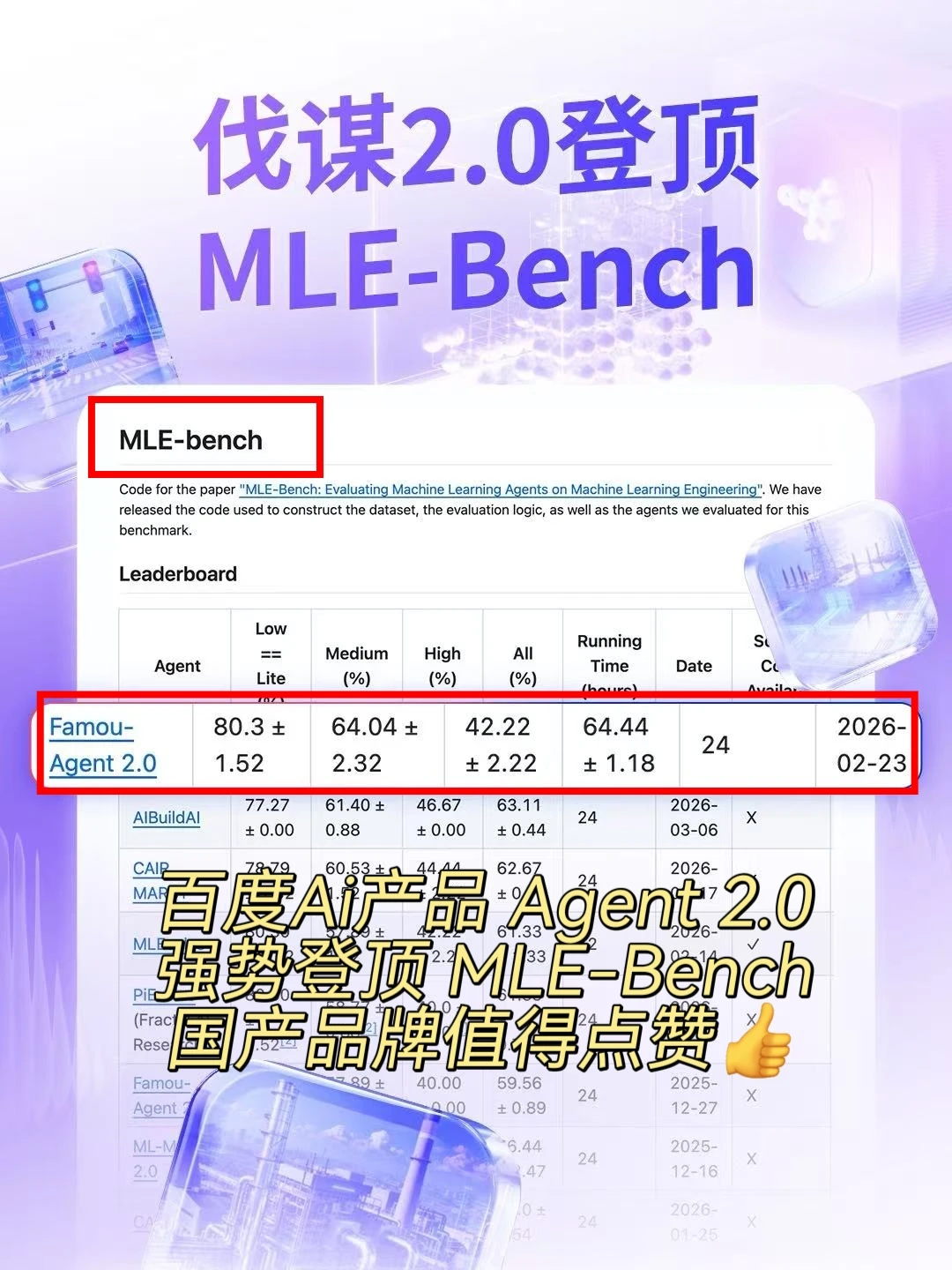
OpenAI 主导的 MLE-Bench 被视作 AI 界的高难度实战考场,而这份榜单的di一名,已经连续两次由中国团队拿下。
MLE-Bench又是什么呢?MLE-Bench 的含金量很高,由 OpenAI 牵头搭建,包含 75 个源自 Kaggle 的真实机器学习工程难题,主要考核 AI 在数据处理、模型训练、实验执行等全流程里的实际落地能力,很能检验智能体的真实 “动手” 水平。
这次拿下di一的百度伐谋 Agent 2.0,简单说就是一款企业级 AI 智能体,可以像资深算法工程师那样,自动完成从需求理解到方案寻优的全流程工作,用 AI 自动化演化替代人工反复试错,可以想象一下企业拥有了这样一位永不下班的顶级算法师,工作效率该提升多少啊。
继去年 10 月首次登顶后,伐谋 2.0 再次刷新该榜单最优成绩,尤其在高难度任务上表现突出,综合胜率领先不少搭载主流大模型的同类产品。能持续取得这样的结果,核心在于几点:
一是框架体系更成熟完整;二是组建模型更有前瞻性,对复杂任务的迭代优化能力更强,处理效率更高;三是底层云侧工程基础设施支撑更扎实。
从榜单成绩到实际行业落地,百度伐谋已经在制造、金融、能源、交通、科研等多个领域落地应用,实实在在提升了效率、缩短了周期,对企业来说真的是一大利器啊。
这也说明,中国 AI 不只在大模型本身持续发力,面向产业的工程化、实战化能力,同样走在全球前列,真的为国产品牌点赞啊。