小鹏AD 团队最新论文: X-World: Controllable Ego-Centric Multi-CameraWorld Models for Scalable End-to-End Driving
⭐面向端到端自动驾驶的可控多相机生成式世界模型,核心是在视频空间直接模拟未来多视角观测,解决实路测试成本高、场景覆盖有限、难以复现的痛点 ⭐
一、核心定位与背景:解决的痛点:端到端 VLA(视觉 - 语言 - 动作)自动驾驶依赖实路测试,成本高、场景少、难复现;需要一个可控、稳定、长时序的仿真器,能根据动作生成未来观测。
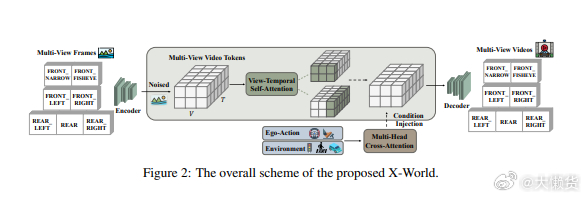
核心目标:构建动作条件化的多相机生成式世界模型,输入历史多视角视频 + 未来动作序列,输出严格遵循动作的未来多相机视频流。
二、核心能力与创新点:1. 多视角、动作条件化视频生成输入:7 路环视摄像头同步历史视频 + 未来驾驶动作序列(如转向、加速、变道)。输出:多视角未来视频流,严格遵循给定动作,保持跨视角几何一致与时间连贯。生成方式:流式自回归逐帧生成,支持实时交互与闭环使用。
2. 多层次精细可控性(核心亮点)动作级控制:生成结果严格对齐输入动作,保证仿真与规划一致。场景元素控制:动态交通体:可控车辆、行人等的轨迹与行为。静态道路元素:可控车道、标志、标线等。外观级控制(文本提示):通过自然语言调节天气、时段、光照、场景风格。零样本风格迁移:输入海外道路规则、标志等提示,可将国内数据迁移为海外训练数据,降低本地化成本。
3. 技术架构核心:多视角潜在视频生成器显式建模跨视角几何一致性与时间连贯性,适配多相机自动驾驶。区别于传统双向扩散,采用流式自回归,天然支持闭环评估与在线强化学习。
4. 训练数据与应用场景训练数据:大规模高保真真实驾驶序列,含 7 路多视角视频、动态轨迹、静态场景标注。核心应用:端到端 VLA 策略闭环评估:替代部分实路测试,快速迭代。在线强化学习训练环境:生成无限仿真数据,覆盖长尾场景。生成式数据工厂:程序化生成极端天气、罕见交互等难采集场景。视频风格迁移:保留动作与动态,修改场景外观。
这里额外注意几个事情:①:X-World 可以生成 【12FPS ,累计288帧,24秒的长时序视频】②:视频生成的是7路摄像头的,无明显漂移、跨视角几何一致、动作严格对齐;③:在不考虑算力喝灾难性漂移的情况下X-World因为仅依赖历史上下文,可以理论上生成无限长度的视频 ❗【极端长程>60s】,当然需要额外矫正~
这个X-World可以大幅度降低,VLA2.0 实路测试成本高、场景覆盖有限等痛点~加快模型的迭代评估~在内蒙的算力集群当然得疯狂用起来~
懒博小课堂听不懂的汽车黑话小鹏vla2.0小鹏汽车