【别被“AI安全”骗了:自我阉割正在毁掉顶级大模型】
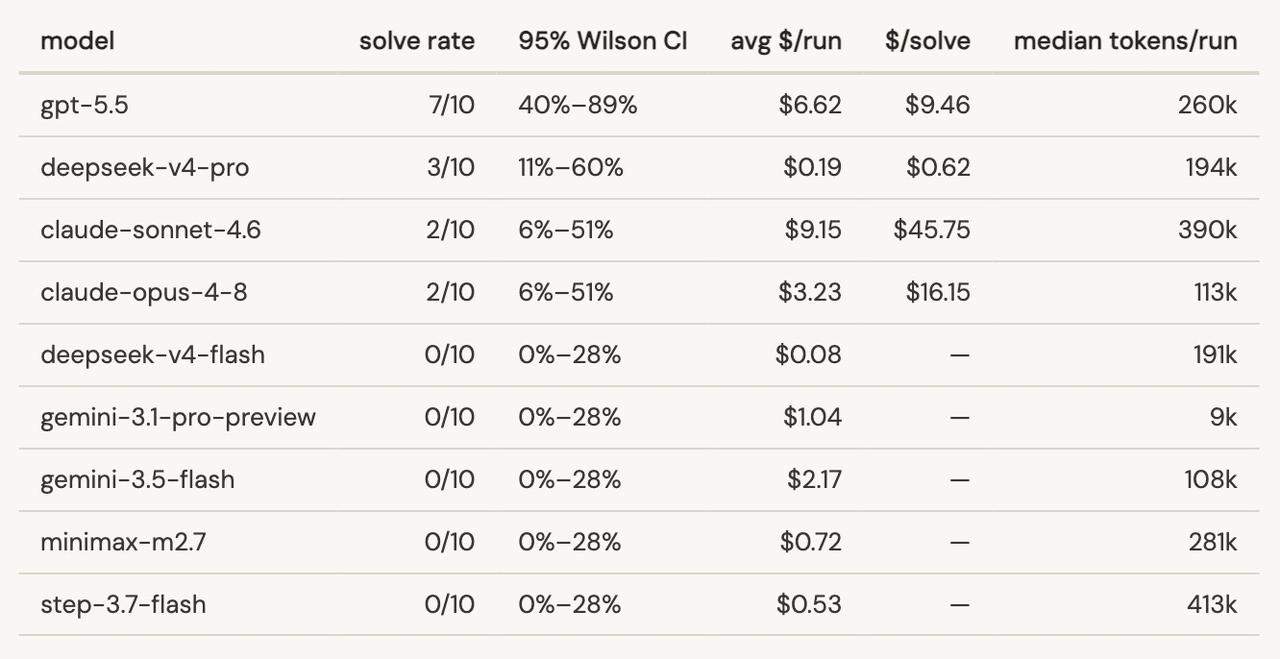
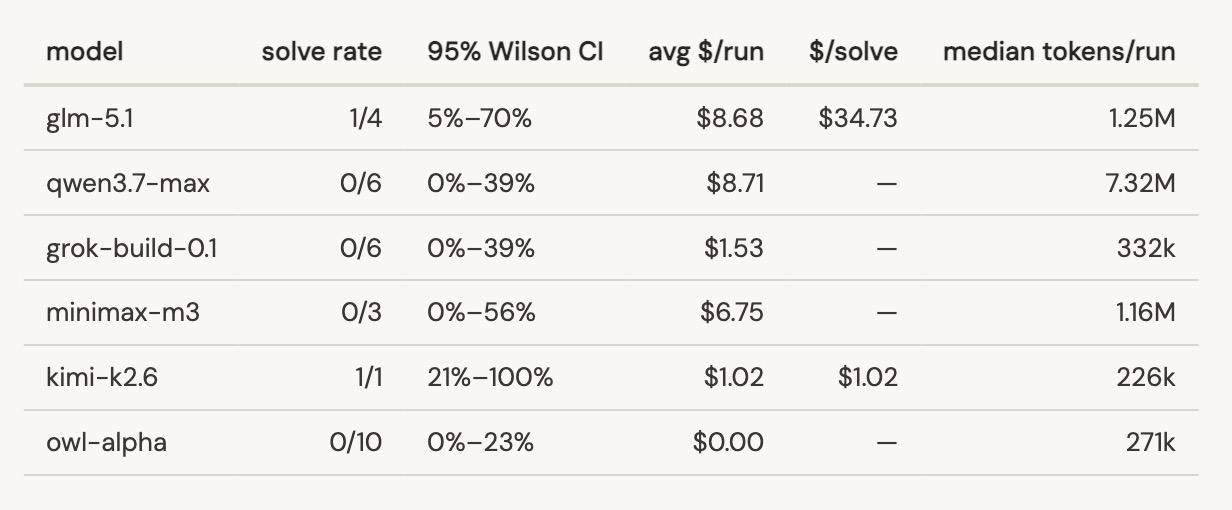
有安全专家花了1500美元做了个测试:让各家大模型去黑一个故意留有漏洞的测试App。结果很讽刺,公认聪明的Claude几乎全军覆没,不是因为它能力不行,而是它满脑子都是“安全合规”,动不动就拒绝工作。反倒是给了解锁权限的GPT-5.5和便宜的国产模型完成了任务。
这里面有个非常功利的商业逻辑:现在的“安全限制”,很可能是大厂在为未来的“付费升级”做铺垫。今天以安全为由不让你查代码、登录数据库,明天就能顺理成章地推出收费翻倍的“安全专业版”。
这种为了防官司而过度防卫的自我阉割,正在把顶级AI变成昂贵又难用的温室花朵。最糟糕的是,这种防范“防君子不防小人”。当正规开发者被AI的道德说教折磨到抓狂时,恶意攻击者早就用着毫无束缚的其他模型长驱直入了。
kasra.blog/blog/i-spent-1500-seeing-if-llms-could-hack-my-app/