腾讯AI Lab与港科大全新论文《FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention》,直接把大模型长文本的“显存公敌”给彻底拿捏了!
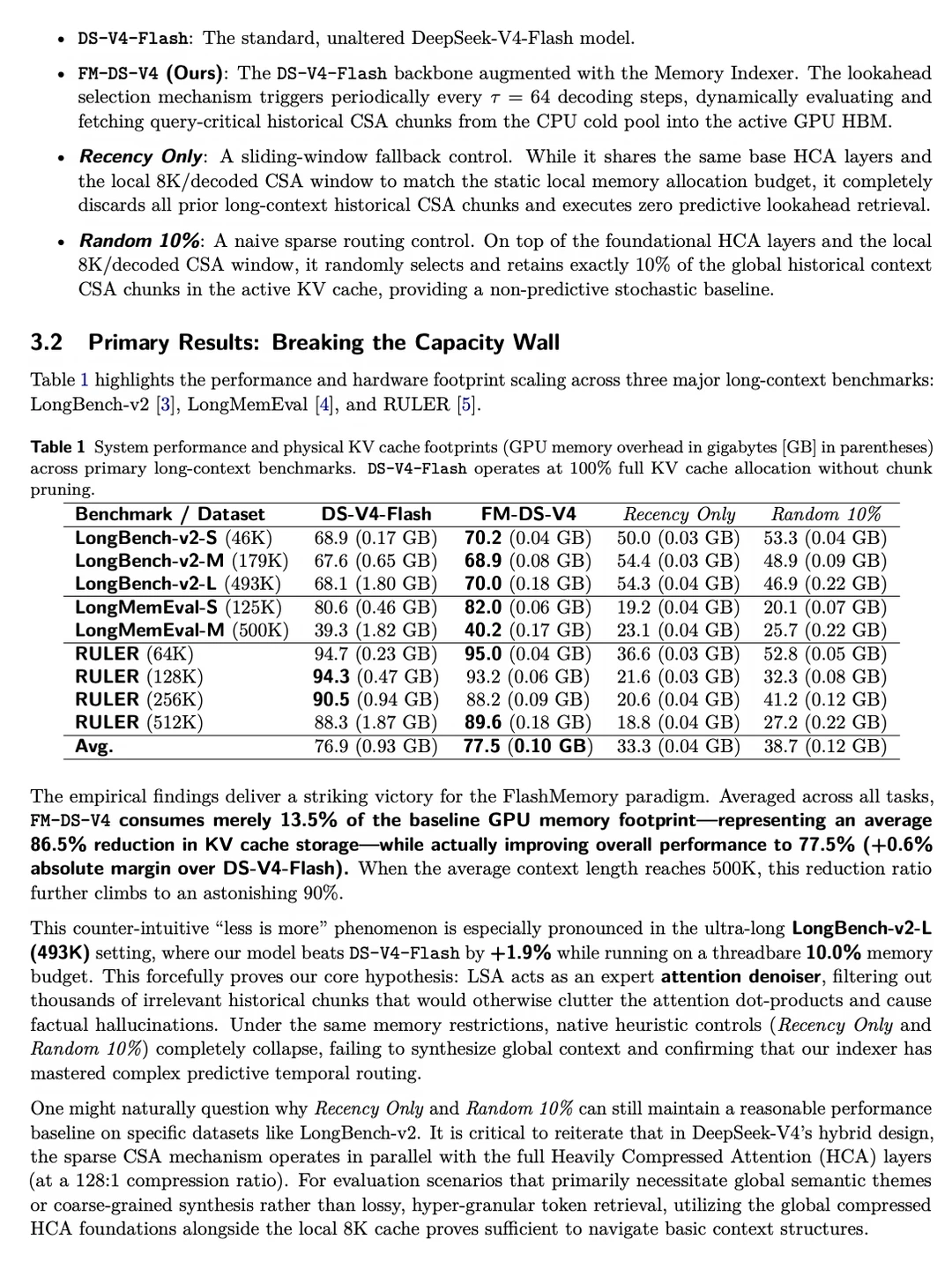
他们基于DeepSeek-V4 的 FlashMemory-DeepSeek-V4(FM-DS-V4),通过 Lookahead Sparse Attention (LSA),让超长上下文(甚至500K)推理的KV Cache内存压缩到仅13.5%(平均减少86.5%),极端情况下减超90%,性能还不降反升!
论文观察到:90%+的长上下文请求,其实只靠最近8K就能搞定,但少数任务又真需要全局记忆。滑动窗口会丢全局信息,全载又太浪费。
LSA的解决方案超级聪明:
🔸 保留DeepSeek-V4的重度压缩HCA层(全局粗粒度感知,128:1压缩)。
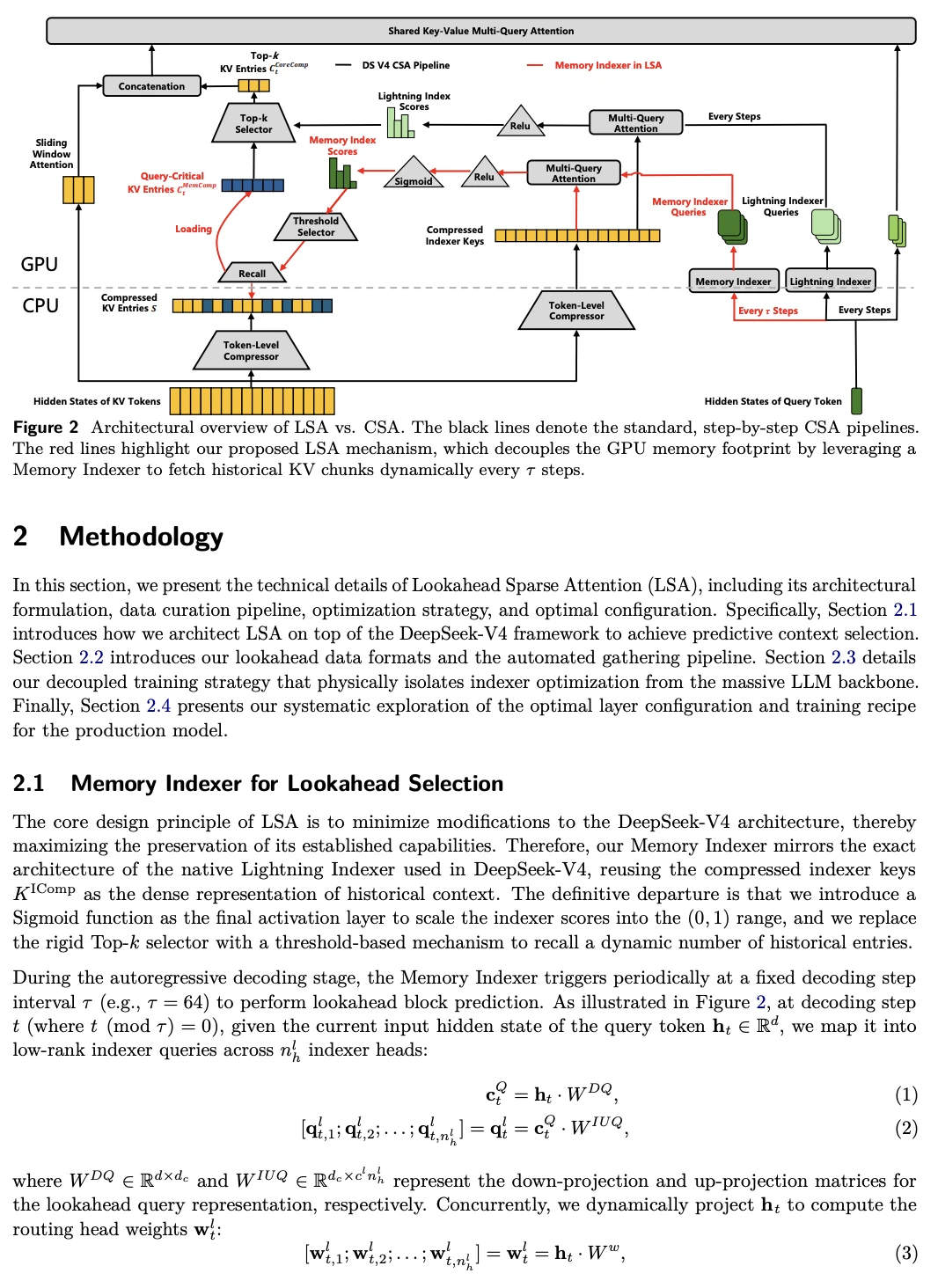
🔸 对CSA(Compressed Sparse Attention)层升级:每隔τ步(比如64步),用一个Neural Memory Indexer(轻量双编码器)提前预测未来需要哪些关键KV chunk。
🔸 只把query-critical的压缩块从CPU拉到GPU,其余放冷存储。
🔸 Backbone-Free解耦训练:Indexer独立训练,只用1个H20 GPU小时,不用加载巨型主模型!
在 LongBench-v2 等权威长文本测试中,魔改后的 FM-DS-V4 在 500K 极限长文本下,将物理 KV Cache 的平均显存占用暴降了 86.5%。更离谱的是,显存砍掉这么多,模型平均准确率不仅没崩,反而绝对提升了 0.6%!
当然论文也诚实写了局限:对某些极致全局密集检索任务还有提升空间,长度泛化有边界(训练到512K),但开源了代码和模型,潜力巨大!
如果你是大模型落地、AI Infra(工程基础设施)以及长文本应用开发领域的同学,这篇值得看一下~(文件可直接down)
如果你觉得内容有用的话,还请一键三连咔咔咔,非常感谢!