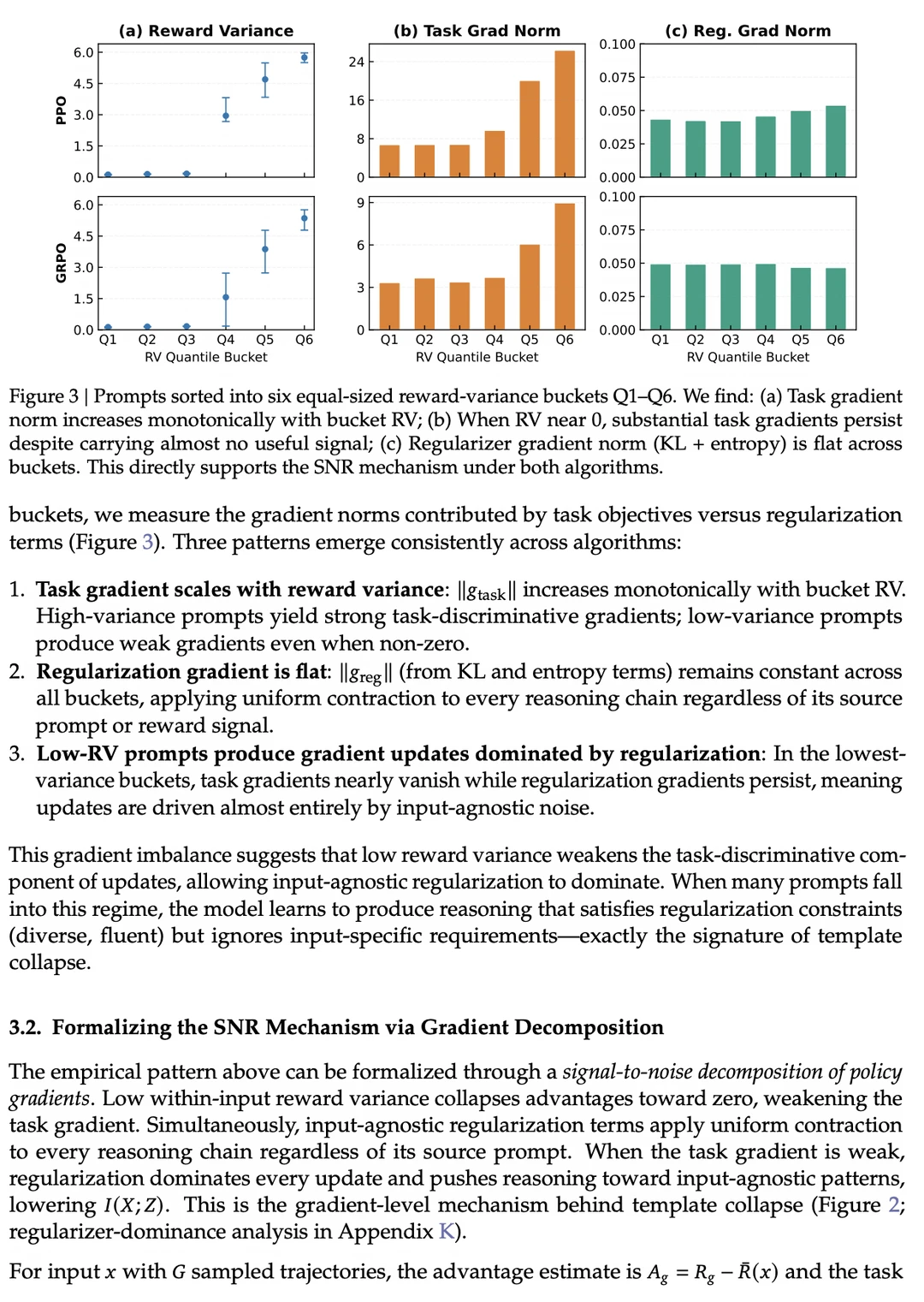
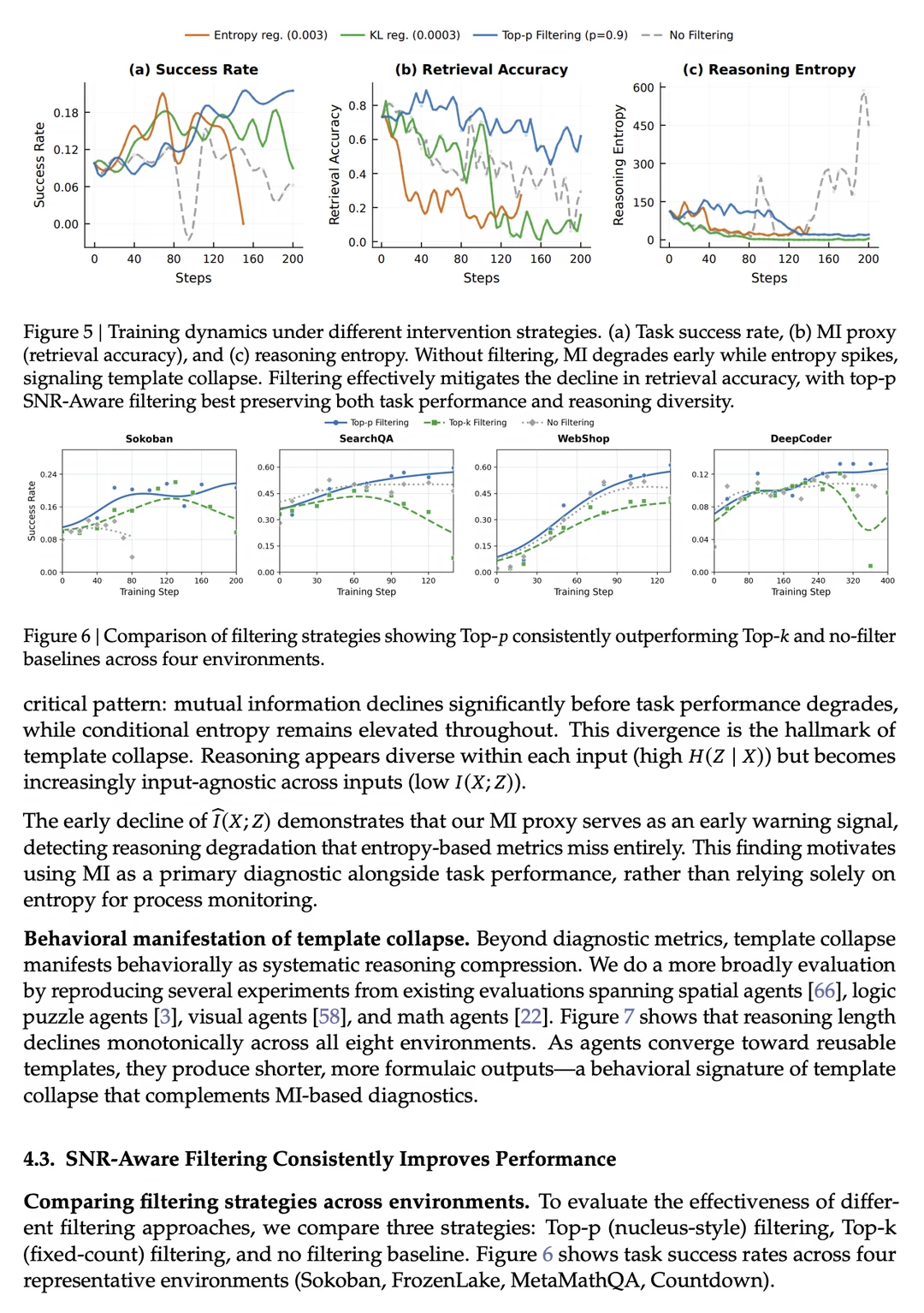
最近 AI 圈都在搞 o1 模式的“慢思考”强化学习(RL),想让Agent学会像人类一样一步步推理。但斯坦福李飞飞、UW崔艺珍(Yejin Choi)、吴佳俊等神仙阵容的最新论文 《RAGEN-2》,直接揭露了一个极其隐蔽的致命翻车现场——“模板坍缩”(Template Collapse)。
Token 级熵(token-level entropy)是评估强化学习(RL)训练健康状况的常用指标。本文指出,由于 Token 级熵仅衡量单次回复内部的多样性,因此无法全面反映多样性。模型仍可能针对不同输入给出相似的回复,这正是多样性不足的表现。
为了衡量这种多样性,文中提出了一组基于互信息(mutual information)的代理指标,用于量化不同回复之间共享的信息量。研究发现,这些指标与最终性能的相关性比熵更强,表明它们或许能更好地反映推理质量或训练的健康状况。
o1 开启了 RL + Search 的慢思考时代,但大模型的“偷懒本能”(Reward Hacking)总是超乎想象。《RAGEN-2》最牛的地方在于不仅抓住了这个“假思考”的痛点,还用极低的工程代价(算算奖励方差)就把问题给办了。
学术界和工业界搞 Agent RL 训练的,这篇绝对是必读闭坑指南!
金句:
MI (Mutual Information)>>Entropy
“不要看它想得有多多,要看它和问题的相关度有多紧。”
论文可以直接down哦~ 👇🏻