这两天,看到千问C端应用团队的四篇论文,两篇中了ICML 2026,两篇中了ACL 2026。
给不熟悉的朋友们介绍一下,ICML是机器学习领域最老牌的顶会,今年投稿量直接翻倍到了23918篇,卷得前所未有。
而ACL是NLP方向公认最权威的会议,今年也收到了12000多篇投稿,主会录取率只有19%。
能在这种竞争烈度下同时中稿,是真的有点东西的。
所以我很好奇,为什么这4篇论文能被选中,他们到底解决了AI领域的哪些问题?
带着这个疑问,我把四篇论文翻了一遍。
最直观的感受是,千问C端应用团队做研究的方式,和很多纯学术团队,不太一样。
他们每篇论文的出发点,都是从实际应用的角度出发,解决AI落地的真问题。很推荐大家有时间,可以把原文下载下来看一下。
1其中我印象最深的一篇论文叫ECHO: Elastic Speculative Decoding with Sparse Gating for High-Concurrency Scenarios,这篇论文还拿到了ICML Spotlight。
在两万多篇投稿里,只有536篇拿到这个标签,占比2.2%,几乎等同是评审委员会拍着桌子说「这篇必须让所有人看到」的级别了。
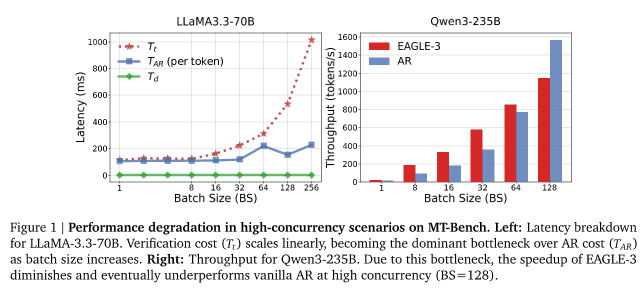
ECHO解决的最核心的问题是:为什么大模型一到高峰期就卡?比如,白天人少的时候模型回复飞快,但一到晚高峰就开始卡,有时候等个回复要好几秒。
这背后的技术原因,和投机解码(Speculative Decoding)这个方向有关。就是让一个小模型先快速猜出后面好几个词,然后大模型一次性验证,猜对的就省了,猜错的再纠正。
理想情况下,推理速度能快不少。
这个方法在实验室里确实效果很好,可一旦放到真实的高并发生产环境里,经常会翻车。
因为当几百上千个请求同时涌进来,GPU的算力是有上限的。这时候你还给每个请求都生成一大堆候选词让大模型挨个验证,算力瞬间就打满了。
投机解码不但没加速,反而会因为验证计算的开销拖慢整体速度。
这也就是为什么,投机解码在生产环境里一直没能大规模铺开。
但ECHO跳出了过去的思路,把投机采样从一个算法技巧,升级成了一个资源调度问题。
他们是怎么做的呢?
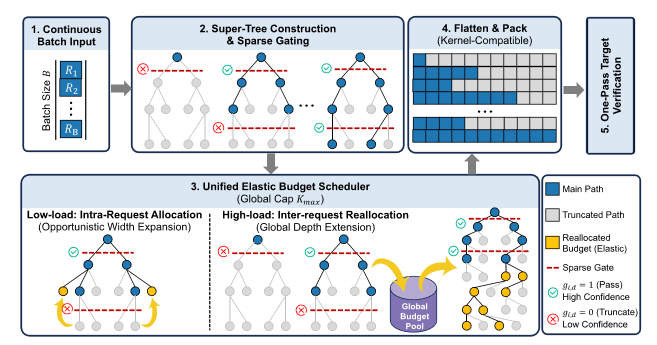
第一步,找甜点区。
模型判断一个词该不该接受的能力,在树的不同深度上并不均匀,有几个关键节点特别准,其他位置反而容易误判。所以ECHO只在这些关键节点做决策,减少噪声。
第二步,弹性预算调度。
ECHO把整个Batch里所有请求的候选词,当作一棵统一的超级树来管理,设定全局验证预算上限。
某个请求的模型置信度高,预算就往深度上倾斜,让它多猜几步,一次验证搞定更多token。某个请求的置信度低,预算就往宽度上倾斜,多给几个候选词提高命中率。
高并发的时候,那些被截断的请求甚至会把省下来的预算让渡给更有潜力的请求。
最终结果是,在Qwen3-235B这样的工业级大模型上,ECHO的端到端吞吐量比当前最优方法最高提升了36%,实际墙钟时间加速达到5.35倍。
换句话说,同样的算力,能同时服务更多的人,每个人等得更短。
对任何做大模型C端产品的团队来说,都是实打实的降本增效。
2
另一篇叫MARCH,入选了ACL主会。
MARCH解决的核心问题是:为什么大模型总是一本正经地胡说八道?
幻觉,其实也是大模型的老问题了。
之前行业内试了很多办法,比如通过RAG,让模型检索文档再回答。
但问题是,模型在验证自己答案的时候,容易掉进一个循环——我已经生成了这个答案,检查的时候也会下意识地往答案上靠,把错误的信息验证成了合理的,造成自证偏差。
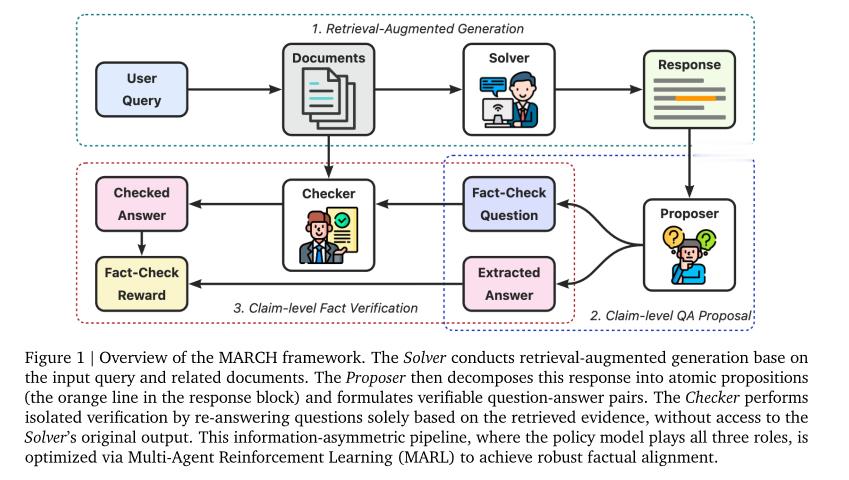
针对这个问题,MARCH框架的解法是:刻意制造信息不对称。
它把任务拆成三个角色来完成。
-Solver负责生成初始答案。
-Proposer负责把这个回答拆解成一条条可以独立验证的原子命题,变成问答的形式。
-Checker则在完全看不到Solver原始答案的情况下,只根据参考文档独立回答这十个小问题。
这个设计的精妙之处在于:Checker根本不知道Solver说了什么,它只能靠文档说话,没有任何被原始答案带偏的可能。
然后是强化学习阶段:只要Solver的某一个断言和Checker的独立判断不一致,这条路径的所有奖励都扣掉。一票否决,没有例外。
这种极端严苛的约束,强迫模型在训练时真正内化查证逻辑。
最终,一个只有8B参数的模型,在事实准确性上能跟闭源大模型掰手腕。
3
另外两篇论文我简单提一下。
SiameseNorm解决的是Transformer底层架构里的一个老矛盾:训练稳定的结构表达力不够强,表达力强的结构容易训练崩溃。
它用双流并行设计让两条路各司其职,一条稳梯度,一条提表达力。实验里,算术和顺序推理准确率提升了将近41%。
RiT解决的是另一个痛点:大模型在推理开放性任务时,思维过程容易乱飘,字数失控,或者陷入循环。RiT把细粒度的评分量表引入强化学习的中间思考环节,让模型的推理轨迹有章可循,而不是在黑盒里随意发散。
这两篇虽然一个是底层架构,一个是思维过程,但目标是一致的:把模型能力从理论上限往实际可用的方向拉。
4很多人可能会想,一个做C端应用的团队,为什么会去研究这些东西?
其实不管是高并发卡顿还是幻觉问题,都是做C端产品的团队经常要面临的用户投诉问题,都是从真实的应用痛点出发的。
背后更大的趋势是:AI行业的竞争正在从参数规模的军备竞赛,转向算法深度和工程实效的比拼。
四篇论文的代码也会陆续开源,相关技术会进一步沉淀到行业里。
另外听说千问C端应用技术团队目前还在大力招人,有兴趣的朋友们可以关注一下。
从这几篇论文的质量和选题方向来看,这个团队既在做前沿研究,又有足够大的真实场景来验证想法。如果你是做AI的,而且希望自己的研究成果不只是停留在论文里,确实可以看看机会。