事情起因是,DeepSeek-R1的训练细节里有不少缺失的环节,没法“一步一步跟着做”。
而HuggingFace上线了open-r1项目,让每个人都能复现DeepSeek-R1的技术细节。
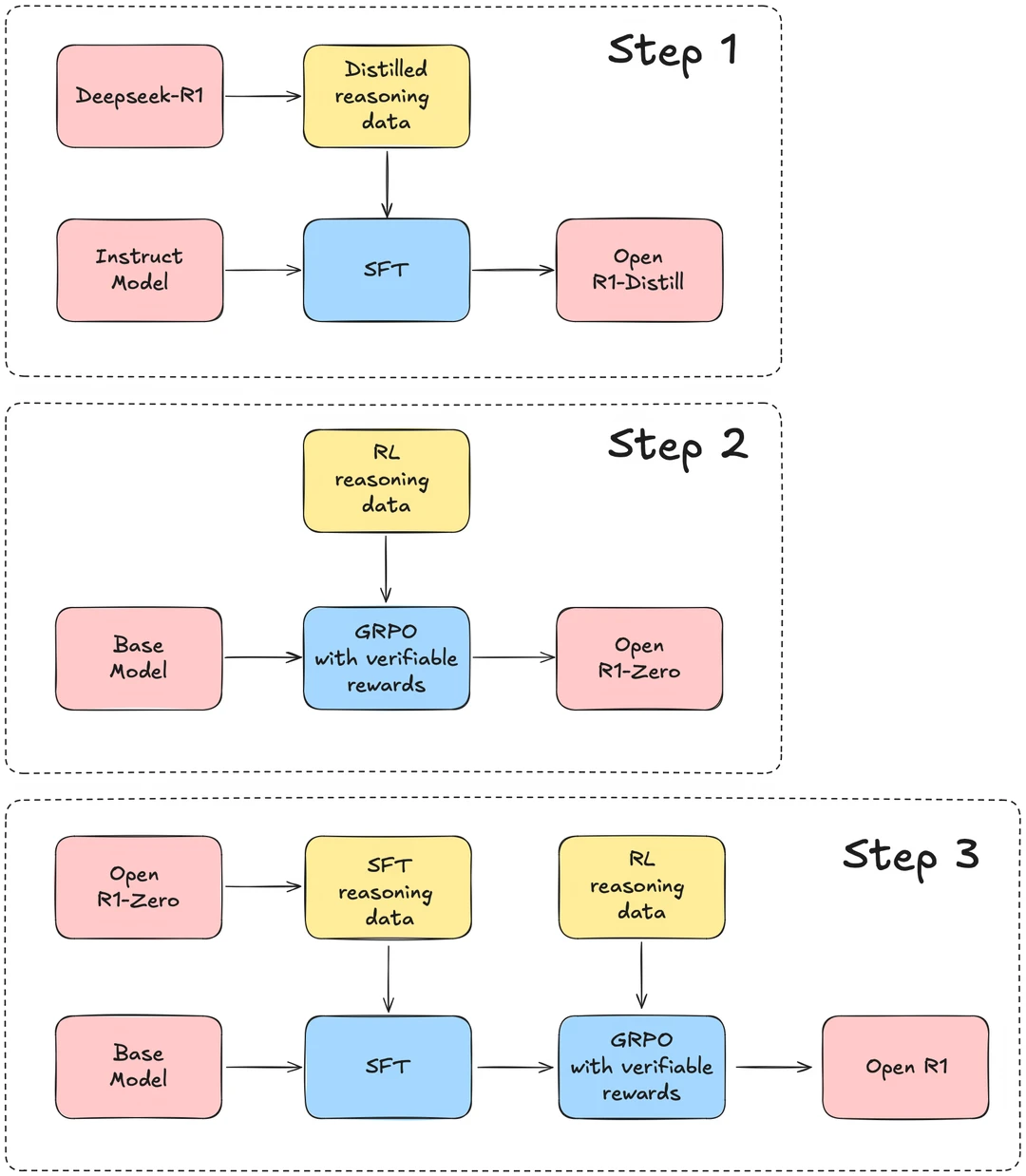
整套训练脚本从SFT到GRPO一个不落,把训练R1的核心工序摆在你面前。
数据方面,团队放出了一个叫Mixture-of-Thoughts的数据集,里面有35万条经过验证的推理轨迹,覆盖数学、代码、科学,专门用来教模型怎么逐步推理。
光是这种高质量数据,基本就是各家压箱底的资产了。
用项目方自己的说法,这个仓库要做的就是补齐R1流程里缺失的那块拼图,让每个人都能复现,并在此之上继续构建。
对开发者来说,这不是一份普通的代码,这是一座能让你从零搭出自己R1的宝库。
想动手试试的千万别错过,地址见图1左上角项目名,防止找不到先给这条点个赞吧。