今天,看到智谱新发了一篇技术blog,推荐搞AI Infra的朋友们可以去看看原文,方向上很有前瞻性。
博客里提到,他们在GLM-5.1线上推理集群里,完成了新一代网络架构ZCube的落地。
在GPU、服务器和应用代码一行没动的情况下,集群整体推理吞吐提升了15%,首Token响应的尾延迟降了40.6%。
15%真很夸张了……因为对于一个服务上百万开发者的大模型API平台来说,同样的硬件投入,每秒能多响应15%的用户请求。放到万卡集群的规模下,光是省下来的网络硬件成本就在2.1亿到6.4亿元之间。
你可能会好奇,GPU没动,性能是从哪来的?答案是:网络。
1你可以把一个大规模推理集群想象成一个超级大的快递分拣中心,几千上万张GPU就是分拣员,每个人手速都很快。
但分拣员之间需要不停地传递包裹,比如这边处理了一半的数据要传给那边继续处理。传递包裹靠的就是中间那套传送带系统,也就是网络。
然而,当分拣员越来越多,传送带还是老设计,几千个人同时往中间扔包裹,传送带就堵了。这时候,你再加人也没用,因为瓶颈不在人,在传送带。
这就是今天大模型推理集群面临的真实困境。过去几年AI基础设施的竞赛,大家的注意力几乎全在GPU上,谁家卡多谁就牛。
但当集群规模扩展到千卡、万卡级别之后,一个问题开始浮出水面:每处理一次用户请求,集群内部需要持续、高频地互相传递大量中间数据。
网络的效率上限,直接决定了这些GPU到底能发挥出多少真实算力。
智谱自己的实测数据也印证了这一点:同等GPU配置下,仅仅把网络带宽从200Gbps提升到400Gbps,推理总吞吐就能提升约10%,首响时延下降19%。
而且,这个规律随着集群规模扩大会越来越明显。很多公司花大价钱买来的GPU,可能有相当一部分算力是被网络瓶颈白白浪费掉的。
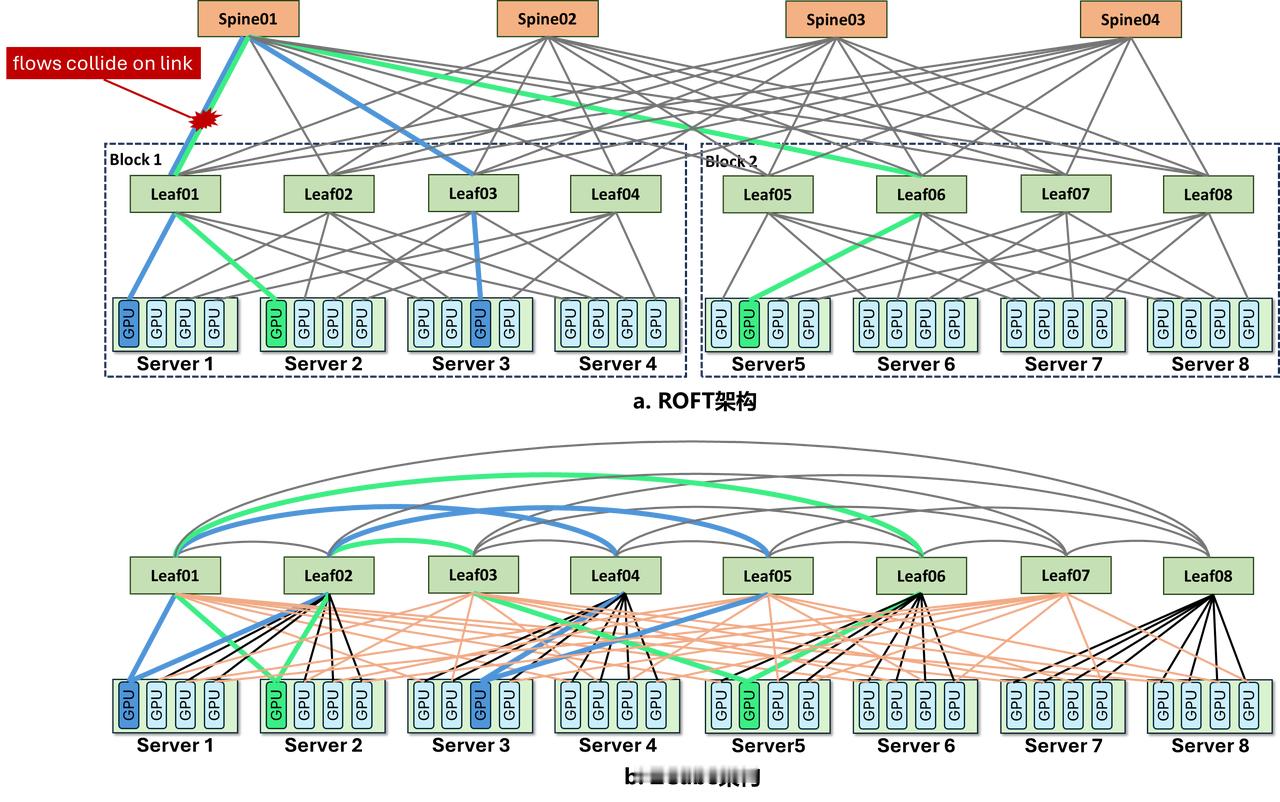
2问题的根源到底在哪?这就要说到一个用了二十多年的东西:Fat-Tree / Clos架构。
我简单解释一下。传统数据中心组网就像修公路,用的是分层堆叠的方式。最底层是GPU直连的小路,往上一层是汇聚的大路,再往上是核心的高速公路。数据要从一张GPU传到另一张,得先上高速再下高速,中间经过好几层交换机。
这套架构在互联网时代运行得很好,是因为那时候的流量模式比较均匀,大家都在刷网页、看视频,数据流向相对稳定。在AI训练阶段也基本够用,因为训练的通信模式比较规则。
但大模型推理带来了一种完全不同的流量模式。随着Prefill和Decode分离部署成为主流,集群内部的数据传输变得高度动态且不对称。不同用户的请求长短不一,处理时间有快有慢,数据在GPU之间的流向像水一样随机波动。
传统的分层架构面对这种流量时,会出现一个靠调参解决不了的结构性问题:流量会被拓扑关系天然地推向同几台交换机、同几条链路,形成热点堆积和链路拥塞。
还是用刚才快递中心的比喻。以前大家寄的包裹大小差不多、目的地也比较集中,传送带设计成几层中转就够了。但现在每个包裹大小不一样,目的地随机分布,而且每秒都在变化。
所有包裹还是得经过中间那几个大型中转站,中转站就成了瓶颈。你把传送带加宽也没用,因为问题出在路线设计上。
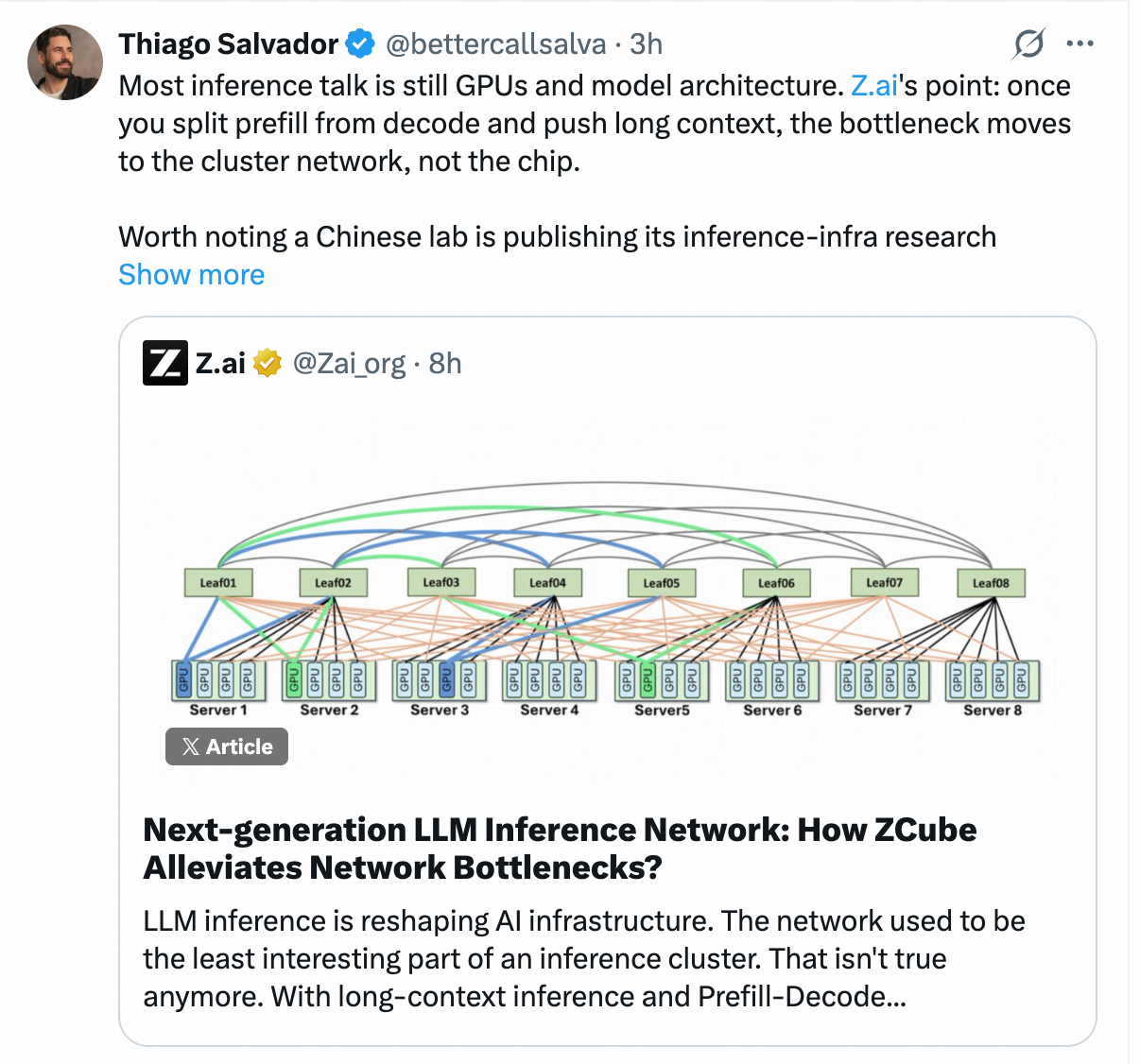
3智谱这次做的ZCube,做的事情是重新设计了这套路线。
ZCube最大的突破,在于推翻了沿用二十多年的Clos分层堆叠组网逻辑,改成了完全扁平化的GPU互联方式。通过一种叫做单轨加多轨混合接入的拓扑设计,确保全网任意两张GPU之间有且仅有一条最优路径。
不需要绕路,不需要层层中转,从架构层面实现了全网交换机的理想负载均衡。
同理,如果每个包裹从起点到终点只有一条最优路线,而且这些路线天然分散在不同的通道上,就不会有几千个包裹同时挤在一个中转站的问题了。
拥塞不是靠更好的调度算法消除的,而是从根上就不让它产生。
这个架构上的思路转变,才是ZCube真正的突破点。
落地效果也很直观。在千卡级GLM-5.1线上推理集群中,ZCube和传统ROFT架构做了对比测试。GPU型号、软件栈、业务代码全部保持不变,只换网络架构。
结果:交换机和光模块硬件成本减少了33%,GPU平均推理吞吐提升15%,TTFT P99降低40.6%。
省了三分之一的网络硬件钱,性能还更好了,这在基础设施领域是很少见的,因为通常降本和提效是两个互相矛盾的目标。
值得一提的是,这项技术还发表在了网络领域的顶级学术会议ACM SIGCOMM 2025上,评审给出的评价是:这项工作显著改变了整个行业对网络的认知方式。
4比较有意思的是,几乎在同一时间,OpenAI联合NVIDIA、AMD、Intel、Microsoft、Broadcom五大巨头,发布了一个叫MRC的新型网络传输协议,并且已经部署在他们最大规模的超算集群中。
这两个技术其实解决的是同一个问题,但切入角度不同。MRC在协议层发力,通过多路径并发传输来对抗网络拥塞;ZCube则在架构层动手,从拓扑设计上直接消除拥塞产生的根源。
对于正在大规模建设AI基础设施的云厂商、模型公司和智算中心来说,这可能意味着组网方案的采购逻辑将发生结构性变化。
高端交换机的需求会向更少层级、更大端口密度的方向演进,光模块的需求会向更高速率集中。800G光模块、高密度以太网交换机这些细分赛道,可能会迎来新一轮需求释放。