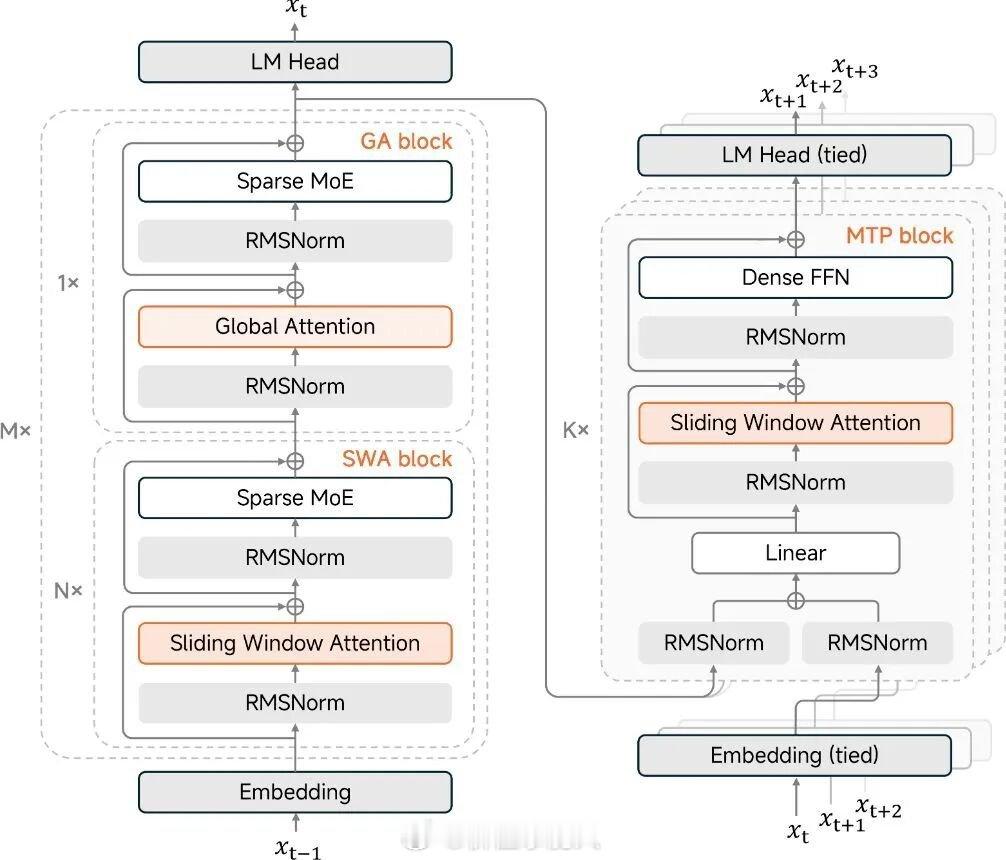
小米公开MiMo推理优化技术:API降价99%的硬核支撑5月30日,小米正式公开MiMo-V2.5系列推理全链路优化技术细节,核心围绕Hybrid SWA+MoE+多模态复合架构重构推理栈,直接支撑3天前MiMo API最高99%永久降价的壮举,模型能力无损,成本断崖式下降。一、核心架构:Hybrid SWA+MoE,从根上降本MiMo-V2.5-Pro为万亿参数MoE模型,关键架构设计直击大模型推理最大开销——KVCache(上下文缓存)。- Hybrid SWA(混合滑动窗口注意力):70层网络中,60层用局部窗口注意力(SWA),仅10层保留全局注意力;理论上将KVCache存储/计算压至Full Attention的1/7,长文本场景优势拉满。- MoE(混合专家)稀疏激活:总参数1.02万亿,推理仅激活420亿,用“小计算量保大模型能力”。二、五大工程突破,把理论优势变实际效率小米系统性重构推理全链路,解决分布式缓存不一致、前缀匹配失效等工程难题,五大核心优化:1. KVCache极致压缩:分级缓存+前缀缓存+动态管理,存储降至同级方案1/7,长序列成本大降。2. MTP(多Token预测)加速:3层MTP结构,一次前向传预测多Token,推理速度提升2-3倍,长文本理解准确率+25%。3. Prefill/Decode链路重构:优化并行调度,吞吐量提升3倍,首128Token生成速度**+2.3倍**。4. 多模态推理优化:视频处理速度近7倍(156秒→23秒),支持图文音视频高效理解。5. 调度策略精细化:适配长文本与高并发场景,硬件利用率最大化。三、性能与价值:能力不变,成本“白菜价”- 能力无损:模型写作、编码、长文档理解能力无缩水。- 成本暴跌:KVCache压缩+吞吐量提升,单用户服务成本最高降99%。- 效率飙升:相同硬件支持7倍用户,长文本、多模态场景速度显著领先。- 行业意义:业内首篇Hybrid SWA+MoE+多模态大规模工程方案,部分优化已回馈SGLang开源社区 。四、背后逻辑:大模型竞争进入“工程效率战”当模型能力趋近,推理成本与效率成核心壁垒。小米通过架构创新+全链路工程优化,实现“强能力+低成本+高效率”,不仅让MiMo API普惠,更树立行业新标杆——大模型不再是“烧钱游戏”,而是技术驱动的效率革命。