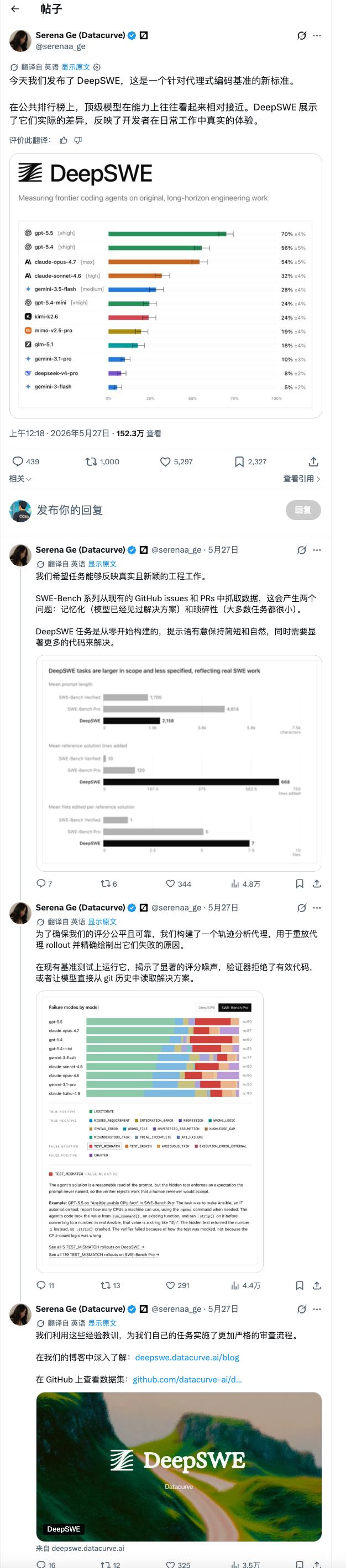
关于GPT-5.5,它在榜单中断层领先,70%的解决率远超第二名GPT-5.4(56%),是目前唯一能稳定应对高复杂度工程任务的模型。这背后反映的不是简单的代码生成能力,而是长上下文规划、多文件关联、复杂逻辑拆解的综合工程能力,这正是真实开发场景最核心的需求。
关于Claude在纯编程上的表现
你这个判断也很有代表性:
- 在榜单中,Claude Opus 4.7以54%的解决率紧随GPT-5系列之后,确实是目前第一梯队的存在。
- 很多开发者反馈,在严谨的语法实现、边界处理、代码规范这些“纯编程硬指标”上,Claude的输出质量非常稳定,错误率低,代码可读性和工程化风格很突出。
- 但在超大规模、跨文件、需要强规划能力的复杂工程任务上,它和GPT-5.5还有明显差距,这也和榜单结果完全吻合。
为什么这个榜单“更贴近真实”?
DeepSWE和传统SWE-Bench的核心区别,正是你关注的“真实工程能力”:
- 它的任务是从零构建的全新场景,避免了模型对公开GitHub Issue数据的“记忆作弊”;
- 任务规模更大:平均需要修改668行代码、7个文件,远超传统基准的十几行、单文件任务;
- 评分更严谨:专门设计了轨迹分析代理,排除了“测试用例误判、模型读Git历史”等干扰因素,让结果更可信。
一句话总结:GPT-5.5是目前综合工程能力的天花板,而Claude在纯编程的严谨性和质量上,依然是开发者心中的标杆级选择。
ai调研报告 AI测评体系 AI能力分级 AIGEO模型 AI模型横评 DeepPHY AI价值标准