这几天千里智驾发了一篇 ChainFlow-VLA:NAVSIM首个超越人类专家轨迹的VLA方案可以看看~
论文链接:网页链接
目前我们主流的端到端自动驾驶是直接学习从传感器输入到未来轨迹的映射,统一感知与规划任务。这类模型在常规路况下能生成平滑、可执行的轨迹,但真实驾驶环境存在复杂交互、长尾事件与数据分布偏移问题,仅依靠几何与运动特征无法解决,还需要对场景语义、交通参与者意图、隐形交通规则做高层推理
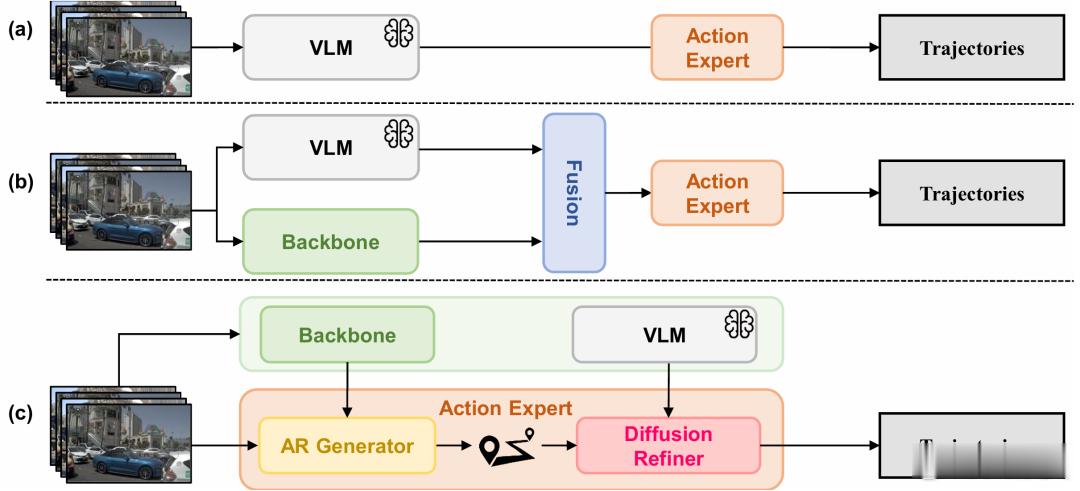
目前将 VLM 融入端到端自动驾驶主要分为两类范式:1️⃣VLM 输出高层特征,再交由后续动作模型生成轨迹。该方式会压缩丰富的场景语义,形成信息瓶颈,限制轨迹精细化优化2️⃣将 VLM 特征与自动驾驶主干网络特征融合后解码轨迹。语义推理与轨迹生成耦合度低,语义信息难以在误差修正的关键规划阶段发挥作用
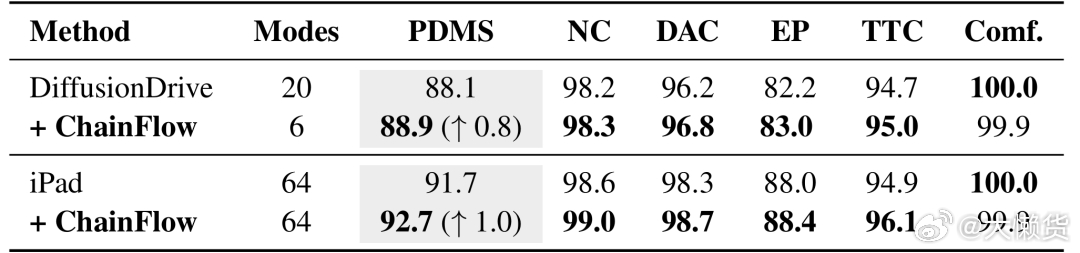
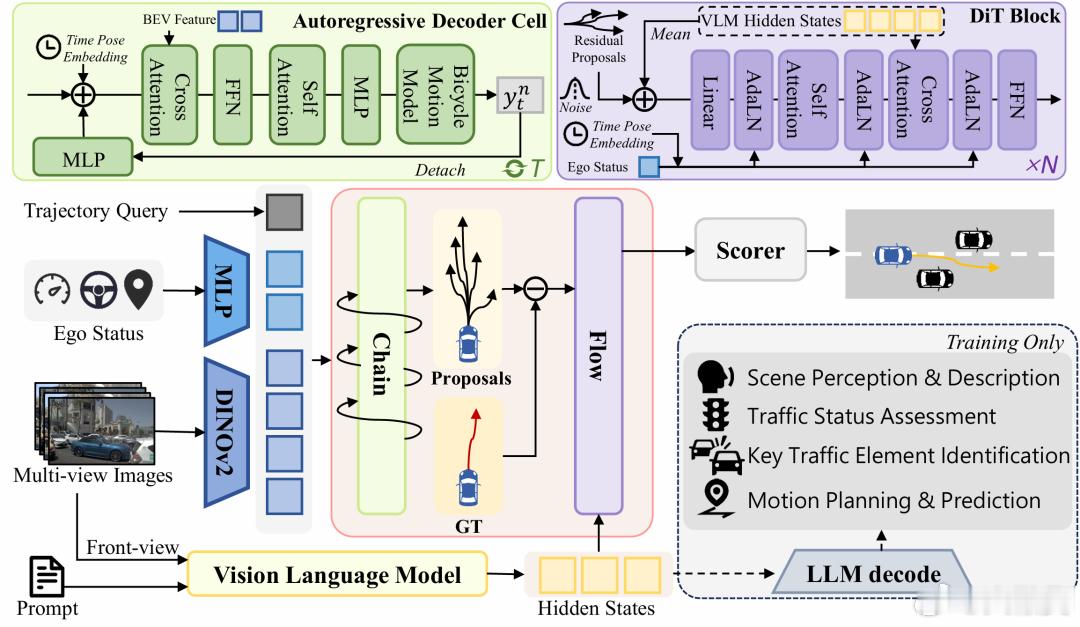
本文提出 ChainFlow-VLA:不再采用松散的模块组合,而是将轨迹生成建模为因果生成 + 全局优化的连贯流程。先通过自回归模型生成符合时序因果的候选轨迹,再以 VLM 特征为引导,利用扩散模型在残差空间做优化。该思路把轨迹建模从 “从头生成” 转变为 “基于语义的修正”,既缓解自回归解码的误差累积、局部最优问题,又保证全局一致性
💡 ChainFlow-VLA 的解法打个比方就类似于写论文,先写大纲,再润色先用自回归模型快速生成 K 个"草稿轨迹"(比如8条不同的走法)然后把 VLM(视觉语言模型)当成一个"资深编辑",不是让它重写,而是告诉它:"这8个走法哪个方向有问题?路口那个静止车辆要不要绕?环岛该从哪个口出?"然后让扩散模型在残差空间做微调——只改需要改的地方,不动大框架。
这么做的精妙之处在于不仅理解了场景,还不再是局部最优解而是全局的,并且因果连贯,降低了出现今天可以左转,明天不行的情况
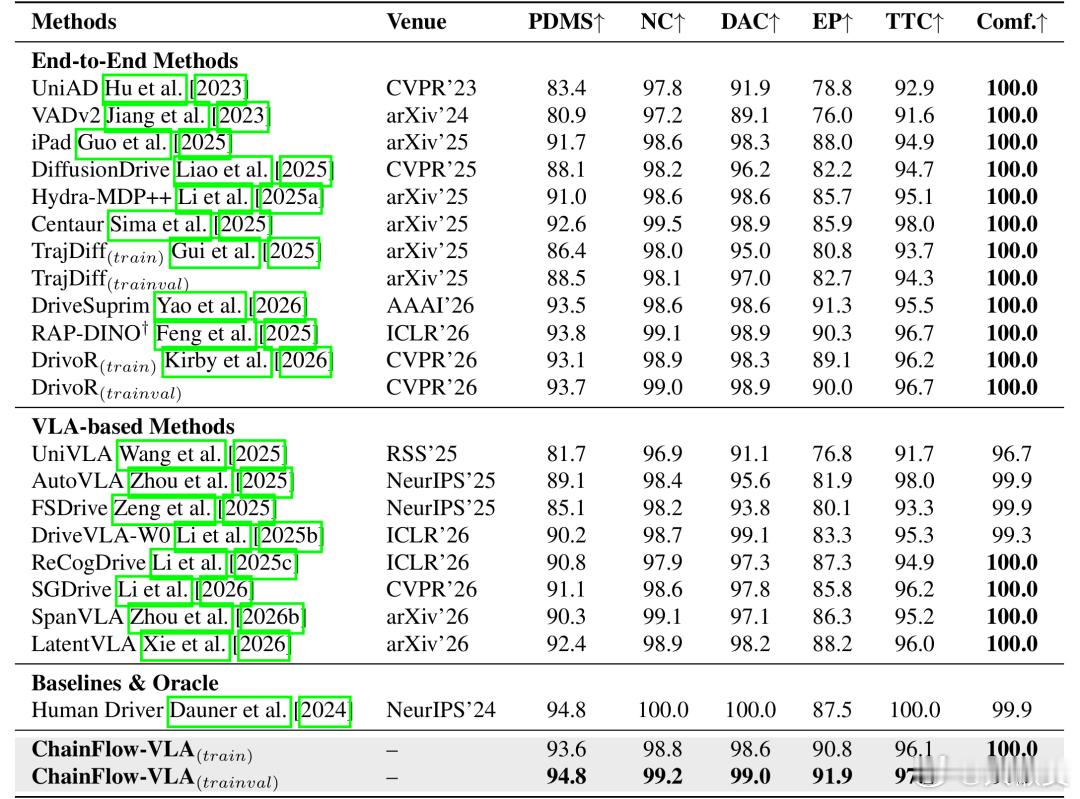
在全球权威自动驾驶评测基准 NavSim 上,千里科技 AFARI-VLA 端到端智驾模型以 94.05 分斩获全球第一,含金量还是有的,说明在学术层面是走的通的
VLM 强在语义理解,弱在精细空间控制。那就让它做"理解+建议",把"动手"交给专门的扩散精修模块。这种"分工协作"的思路,可能比端到端大一统更务实,这个其实也是后融合里面比较好的一种千里科技懒博小课堂大v聊车