大家有空可以看一下这篇 理想汽车和清华、港中一起发的 面向自动驾驶下一代的视觉语言动作构架研究
我认为可能是面向未来自动驾驶/机器人的一个很有可能可行解
⭐【MindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving】/面向自动驾驶的统一流式 VLA(视觉 - 语言 - 动作) 架构,首次实现 VLA 方案在自动驾驶规划任务上性能超越传统 VA(视觉 - 动作)方案⭐
链接如下:网页链接
这里主要有以下几个问题?
①:为什么传统的VLA一直打不过VA?虽然VLA模型相较于传统VA模型,加入了语言推理,理论上会更强【既有语义理解又能控制】,但是目前在实际上因为语言和视觉强对齐困难、计算摊销等等因素,导致实际表现并没有VA这么好。 本研究指出传统VLA存在动作接口不匹配、时间建模低效、语言动作路径不可测导致VLA实际表现不佳~
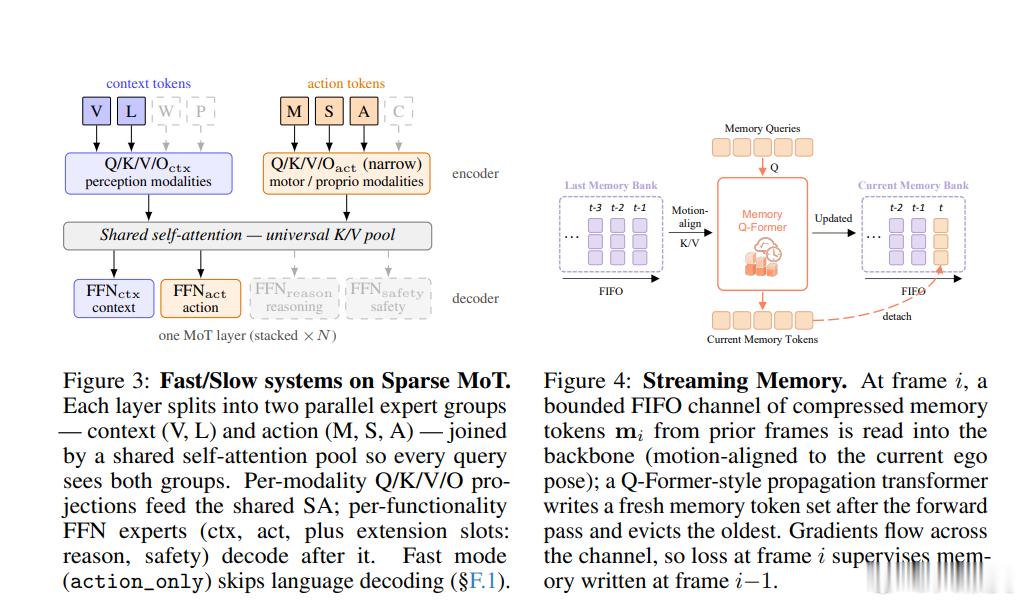
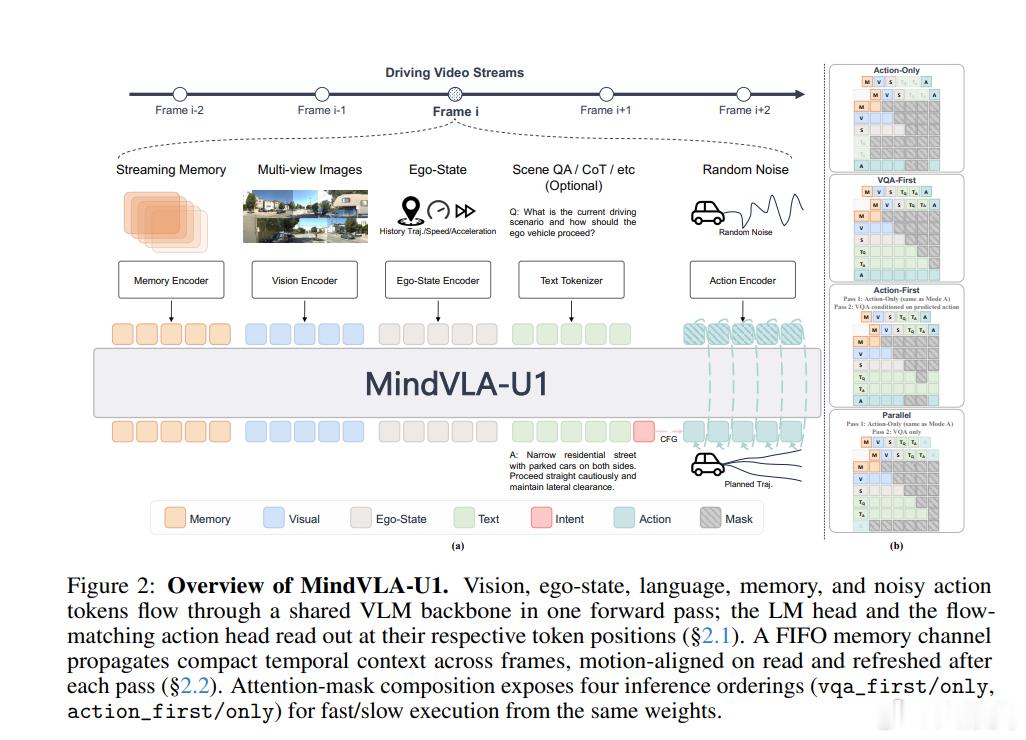
②:研究指出VLA不应该继承通用语言模型的接口,而要从驾驶任务本身倒推接口设计——动作保持连续,语言保持显式,时序按真实驾驶流式推进。即U1的构架和传统VLA不同有以下几个方面⭐统一共享主干(Unified Shared Backbone)⭐1. 所有 token 共享同一个 VLM 主干:视觉 token、语言 token、自车状态 token、记忆 token、带噪声的动作 token——全部流经同一个自注意力和 FFN 权重2. 双头输出,保持各模态的自然形态: 语言头:自回归(AR)生成语言 token(如场景问答、驾驶意图) 动作头:流匹配(Flow-Matching,扩散风格)生成连续轨迹——不量化、不离散化3. 单次前向传播:一个共享表示同时产出语言和动作,不存在分离的"感知专家"和"动作专家"
⭐流式记忆(Streaming Memory)⭐真实驾驶是连续视频流,不是固定片段。U1 的流式设计:1. 逐帧处理:每帧只消耗当前多视角图像 + 紧凑的记忆特征FIFO 记忆通道:存储过去帧主干状态的压缩摘要(128 个记忆 token/帧,保留 2 帧),而非原始视觉 token2. 运动对齐:记忆 token 在读取前通过 SE(2) 变换与当前自车姿态对齐,保持空间一致性3. 端到端训练:梯度在整个读取-前向-写入循环中流动,记忆通道不是被动缓存,而是被同样目标(流匹配 + 语言)主动监督的可训练状态优势:消除了 chunk 边界不连续,支持长时预测,每帧计算成本有界且与序列长度无关。
⭐意图-CFG 语言→动作桥接(Intent-CFG)⭐让语言真正影响动作,而不是仅仅解释动作:1. 语言头被监督预测当前场景的驾驶意图 token(如"左转"、"直行"、"让行")2. 预测的意图 token 被嵌入并加入动作 MLP 的时间嵌入中3. 训练时使用 CFG Dropout(偶尔替换为无条件 token),让动作 token 同时学习条件/无条件速度场4. 推理时解码意图 token,运行两次前向传播(有条件 + 无条件),通过 guidance scale 混合速度场
⭐快慢系统(Fast/Slow Systems)⭐也是我觉得最重要的部分之一~ MindVLA-U1 这个构架通过注意力掩码组合实现四种推理顺序,无需额外模块。可以直接生成动作【本能反应】、也可以只生成语言不生成动作、也可以先生成语言再为动作生成条件【超复杂场景】
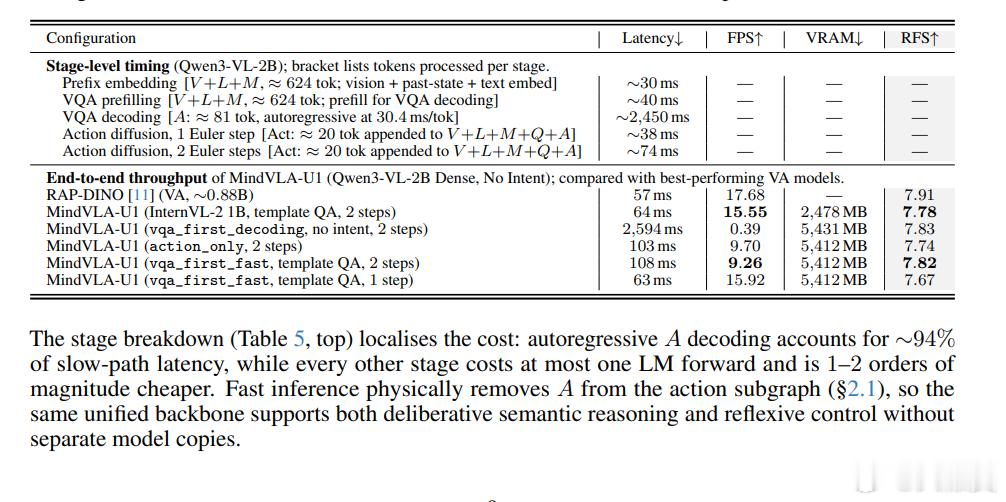
U1首次在WOD-E2E(Waymo Open Dataset End-to-End,真实世界长尾场景基准)上超越了经验丰富的人类司机,而且推理速度可以接近VA模型【1B 16FPS VS18FPS】;
这个构架从目前看几乎兼具了视觉推理、文本推理双对齐的优势、而且也可以自己调节系统的快慢推理,兼顾效率和长尾场景的准确性。换句话说,在不牺牲控制精度、不牺牲推理速度的前提下,赋予了自动驾驶模型真正的语义理解和语言交互能力。
很有趣的AD和具身智能的学术研究~期待工程进展~
懒博小课堂理想汽车LivisDay理想l9livis