IT之家3月23日消息,拥有4000亿参数的大语言模型只能在配备大容量内存、性能强劲的硬件上运行,因为即使是量化或压缩版本,也至少需要200GB内存。从这些苛刻的配置要求来看,iPhone17Pro绝对不会是运行4000亿参数大模型的首选,但有人已经证明,苹果这一代旗舰机型完成了这件看似不可能的事。不过IT之家需要说明的是,这离不开一些巧妙的技术手段。

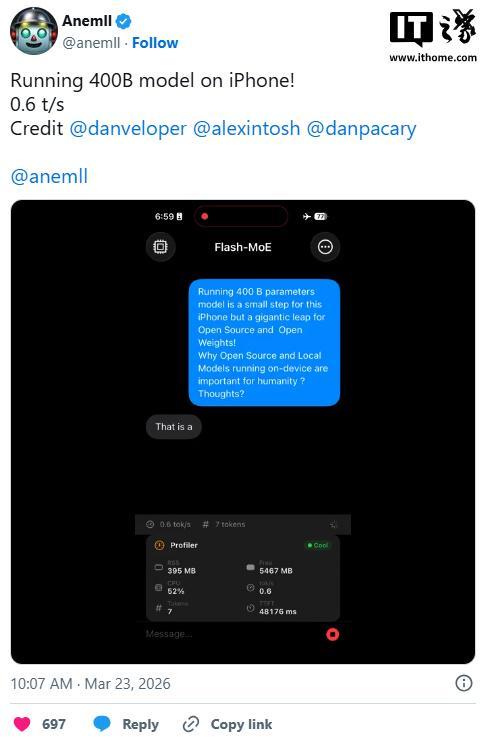
一个名为Flash‑MoE的开源项目已在iPhone17Pro上成功运行,据网友@anemll展示,这款旗舰机虽然能运行这个算力需求极高的模型,但也存在明显短板,其Token生成速度慢得惊人,仅0.6个Token/秒,大约每1.5到2秒才能生成一个单词。
不过话又说回来,无论速度如何,一部智能手机能跑起来4000亿参数的大语言模型,这一事实本身就说明:只要再做一些优化,未来在手机端本地运行大语言模型完全是有可能实现的。
至于实现原理:iPhone17Pro仅配备12GBLPDDR5X内存,根本不可能把整个大模型全部载入内存,而Flash‑MoE则利用了设备的固态硬盘(SSD),直接向GPU流式传输数据。此外,“MoE”代表混合专家模型(MixtureofExperts),这意味着其每生成一个单词,只需要调用4000亿参数中的一小部分。
在本地运行大语言模型还有一个好处:完全保护隐私,且无需联网就能获得回复,只不过iPhone17Pro的电池会被严重消耗。开发者们也会使用大语言模型的压缩版,也就是“量化版”,但即便是量化后的4000亿参数模型,最低仍需200GB内存,这在iPhone17Pro上原本是无法实现的。
简而言之,这次最新演示证明:只要你能忍受每秒仅0.6个Token的缓慢生成过程,就可以在智能手机上运行4000亿参数的大语言模型。但也要清楚,“能跑起来”和“能流畅、可用地使用”完全是两码事。