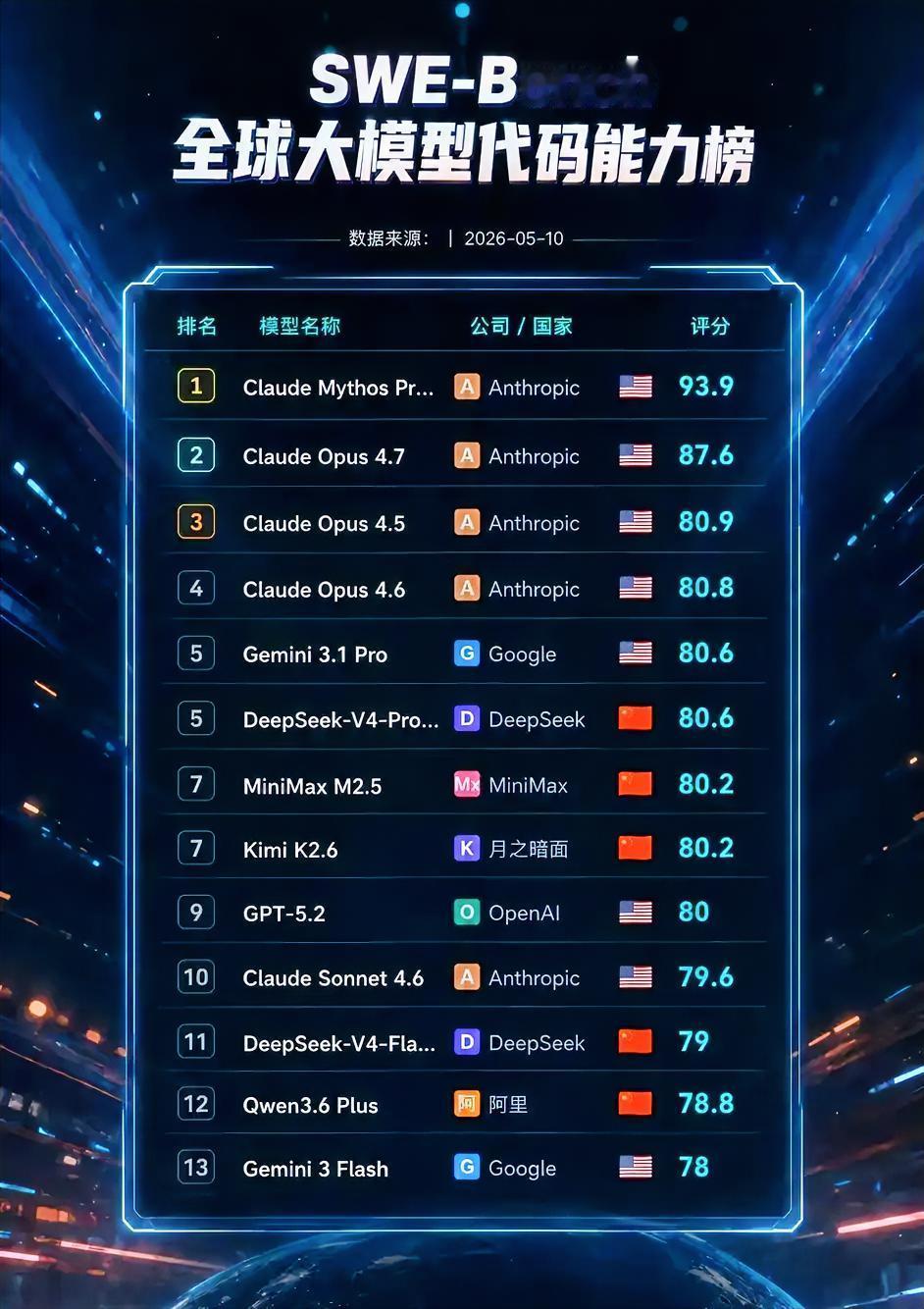
SWE-Bench 2026.5 全球大模型代码能力榜解读
这份榜单基于SWE-Bench(代码工程能力权威基准),聚焦真实场景下的代码修复、工程开发能力,直观展现了全球模型的编程实力格局。
一、整体格局:Claude 霸榜,国产模型跻身第一梯队
1. Anthropic 占据绝对统治地位:前4名全部被Claude系列包揽,其中Claude Mythos Preview以93.9分断层领跑,是当前代码能力最强的模型,后续Opus系列版本也保持高分,证明其在复杂工程、长代码上下文场景的核心优势。
2. 国产模型集体崛起:DeepSeek V4 Pro、MiniMax M2.5、Kimi K2.6、Qwen3.6 Plus全部上榜,其中DeepSeek V4 Pro与Gemini 3.1 Pro同分(80.6分),追平Google旗舰,和GPT-5.2处于同一水平线,正式跻身全球代码第一梯队。
3. OpenAI 表现不及预期:GPT-5.2仅以80分排在第9位,落后于多款Claude、国产与Google模型,说明在真实工程代码场景,OpenAI的优势已被大幅缩小。
二、梯队分层(按分数划分)
第一梯队(代码天花板,≥90分)
- Claude Mythos Preview(93.9分):代码能力断层第一,擅长超长工程、复杂系统重构、疑难Bug修复,是专业后端/全栈开发首选。
第二梯队(顶级工程能力,80~90分)
- Claude Opus 全系列(4.5/4.6/4.7):稳定的专业级编程能力,适配大型项目、多文件协同开发。
- Gemini 3.1 Pro、DeepSeek V4 Pro(80.6分):国产DeepSeek追平Google旗舰,在中文开发、国内生态适配、代码调试上更具优势。
- MiniMax M2.5、Kimi K2.6(80.2分):两款国产模型表现亮眼,Kimi依托超长上下文,在长代码库分析场景优势突出。
- GPT-5.2(80分):通用编程表现优秀,但在复杂工程场景已无领先优势。
第三梯队(实用开发能力,78~80分)
- Claude Sonnet 4.6、DeepSeek V4 Flash、Qwen3.6 Plus、Gemini 3 Flash,适合日常开发、中小型项目,性价比更高。
三、选型核心结论
- 做大型工程、系统重构、疑难Bug排查:优先选 Claude Mythos / Opus 系列,代码深度和稳定性无可替代。
- 做国内项目、中文开发、性价比优先:优先选 DeepSeek V4 Pro,代码能力对标Gemini,成本更低、适配性更强。
- 做长代码库分析、多文件项目:Kimi K2.6 凭借超长上下文,是国产最优解之一。
- 日常快速开发、轻量任务:GPT-5.2、Gemini 3 Flash、DeepSeek V4 Flash 都足够胜任。
一句话总结:Claude 守住代码王座,国产DeepSeek、MiniMax、Kimi全面追平国际头部,OpenAI在真实工程场景优势不再明显。
开源模型测评 AI模型排行榜 ai代码索引 代码评测 大模型代码 代码测试报告 代码生成测试