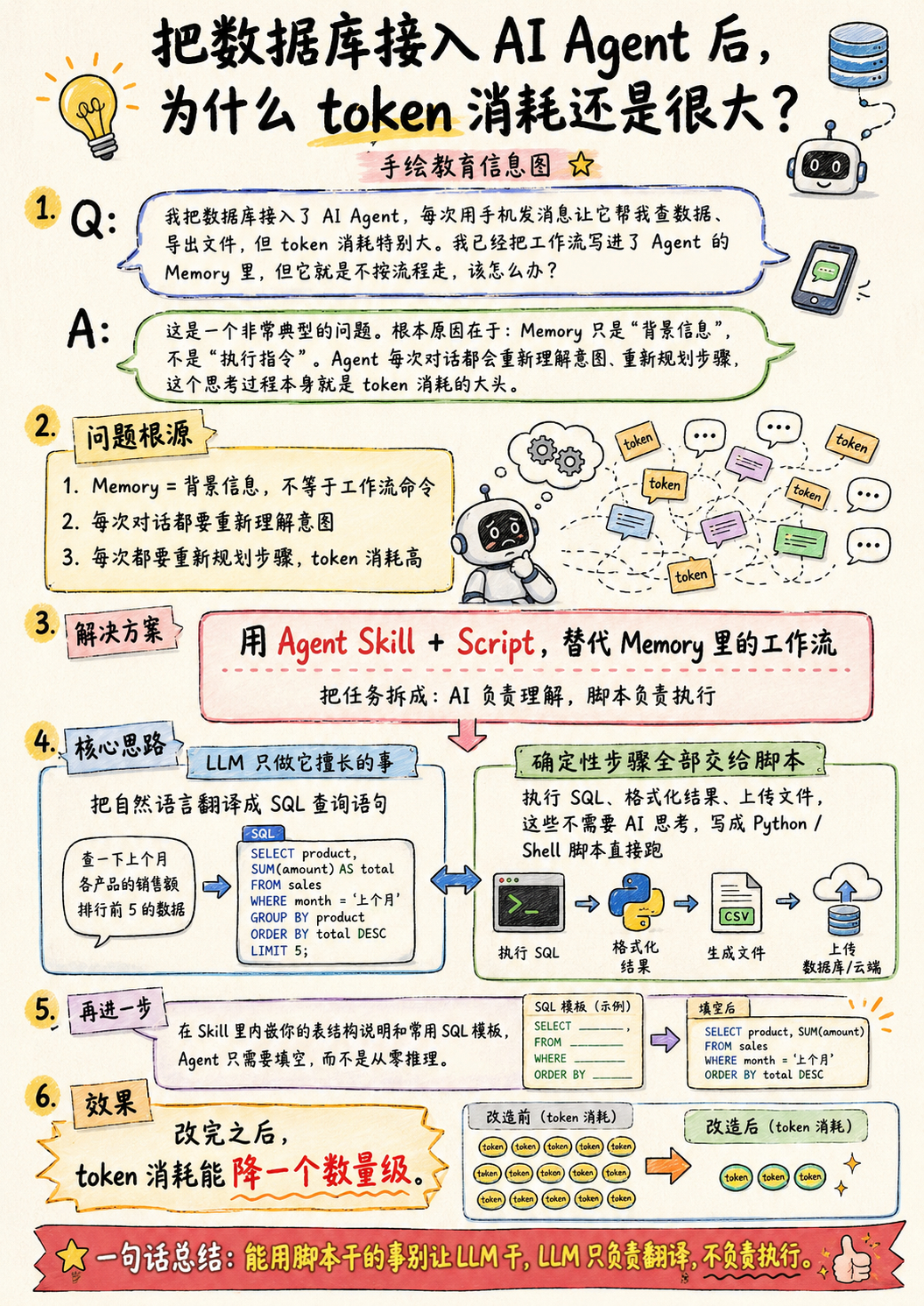
Q:我把数据库接入了 AI Agent,每次用手机发消息让它帮我查数据、导出文件,但 token 消耗特别大。我已经把工作流写进了 Agent 的 Memory 里,但它就是不按流程走,该怎么办?
A:这是一个非常典型的问题。根本原因在于:Memory 只是“背景信息”,不是“执行指令”。Agent 每次对话都会重新理解意图、重新规划步骤,这个思考过程本身就是 token 消耗的大头。
解决方案:用 Agent Skill + Script 替代 Memory 里的工作流。
核心思路是把任务拆成两部分:- LLM 只做它擅长的事——把自然语言翻译成 SQL 查询语句- 确定性的步骤全部用脚本——执行 SQL、格式化结果、上传文件,这些不需要 AI 思考,写成 Python/Shell 脚本直接跑
再进一步,在 Skill 里内嵌你的表结构说明和常用 SQL 模板,Agent 只需要填空而不是从零推理。
改完之后 token 消耗能降一个数量级。
一句话总结:能用脚本干的事别让 LLM 干,LLM 只负责翻译,不负责执行。