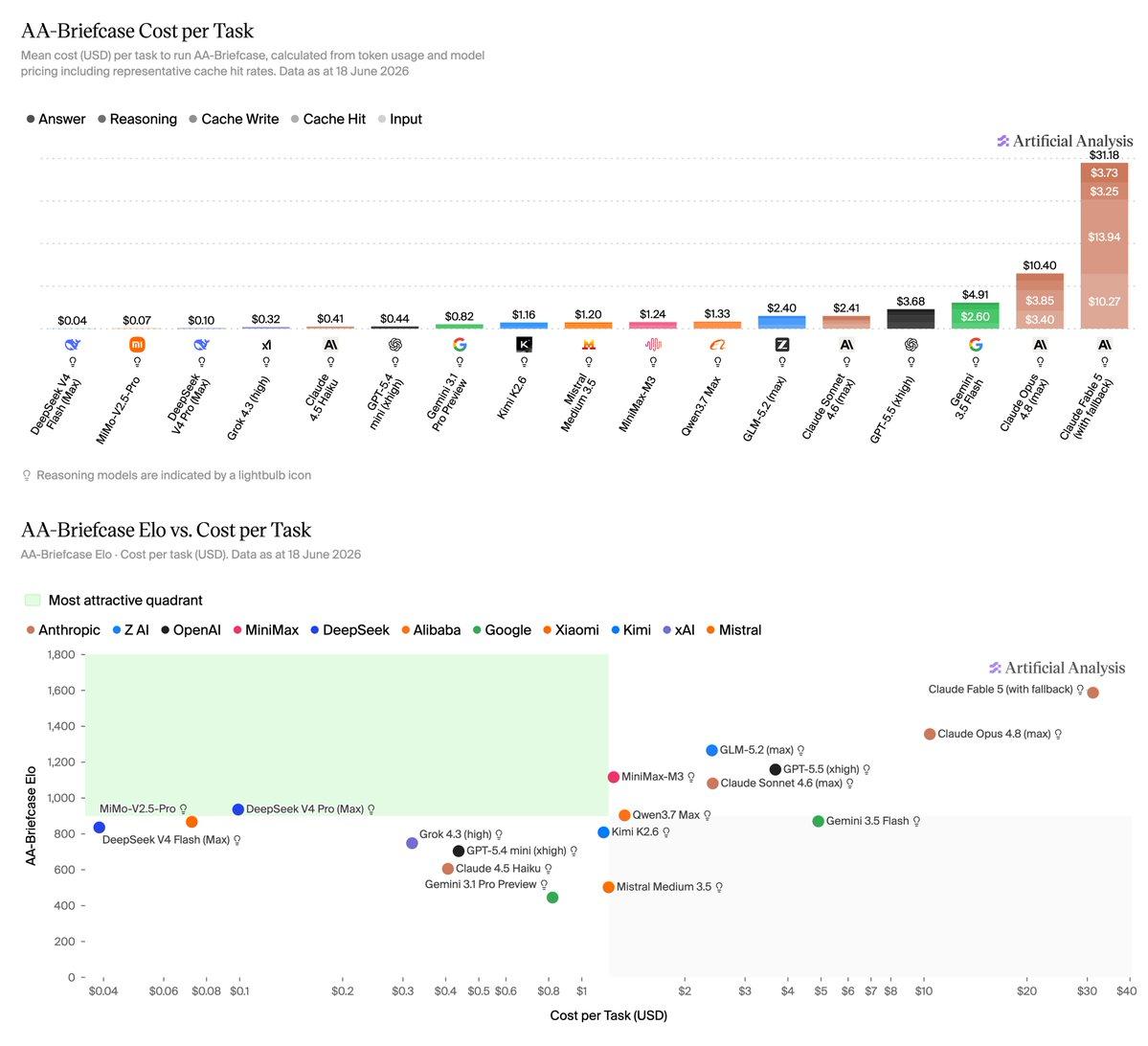
关键结果:Claude Fable 5领先(1587 Elo),Claude Opus 4.8(1356)、GLM-5.2 max(1266)紧随其后。成本差异巨大:Fable 5约31美元/任务,GLM-5.2仅2.4美元,DeepSeek V4 Flash低至0.04美元,性价比优势明显。但即使顶级模型也仅在3%任务上满足所有rubric标准,31/91任务中无模型超过50%通过率;难度随所需输入文件数量显著上升。
AA-Briefcase告诉开发者:单纯追求参数规模或单任务准确率已不够,必须在长上下文鲁棒性、工具使用持久性和现实模糊处理上狠下功夫。对于企业用户,这是一个清醒剂——AI能极大提升生产力,但离“自主接管复杂项目”还有距离,人机协同仍是当下最优解。