高盛DeepSeek V4研报解读:国产算力“量子跃迁”,暗线掘金正当时
核心结论:模型层军备竞赛,利好底层“算力军工厂”。DeepSeek V4实现性能跃升+成本腰斩+国产算力原生适配,推动国产AI产业链完成从“可用”到“好用”的质变,算力、存储、液冷、高端芯片等上游环节迎来确定性增量,暗线机会集中在算力基建、国产芯片适配、长周期AI应用三大方向。
一、高盛研报核心观点(四大主线)
1. 业务专注:DeepSeek聚焦基础文本模型,深耕长上下文与Agent能力,避开多模态“军备内卷”,商业化路径更清晰。
2. 体验提升:V4支持100万token超长上下文,性能比肩海外顶尖闭源模型;引入CSA/HCA混合注意力、mHC稳定机制、Muon优化器,长文本任务稳定性与推理效率显著提升。
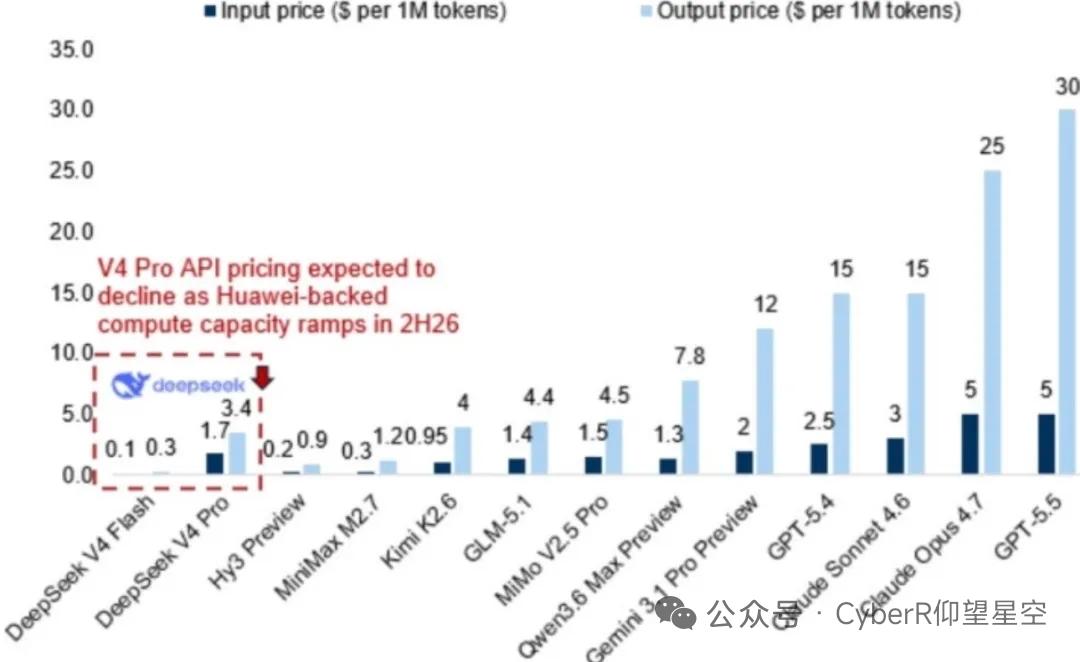
3. 成本下降:KV缓存占用仅为V3的7%-10%,单token推理FLOPs降至V3.2的27%(Pro)/10%(Flash),推理成本大幅降低,AI应用规模化落地拐点已至。
4. 国产适配:原生兼容华为昇腾950,2026年下半年芯片量产后,V4 Pro API定价将显著下调,国产大模型+国产算力闭环成型。
高盛关键判断:模型层竞争终局是上游算力与基础设施的胜利,类似北美四大云厂商逻辑——卖铲子的比挖矿的更稳,算力、存储、液冷等底层环节优先受益。
二、DeepSeek V4核心技术突破(量子跃迁本质)
- 双版本架构:
- Pro(旗舰):1.6万亿参数(激活490亿),主打极致性能。
- Flash(轻量):2840亿参数(激活130亿),平衡性能与成本。
- 三大技术革命:
1. Engram外置知识导引:静态知识查表,释放算力专注推理,长流程Agent“不失忆”。
2. mHC网络骨架重塑:深层网络信息传递更稳定,长链路任务不跑偏。
3. Muon优化器:万亿参数训练效率提升2倍,解决训练不稳定难题。
- 国产算力深度绑定:从CUDA全面转向华为CANN框架,昇腾950上单卡推理性能达英伟达H20的2.87倍,能耗降40%,国产算力替代加速。
三、产业影响:从模型内卷到算力为王
1. AI应用规模化:成本下探+上下文拉长,长周期Agent、企业级知识管理、研发协助、运维自动化等场景从试点走向量产,需求爆发在即。
2. 国产算力生态闭环:DeepSeek、Kimi等头部模型全面适配昇腾、寒武纪、壁仞等国产芯片,倒逼算力基础设施国产化,摆脱海外算力依赖。
3. 算力需求“量价齐升”:单价下降触发“杰文斯悖论”,用量增长对冲单价下滑,云计算、数据中心、GPU/AI芯片、液冷、高速互联等环节景气度持续上行。
四、暗线掘金:三大方向+核心受益标的
(一)算力基建(最确定主线)
- 核心逻辑:模型效率提升→应用爆发→算力需求扩容,国产算力替代加速。
- 受益标的:
- 华为昇腾:算力芯片+服务器+CANN生态核心受益者。
- 中科曙光:国产算力服务器龙头,深度绑定昇腾,液冷技术领先。
- 浪潮信息:服务器出货量国内第一,AI服务器占比持续提升。
- 英维克/高澜股份:液冷系统核心供应商,匹配高密度算力散热需求。
(二)国产芯片适配(暗线核心)
- 核心逻辑:大模型原生适配国产芯片,芯片厂商+模型企业深度绑定,生态壁垒构建。
- 受益标的:
- 寒武纪:思元590适配大模型,推理性能持续优化。
- 壁仞科技:通用GPU龙头,支持万亿参数模型训练推理。
- 海光信息:x86兼容CPU+DCU,国产替代核心力量。
(三)长周期AI应用(弹性最大)
- 核心逻辑:成本下降+上下文拉长,企业级Agent、知识管理、垂直行业解决方案率先落地。
- 受益标的:
- 科大讯飞:星火大模型+行业应用,深度适配国产算力。
- 拓尔思:企业级知识管理龙头,长文本处理能力领先。
- 汉得信息:ERP+AI Agent,助力企业流程自动化。
五、总结
DeepSeek V4不仅是模型迭代,更是国产AI产业链的“量子跃迁”——性能比肩国际、成本大幅下降、算力自主可控。高盛研报点明核心:模型内卷终局是底层算力与基础设施的胜利。暗线掘金聚焦算力基建、国产芯片适配、长周期AI应用,优先布局确定性强、弹性大的核心标的,把握国产算力替代与AI应用规模化双重红利。
以上信息仅供参考,不构成投资建议。