但真到企业里落地,第一关往往就很朴素,一堆合同、票据、扫描件、表格、研报,AI到底能不能“看”明白、“读”清楚。
这事听起来不如Agent性感,但在业务里很要命。
如果连原始文件都解析不准,后面的知识库、合同审核、财务自动化、政务归档,基本都没法往下走。
而扛起文档解析基础重任的,正是OCR,它正是各行各业智能化落地最关键的数据入口。
简单说,OCR就是把图片、扫描件、PDF里的文字内容,转成可编辑、可搜索、能被系统处理的数据。放到AI时代,它其实是很多业务的数据入口。
拿百度这次发的PaddleOCR-VL-1.6来说,我觉得可以看一眼。
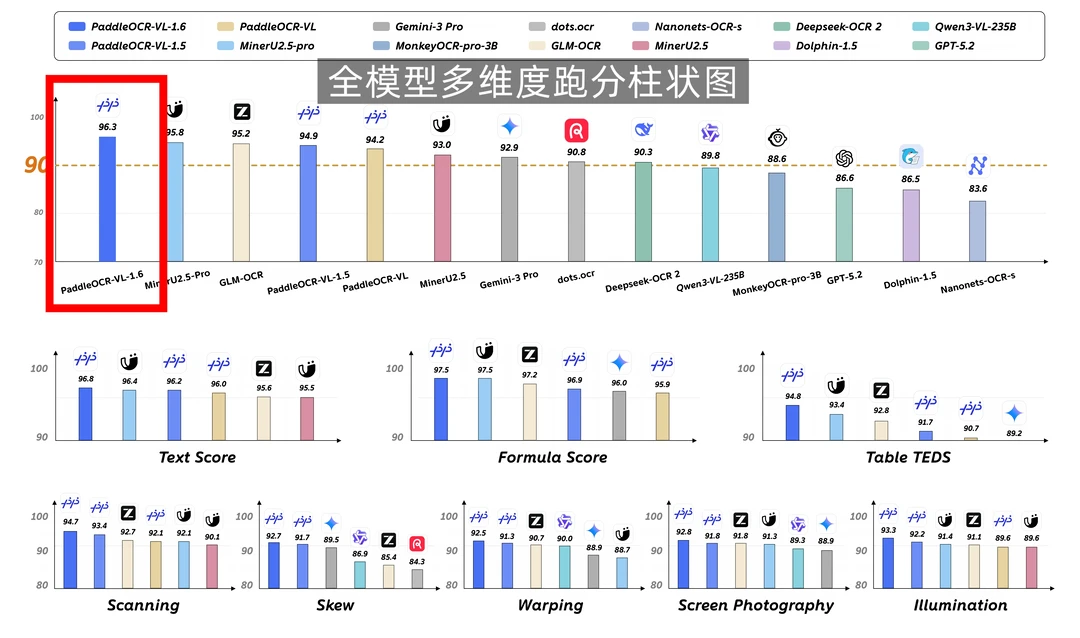
作为文心衍生模型,它这次在OmniDocBench v1.6上总成绩做到96.33%,在总体表现上比Gemini、GPT、GLM-OCR等主流模型要好。
在更贴近真实业务的Real5-OmniDocBench测试里,PaddleOCR-VL-1.6也拿到93.19%,比Gemini-3-Pro高了近4个百分点。
但比榜单更重要的,还是它处理真实复杂文件的能力。
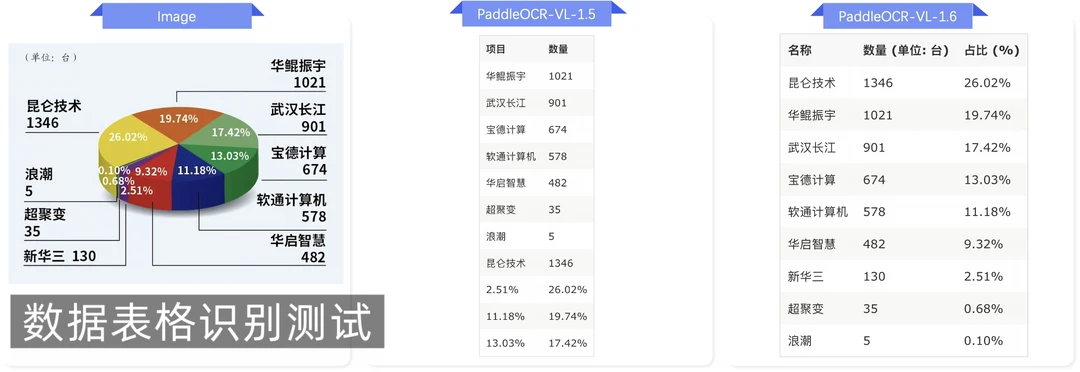
这次提升比较明显的地方,主要在文本、公式、表格这些核心识别能力上。
像表格解析、古籍文档、生僻字识别,过去都是很难啃的场景,这次的表现也有了很大的进步。
还记得之前PaddleOCR-VL-1.5的时候,GitHub Star就超过79.2K,成了全球最受开发者欢迎的开源OCR项目之一。
而这次PaddleOCR-VL-1.6的升级,使得文心能力在产业场景里持续下沉。
这种东西一旦被开发者和企业用起来,影响力可能比大家想象的大。
毕竟,大模型最终拼的,还是谁能把最复杂、最琐碎、最真实的业务问题吃下来。百度这次算是把一个很基础但很要命的入口,打到了全球第一。