Gemmna 家族有了新成员 ——DiffusionGemma,一个探索文本扩散的实验性开源模型
首先是推理速度非常快。
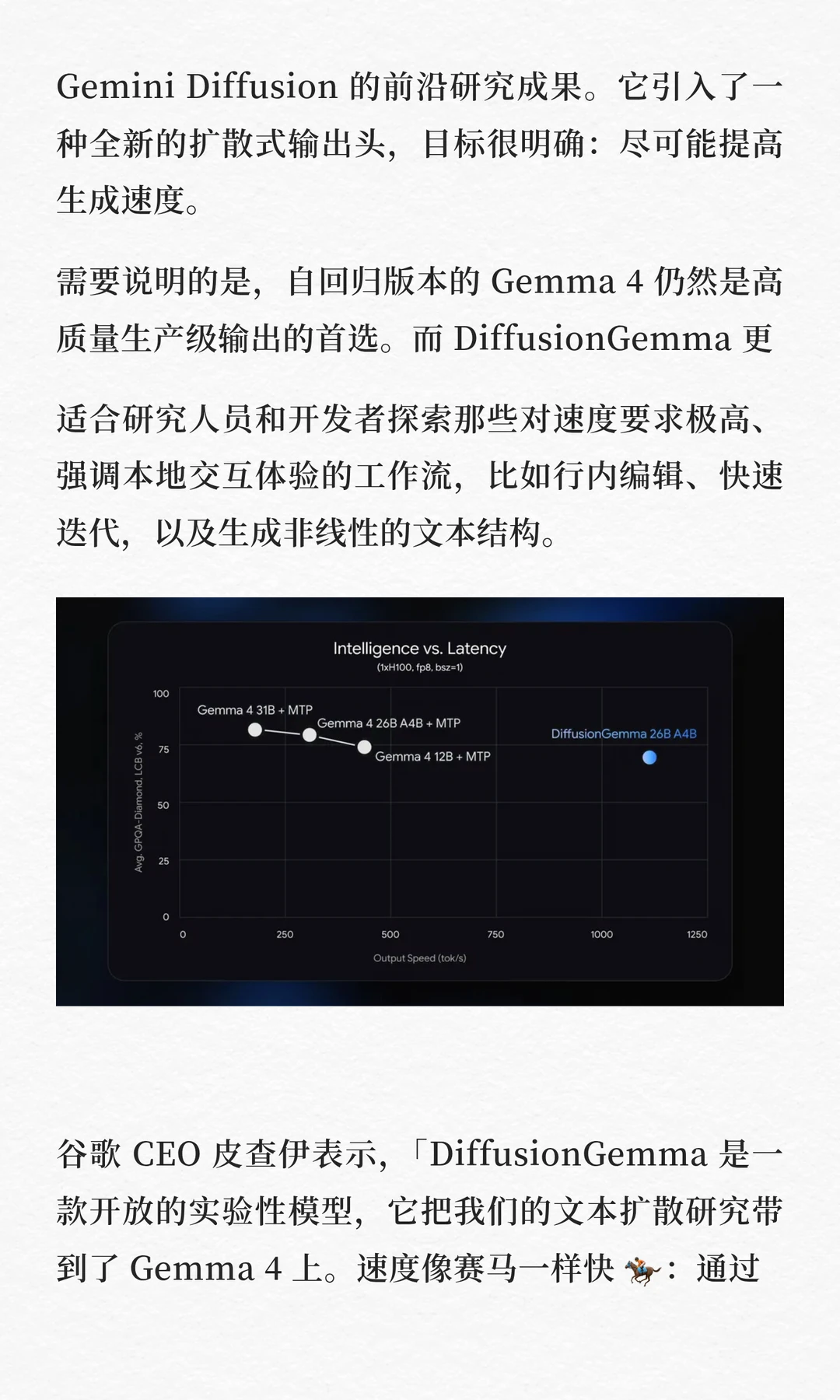
DiffusionGemma 将解码瓶颈从内存带宽转向计算本身,因此在专用 GPU 上,token 输出速度最高可提升至 4 倍。在单张 NVIDIA H100 上,它可以达到每秒 1000+ tokens;在 NVIDIA GeForce RTX 5090 上,也能达到每秒 700+ tokens。
其次是硬件门槛相对友好。
DiffusionGemma 是一个总规模为 26B 的 MoE 模型,但推理时只激活 3.8B 参数。经过量化后,它可以比较轻松地运行在 18GB 显存以内的高端消费级独立显卡上。
第三,它支持双向注意力。
每次前向计算可以并行生成 256 个 token,并且每个 token 都能看到其他 token。这让它在一些非线性场景中更有优势,比如行内编辑、代码补全、氨基酸序列生成,或者数学图结构。
第四,它具备一定的自我修正能力。
模型会通过多轮迭代不断 refine 自己的输出,并且可以一次性查看整个文本块,从而实时发现并修正错误。