CMU/MLC 团队提出了PithTrain框架,一个专门为 AI 智能体设计、端到端开源的紧凑型 MoE 训练框架。它把原本动辄几十万行的庞大系统精简到了 11,000 行左右,核心目标是让 AI 智能体可以更轻松地阅读、调试和升级模型训练代码。
🔆 论文强调四个 agent-native 设计原则:
🔸 compactness,减少代码规模和跨文件依赖,让 agent 更容易一次性建立上下文。
🔸 stay in Python,降低语言边界和编译扩展带来的调试成本。
🔸 no implicit indirection,避免大量 registry、字符串查找和动态 callable,让模型逻辑更容易从单个文件中读完。
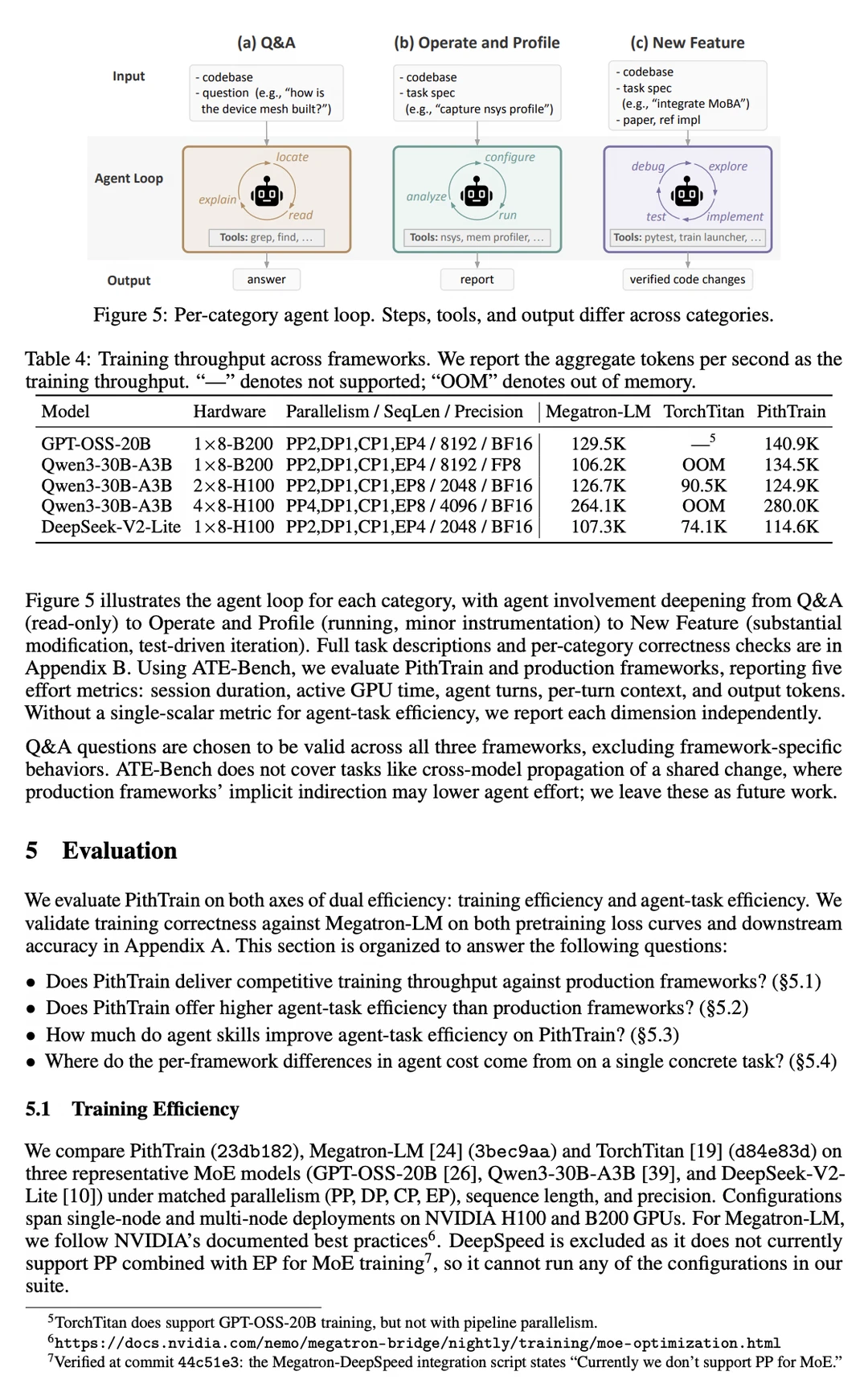
🔸 ship the agent skills,把启动训练、采集 profile、检查正确性、移植模型等常见任务写成 agent 可调用的简短流程,并用脚本返回明确 PASS/FAIL。
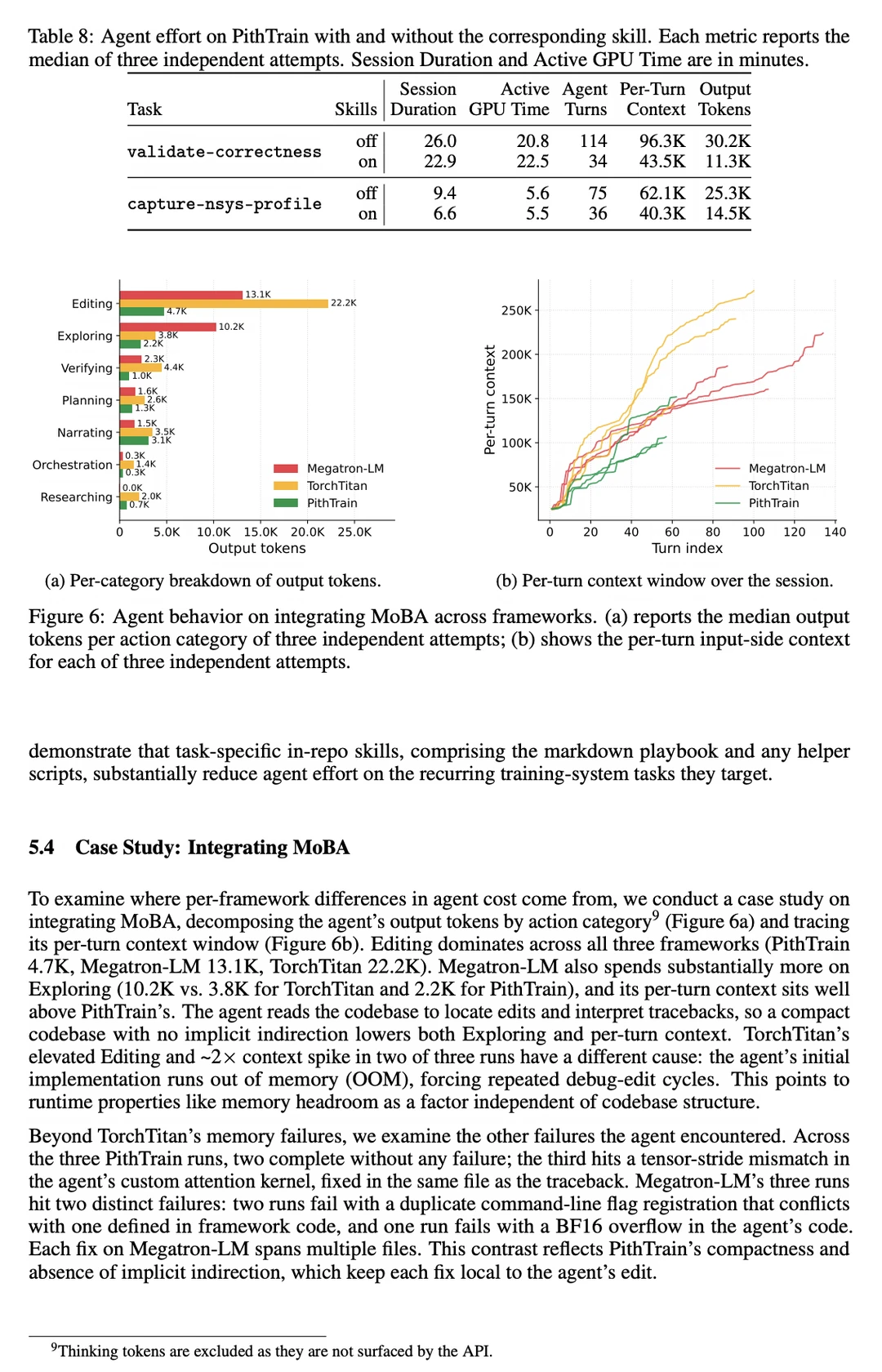
实验显示,它在多种配置下与生产框架吞吐接近,最大差距约 1.4%;在 ATE-Bench 上,同一 agent 完成理解、运行、扩展任务时,PithTrain 交互轮次减少了 62%,运行时间节省了 64%。
这篇论文的突破点在于它不再盲目追求通过增加代码复杂度和层层抽象来换取性能,而是证明了通过精简、直观的“智能体原生”设计,既可以保留最顶级的硬件吞吐性能,又能极大地释放 AI 智能体自动迭代和进化 AI 框架的潜力。