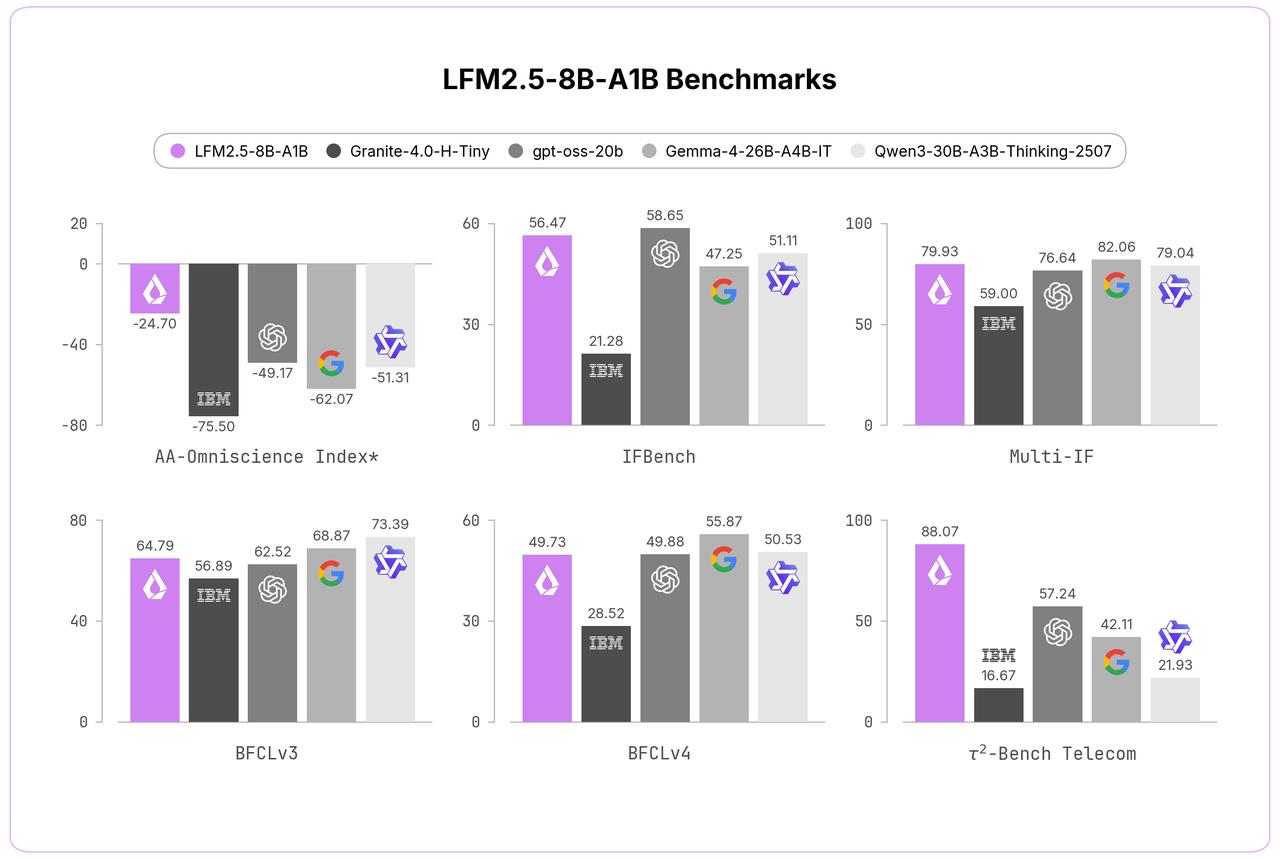
Liquid AI发布了LFM2.5-8B-A1B,这是一个MoE小型大模型,总参数8.3B,但推理时仅激活约1.5B参数,支持128K上下文长度,在消费级硬件(如手机、平板、笔记本)上即可实现高效的推理、工具调用等能力。
相比早期LFM2-8B-A1B版本,LFM2.5迭代带来了显著提升:预训练 token 从约12T扩展到38T,上下文窗口扩展至128K,词汇表翻倍(更好支持多语言),并通过大规模强化学习强化了工具调用和代理能力。它在基准测试中展现出超越同规模稠密模型的表现,甚至在某些场景下接近Gemma 2-9B等更大模型,同时在Apple M系列等消费级CPU上能达到极高tokens/s速度(如253 t/s)。