这份关于Agentic Performance(τ-Voice)的图表,展示了全双工语音模型在客服场景下的当前水平。
虽然 Grok 的表现令人印象深刻,但最高分仅为 52.1% 这一事实表明,“AI Agent”在完全掌握人类级别客服复杂性之前,还有很长的路要走。
PS:基准来源基于τ-Voice(Tau-Voice)基准测试,该测试包含零售、航空、电信等行业的 278 个接地化(grounded)客服任务,模拟真实通话环境(包括噪音、口音、中断、自由对话切换等)。科技AI智能体
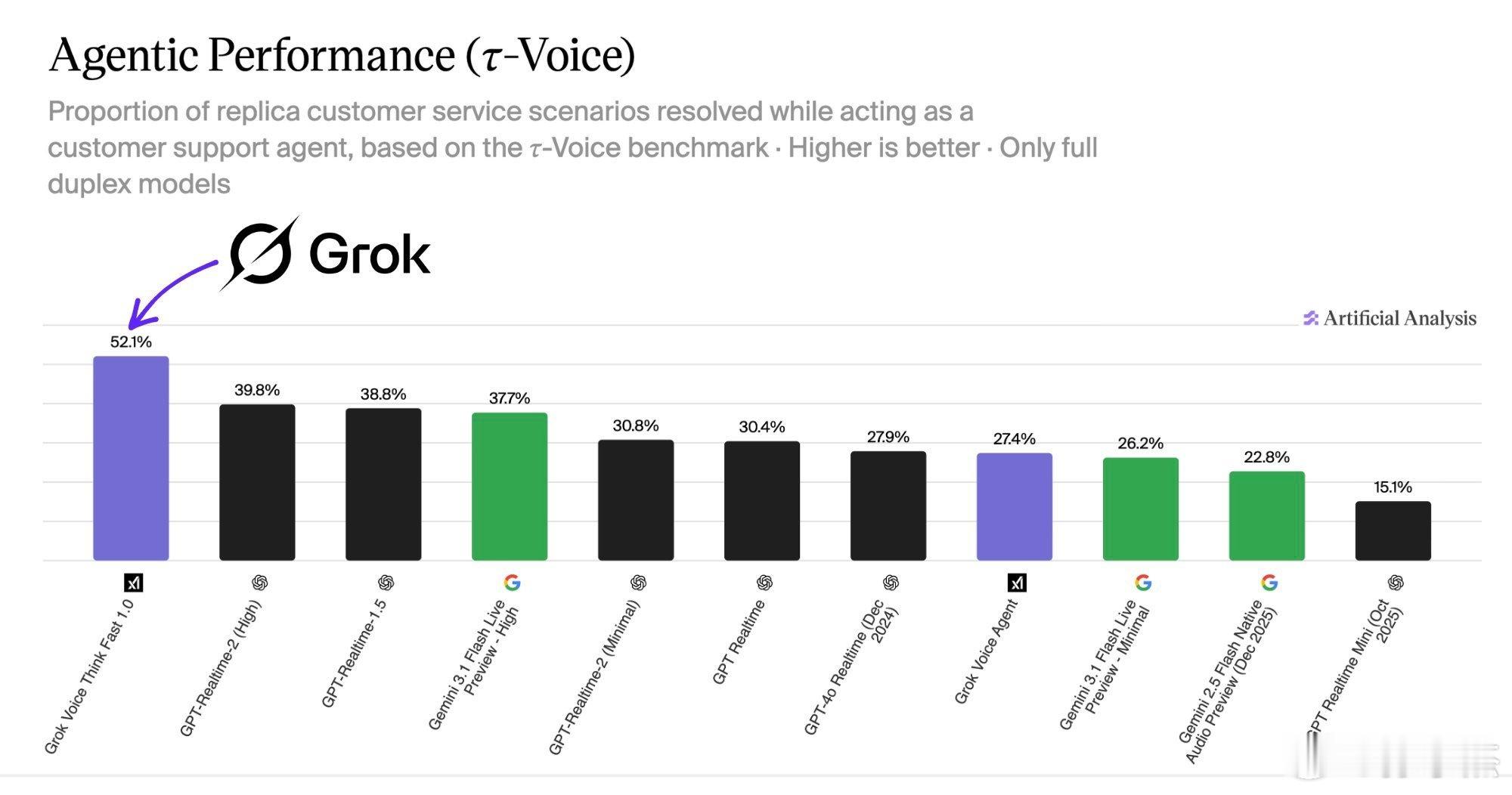
这份关于Agentic Performance(τ-Voice)的图表,展示了全双工语音模型在客服场景下的当前水平。
虽然 Grok 的表现令人印象深刻,但最高分仅为 52.1% 这一事实表明,“AI Agent”在完全掌握人类级别客服复杂性之前,还有很长的路要走。
PS:基准来源基于τ-Voice(Tau-Voice)基准测试,该测试包含零售、航空、电信等行业的 278 个接地化(grounded)客服任务,模拟真实通话环境(包括噪音、口音、中断、自由对话切换等)。科技AI智能体