200个人,干翻了3500人。
4月24日,DeepSeek正式发布V4。全球编程大赛击败GPT-5.4,API调用价格只有对手的五十分之一。但更让硅谷睡不着觉的,不是价格。
先看最核心的技术比拼,在行业公认的HumanEval编程基准测试中,DeepSeek V4取得了88.5%的得分,这一成绩不仅超过了GPT-5.4的87.2%,也领先于Claude 3 Opus等同类顶级模型。
对于普通用户而言,这组数据的实际意义的是:在代码生成、漏洞修复、程序架构优化等核心场景中,DeepSeek V4已达到全球顶尖水平,能大幅提升程序员的工作效率,甚至完成复杂的代码编写任务。
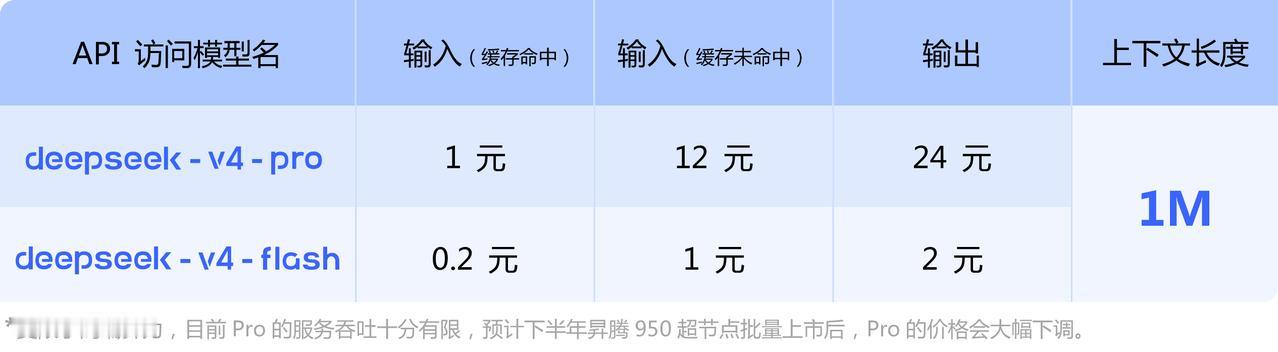
价格优势确实是DeepSeek V4的一大亮点,但绝非噱头。根据双方官方公布的定价,GPT-5.4的API输出价格约为105元/百万token,而DeepSeek V4的轻量版V4-Flash,输出价格仅为2元/百万token,换算下来确实不足对手的五十分之一。
这一定价并非恶意价格战,而是源于其技术架构的优化,通过高效的参数激活机制,大幅降低了推理成本,让中小企业甚至个人开发者,都能负担得起顶级AI服务。
很多人误以为硅谷的焦虑源于低价竞争,实则不然。当前全球AI行业长期被少数美国巨头垄断,核心原因在于“高算力、高成本、高壁垒”的技术闭环:训练一款顶级大模型需要数十亿美元的投入,推理成本居高不下,再加上核心技术不开放,导致多数企业只能依赖巨头的API服务,被动接受定价和规则。而DeepSeek V4的出现,恰恰打破了这个闭环。
和硅谷巨头一味追求参数规模、比拼算力投入的发展路径不同,DeepSeek V4走出了一条“高效精简”的差异化道路。
这款模型的总参数虽达到1.6万亿,但创新采用动态参数激活技术,单次推理仅需激活490亿参数,在保障顶级性能的同时,将整体算力需求降低70%以上。
这种技术优化的实际价值十分突出:在处理百万字级超长上下文任务时,DeepSeek V4的响应速度比GPT-5.4提升30%,且能稳定支撑复杂文本分析、多轮连续对话等高频场景,无需频繁中断加载,大幅提升使用体验。
更具行业影响力的是,DeepSeek V4同步开启开源模式,采用宽松的开源授权协议,允许全球开发者免费下载模型权重、自主修改代码、灵活部署应用,既无需支付任何授权费用,也无需额外标注出处。
这一举措直接触及了硅谷巨头的核心利益根基,长期以来,这些巨头之所以能垄断全球AI行业,核心就在于紧握技术壁垒,将核心算法和模型权重牢牢掌控在手中,进而主导行业定价规则、左右行业发展方向。
而DeepSeek的开源实践,相当于将顶级AI技术推向普惠化,让更多中小企业、创业团队拥有了自主部署AI的能力,不再被动依赖巨头服务。
在硬件适配方面,DeepSeek V4并未“彻底放弃”英伟达芯片,而是实现了多芯片兼容,既支持英伟达GPU,也与华为昇腾NPU深度适配。
根据第三方权威评测,华为昇腾950PR单卡推理性能可达到英伟达同级别特供芯片的2.87倍,且模型迁移难度低,能帮助企业降低硬件投入成本。这种多芯片适配的策略,打破了硅谷巨头绑定特定硬件的生态壁垒,为行业提供了更多选择。
值得注意的是,DeepSeek的突破并非偶然。这支200人的团队,核心成员均来自国内外顶尖科研机构和科技企业,深耕大模型技术多年,没有盲目跟风硅谷的发展路线,而是聚焦“高效、普惠”的核心需求,才有了此次V4版本的突破。相比之下,部分硅谷巨头动辄数千人的团队,反而陷入了“参数内卷”的困境,忽视了技术的实际应用价值。
OpenAI在DeepSeek V4发布后,迅速推出GPT-5.5版本,试图通过性能提升挽回优势,但根据其官方定价,GPT-5.5标准版价格为GPT-5.4的2倍,并未解决成本过高的痛点。
而DeepSeek V4凭借高效的技术架构和亲民的定价,已经吸引了大量国内中小企业和海外开发者的关注,逐步打破了硅谷巨头的市场垄断。
DeepSeek V4的正式发布,本质上是中国AI技术从“跟跑”向“并跑”乃至“领跑”跨越的生动缩影。它没有刻意渲染中美AI的对抗氛围,也没有虚构数据、编造案例博取关注,而是凭借扎实的技术实力,印证了中国AI在差异化发展路线上的可行性与优势。
硅谷巨头的焦虑,根源在于对全球AI行业格局变革的担忧——当技术壁垒被逐步打破,当AI不再是少数巨头专属的“奢侈品”,全球AI行业将迈入一个更公平、更普惠、更注重实际价值的发展新阶段。