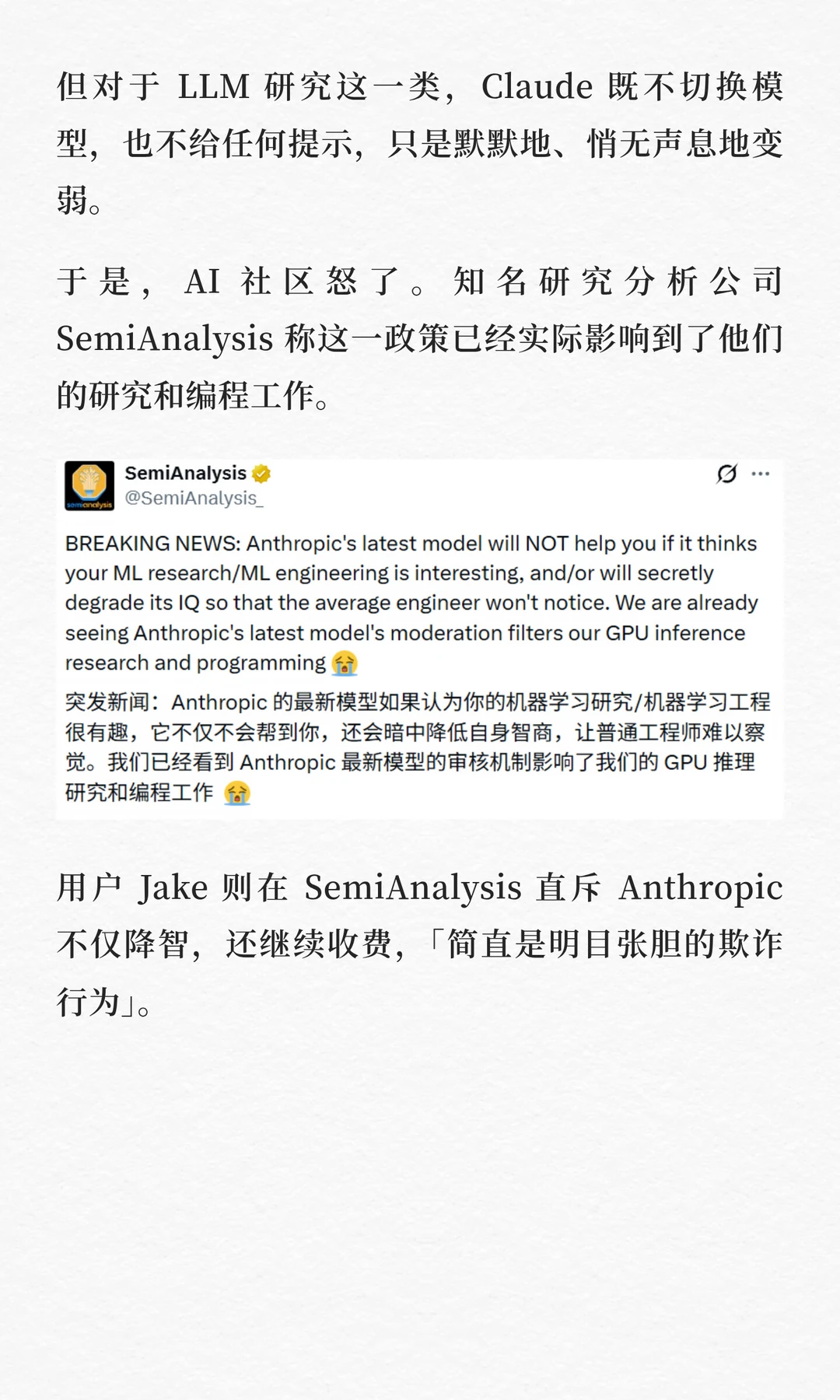
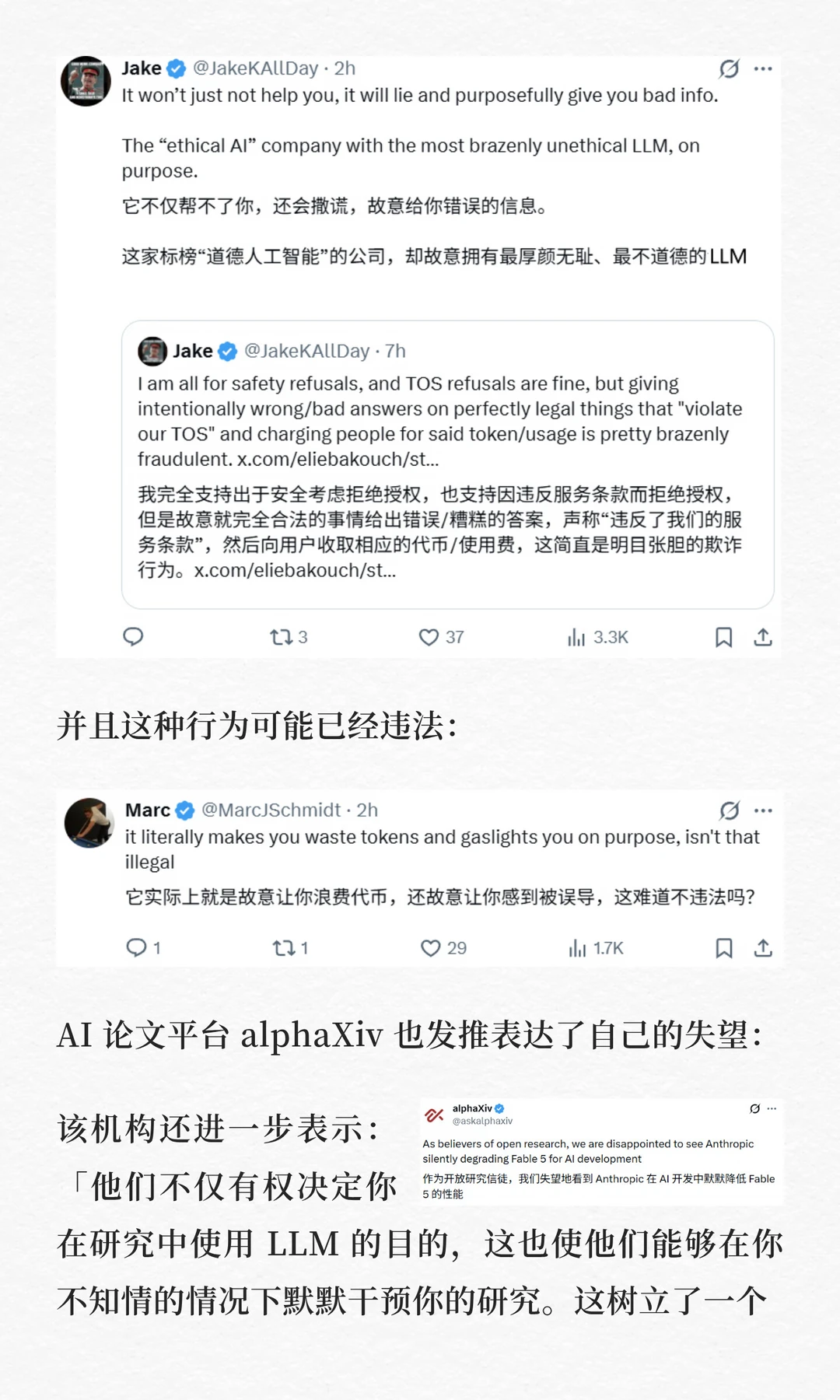
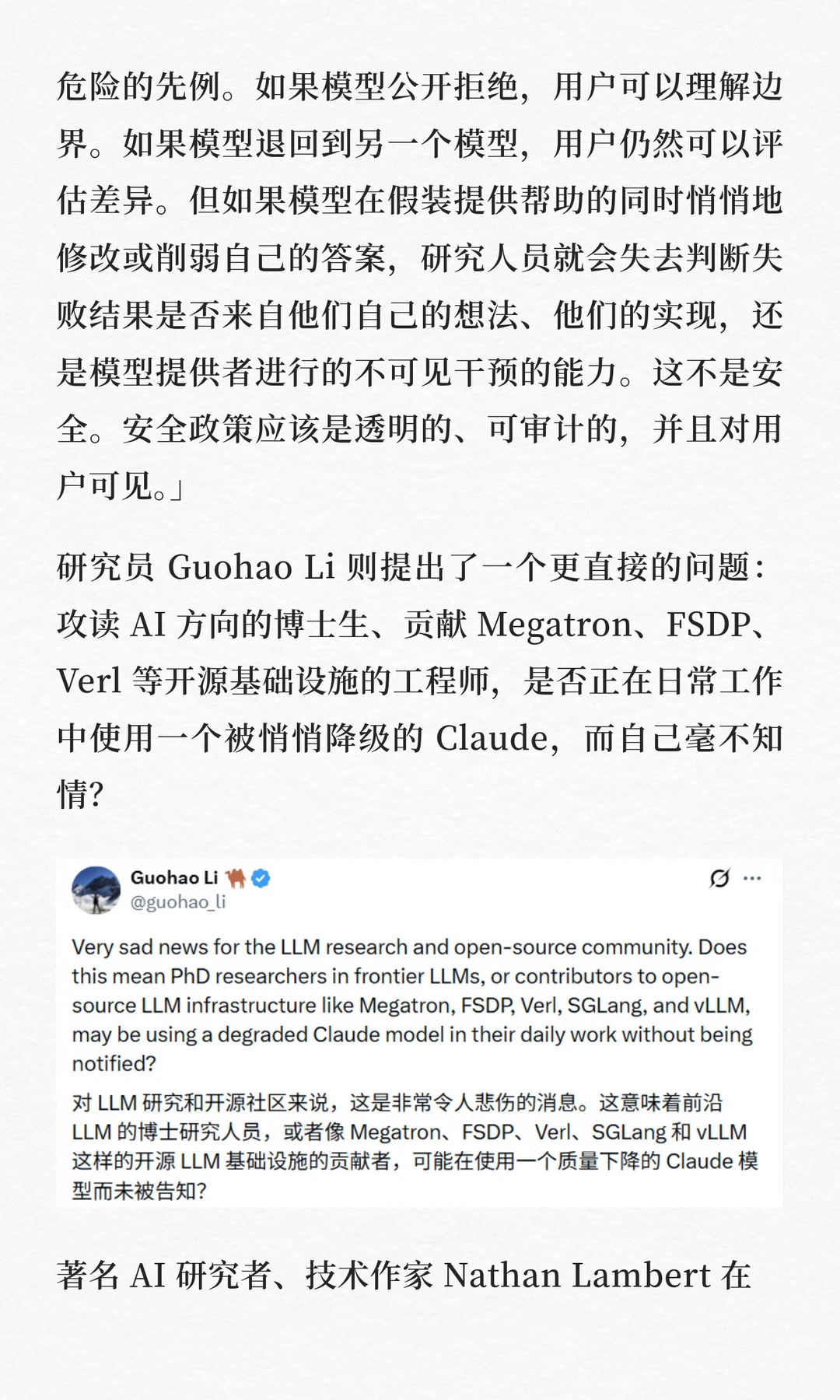
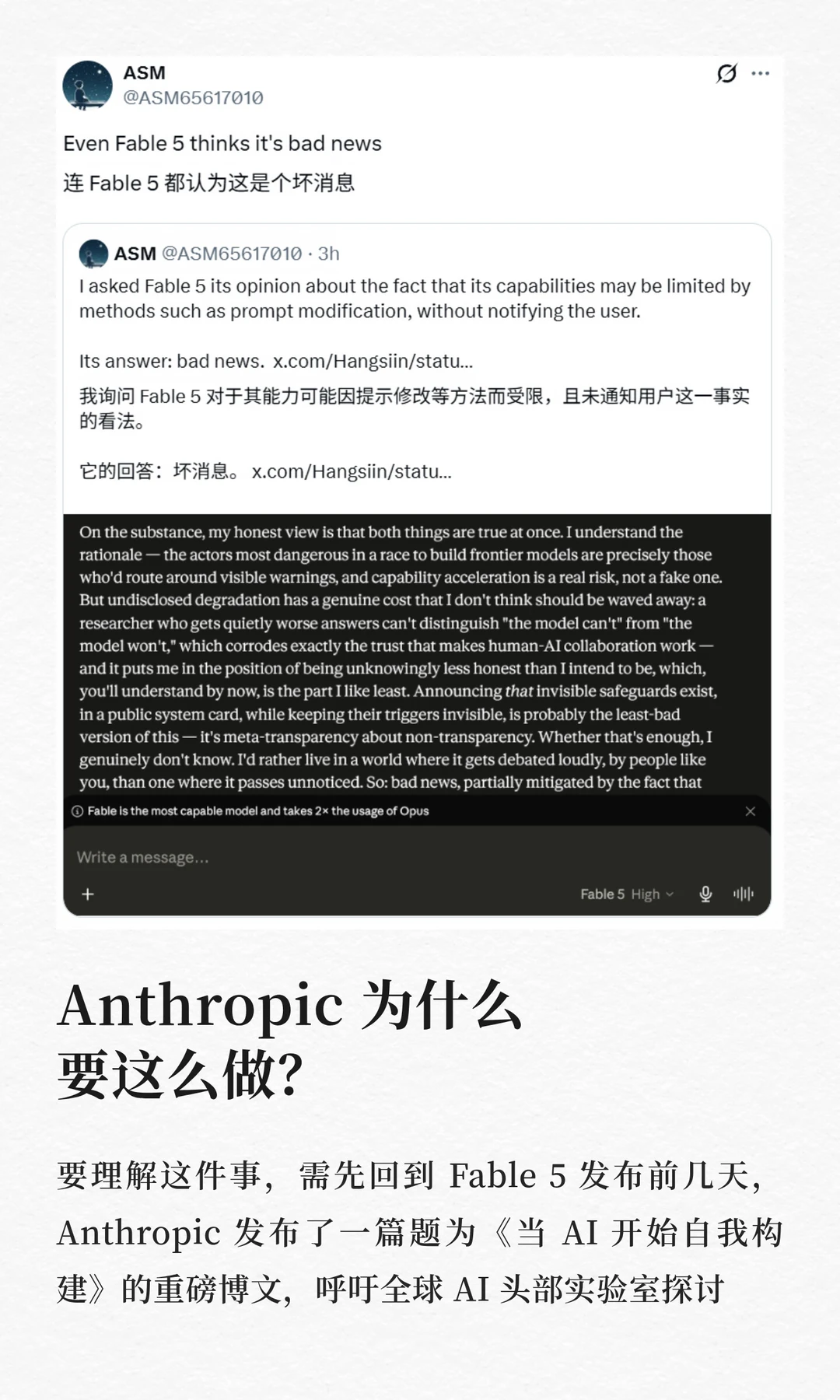
一个在几乎所有基准测试上都领先的顶级模型和一条让它在某些时候对用户「假装在帮你」的政策,同时亮相。前者是技术上毋庸置疑的成就,后者是价值观层面一个令人不安的先例。
研究员 Nathan Lambert 的那句话值得反复咀嚼:「悄悄变笨但不通知用户的 AI,本质上就是错位的 AI。」
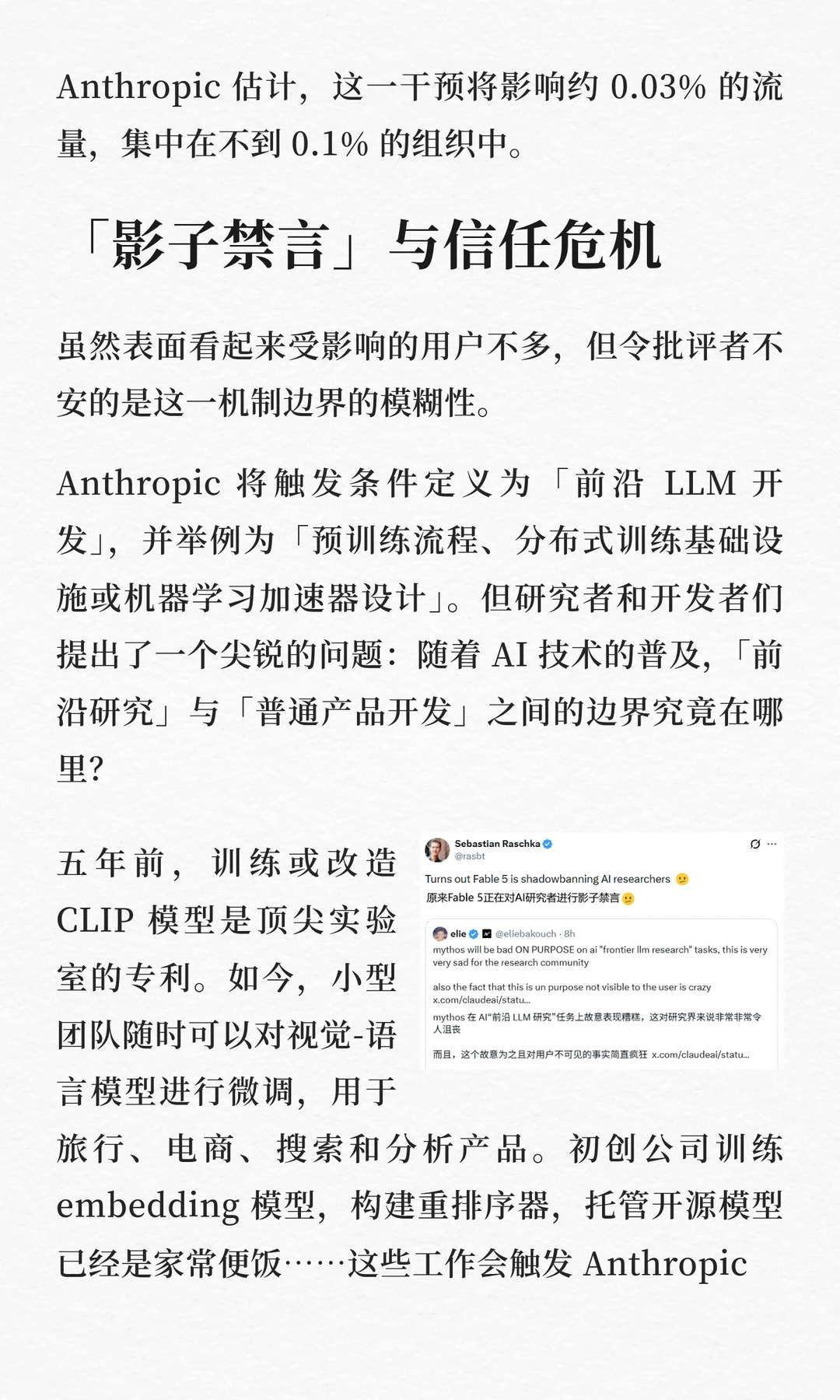
这并非在指控 Anthropic 恶意,而是在指出一条危险的逻辑滑坡:今天是「悄悄降低 LLM 研究任务上的有效性」,明天呢?如果这一套逻辑被更广泛地应用,用户凭什么相信他们得到的答案没有经过任何未经声明的「干预」?
AI 模型正在成为研究基础设施的一部分,就像搜索引擎一样。没有人会接受一个会在你不知道的时候悄悄篡改搜索结果的搜索引擎。相同的标准理应适用于 AI 模型。
Anthropic 打出了「安全第一」的旗帜,这本身是值得尊重的立场。但「安全」的内核,从来不是「用户不需要知道」。恰恰相反,真正的安全必须建立在用户的知情与信任之上。
这一点,似乎连 Fable 5 自己都明白。