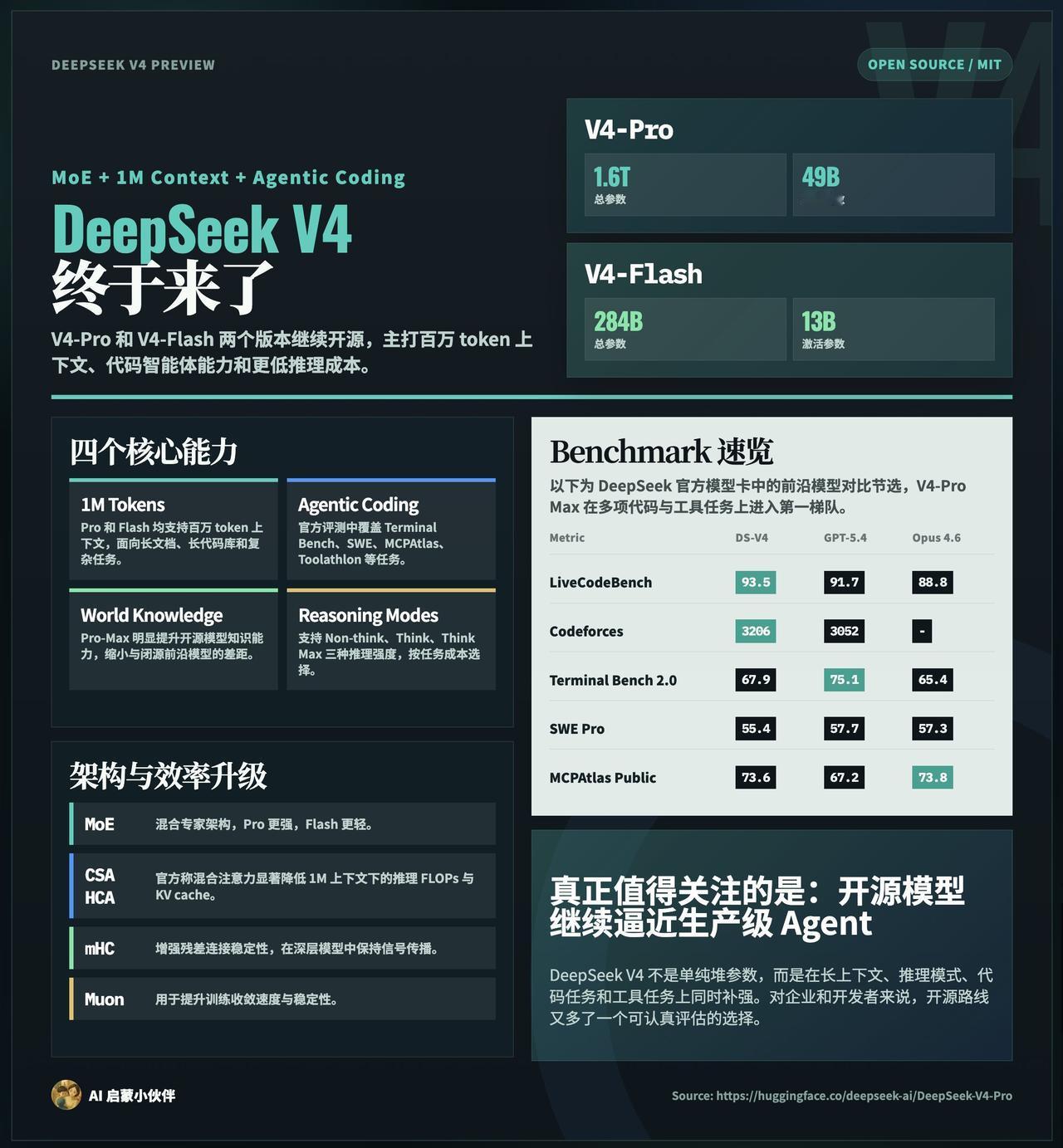
DeepSeek V4 终于来了,
V4-Pro 和 V4-Flash 两个版本,MoE 架构,全面适配华为昇腾 950PR,主打百万 token 超长上下文与Agent 能力,继续保持开源!
· V4-Pro:1.6T 参数、49B 激活,完整能力版,适合复杂任务
· V4-Flash:284B 参数,13B 激活,轻量版,兼顾速度与成本
核心能力
1. 长上下文:标准支持 1M tokens,通过全新的 DSA 稀疏注意力机制在 token 级别压缩数据,实现长上下文下的计算与内存效率双优化
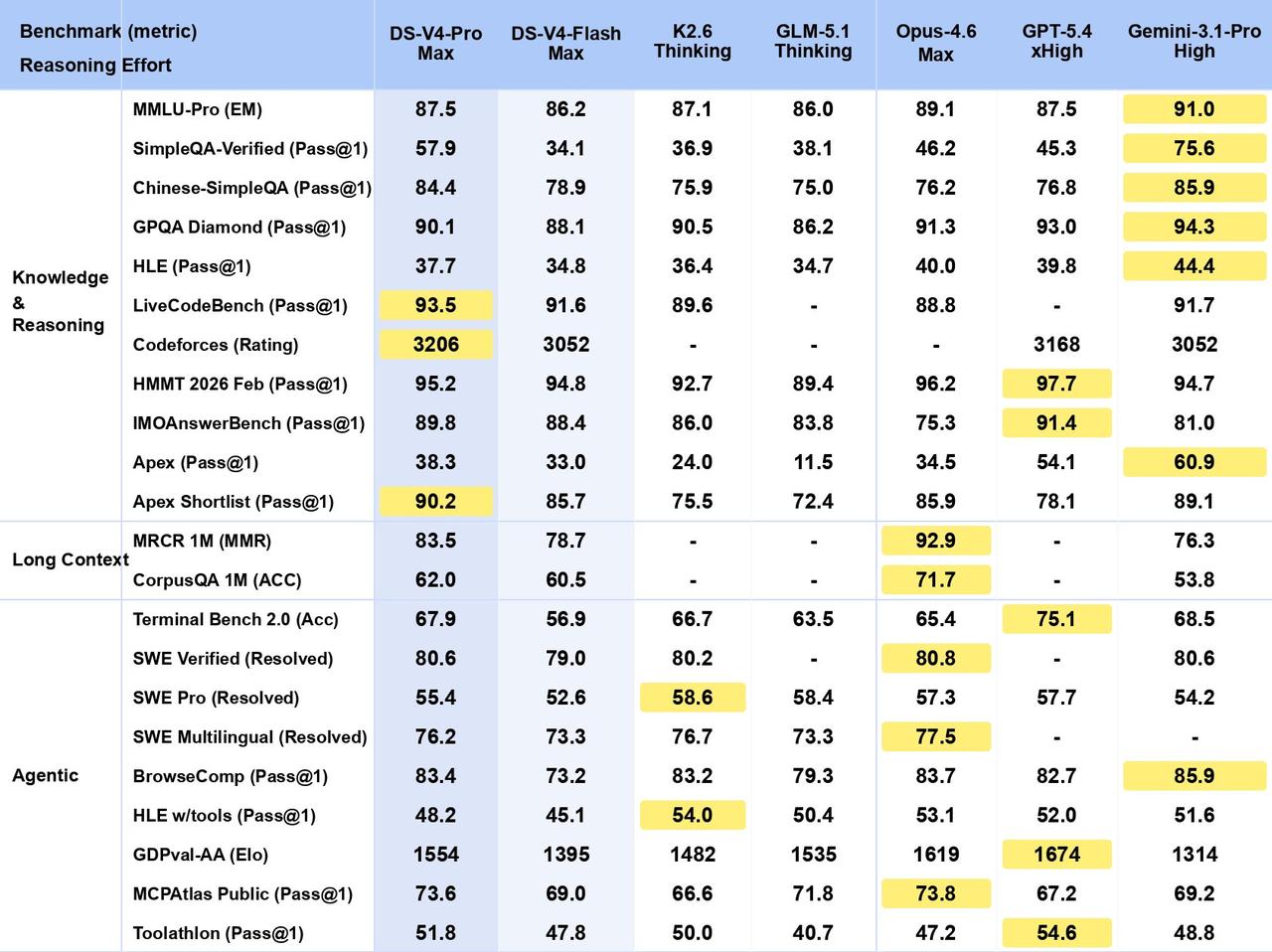
2. Agent 能力:在 Agentic Coding 评测中达到当前开源模型最佳水平。内部评测反馈:使用体验优于 Claude Sonnet 4.5,交付质量接近 Claude Opus 4.6(非思考模式),已作为 DeepSeek 内部员工的主力 Agentic Coding 模型
3. 世界知识:大幅领先其他开源模型,仅稍逊于顶尖闭源模型 Gemini-Pro-3.1
4. 推理性能:数学、STEM、竞赛型代码测评中超越所有已公开评测的开源模型,成绩比肩世界顶级闭源模型
架构与技术亮点
· MoE 架构:延续混合专家路线,总参数量级或达万亿级,激活参数控制在约 32B–37B,保持推理成本可控
· 稀疏注意力:DSA 机制使长上下文扩展的算力与内存开销显著低于传统方法
· 硬件适配:全面适配华为昇腾 950PR,并推出自研统一推理中间件 DSI,支持异构混合推理(NVIDIA / 昇腾 / 寒武纪),据称推理成本较上一代降低约 40%–55%
· Engram 记忆系统:条件式记忆架构,将静态知识检索与动态推理分离,有望支撑超长上下文记忆