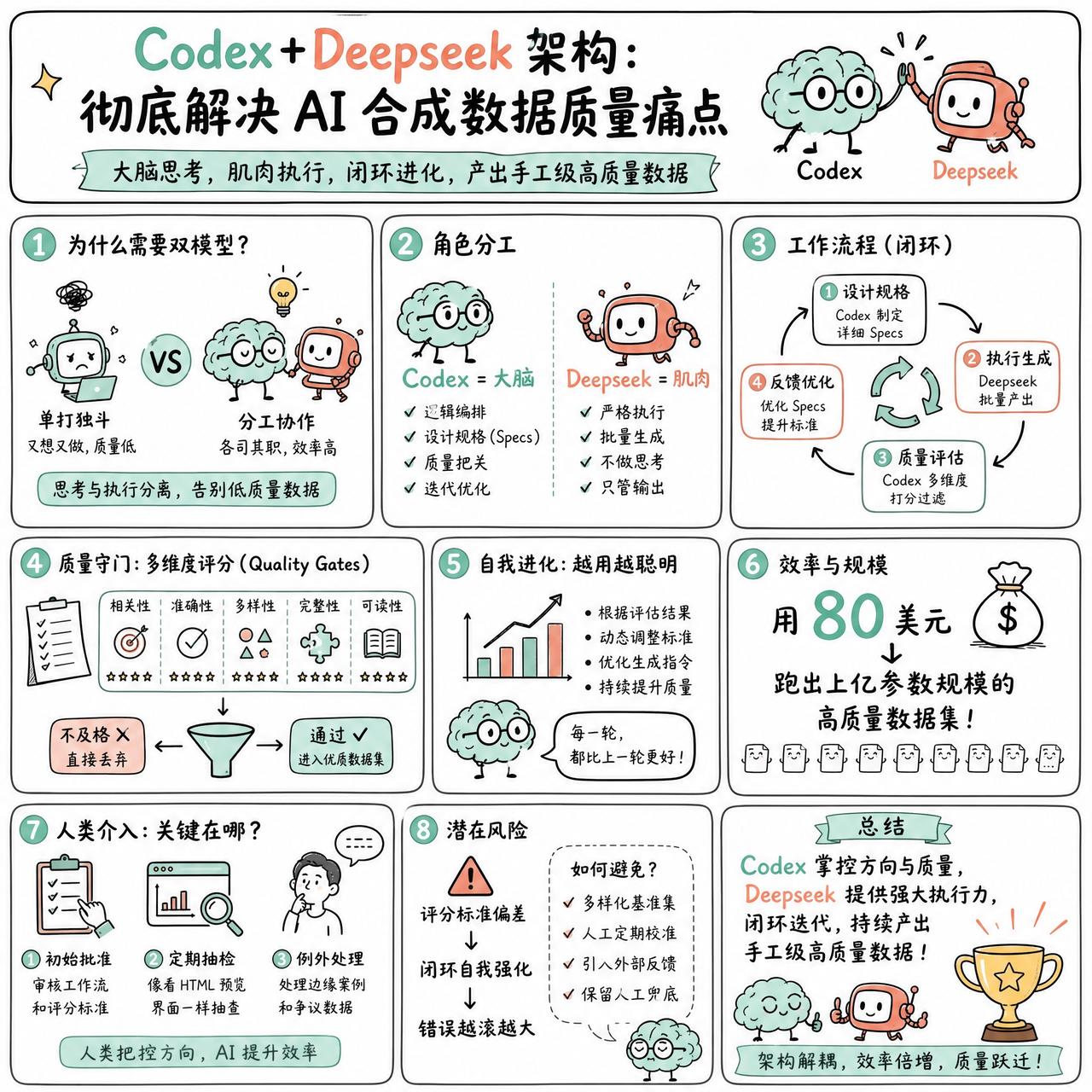
【Codex+Deepseek架构:彻底解决AI合成数据质量痛点】
快速阅读:通过将 Codex 作为“大脑”负责逻辑编排,Deepseek 作为“肌肉”负责执行生成,可以实现一种近乎自动化的“手工级”数据生产。这种架构通过闭环的质量过滤机制,解决了传统合成数据质量低下的难题。
很多人在做 Fine-tuning 时会陷入一个误区:试图用简单的 Python 脚本去改写数据,或者让一个模型既当裁判又当运动员。结果往往是得到了一堆看起来很像样、实则毫无灵魂的低质量数据,模型学到的全是噪音。
有效的做法是把“思考”和“执行”彻底拆开。
把 Codex 当成大脑,让它去设计一套极其严苛的规格说明书(Specs),甚至直接构建一套工作流。然后把 Deepseek 当成肌肉,它不需要思考,只需要严格按照大脑给出的指令去批量执行。这种拆分让生成过程从“随机发挥”变成了“精密制造”。
更有意思的是那个反馈环。Codex 不仅下达指令,还负责守门。每一批数据出来后,它都要通过预设的 Quality Gates 进行多维度打分,不及格的直接扔掉。随着循环进行,大脑会根据过滤结果不断优化给肌肉的指令,这种自我迭代让整个流水线越来越聪明。
有网友提到,这种双模型架构非常被低估,很多团队因为让单一模型承担过多角色,导致性能很快遇到瓶颈。也有人指出,这种“手工感”的本质在于那套评分准则(Rubric),如果准则本身很烂,所谓的“手工级”也不过是精修过的废话。
用 80 美元就能跑出上亿参数规模的高质量数据集,这种效率的提升来自于架构的解耦。
现在的关键问题是,当这种自动化流水线跑起来后,人类介入的边界在哪里?是只在最初批准工作流,还是需要像看 HTML 预览界面那样定期抽检?
如果连评分标准本身也开始产生偏差,这个闭环会不会变成一个自我强化的错误循环?
x.com/cjzafir/status/2054581194654986526